1抓取网页
网络爬虫的基本操作是抓取网页。那么如何才能随心所欲地获得自己想要的页面?这一节将从URL开始讲起,然后告诉大家如何抓取网页,并给出一个使用Java语言抓取网页的例子。最后,要讲一讲抓取过程中的一个重要问题:如何处理HTTP状态码。
1.1.1 深入理解URL
抓取网页的过程其实和读者平时使用IE浏览器浏览网页的道理是一样的。比如,你打开一个浏览器,输入猎兔搜索网站的地址,如图1.1所示。
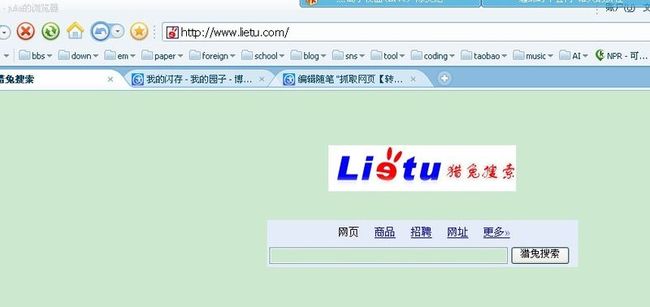
图1.1 使用浏览器浏览网页
“打开”网页的过程其实就是浏览器作为一个浏览的“客户端”,向服务器端发送了一次请求,把服务器端的文件“抓”到本地,再进行解释、展现。更进一步,可以通过浏览器端查看“抓取”过来的文件源代码。选择“查看”|“源文件”命令,就会出现从服务器上“抓取”下来的文件的源代码,如图1.2所示。
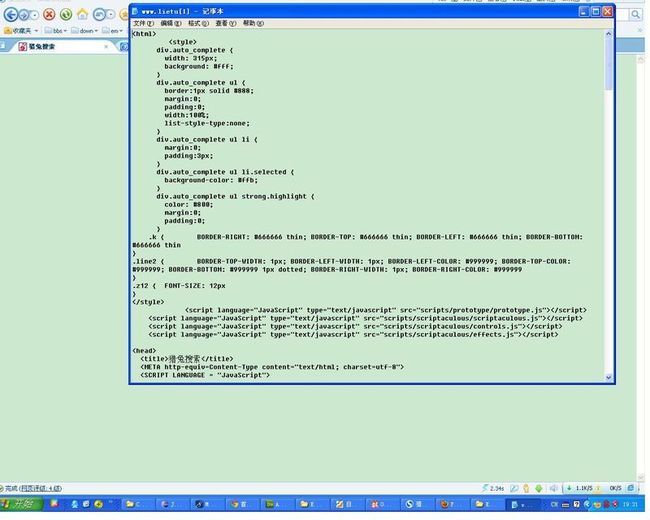
图1.2 浏览器端源代码
在上面的例子中,我们在浏览器的地址栏中输入的字符串叫做URL。那么,什么是URL呢?直观地讲,URL就是在浏览器端输入的http://www.lietu.com这个字符串。下面我们深入介绍有关URL的知识。
在理解URL之前,首先要理解URI的概念。什么是URI?Web上每种可用的资源,如HTML文档、图像、视频片段、程序等都由一个通用资源标志符(UniversalResourceIdentifier,URI)进行定位。
URI通常由三部分组成:①访问资源的命名机制;②存放资源的主机名;③资源自身的名称,由路径表示。如下面的URI:http://www.webmonkey.com.cn/html/html40/
我们可以这样解释它:这是一个可以通过HTTP协议访问的资源,位于主机www.webmonkey.com.cn上,通过路径“/html/html40”访问。
URL是URI的一个子集。它是UniformResourceLocator的缩写,译为“统一资源定位符”。通俗地说,URL是Internet上描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL的格式由三部分组成:
�第一部分是协议(或称为服务方式)。
�第二部分是存有该资源的主机IP地址(有时也包括端口号)。
�第三部分是主机资源的具体地址,如目录和文件名等。
第一部分和第二部分用“://”符号隔开,第二部分和第三部分用“/”符号隔开。第一部分和第二部分是不可缺少的,第三部分有时可以省略。
根据URL的定义,我们给出了常用的两种URL协议的例子,供大家参考。
1.HTTP协议的URL示例
使用超级文本传输协议HTTP,提供超级文本信息服务的资源。例:http://www.peopledaily.com.cn/channel/welcome.htm
其计算机域名为www.peopledaily.com.cn。超级文本文件(文件类型为.html)是在目录/channel下的welcome.htm。这是中国人民日报的一台计算机。
例:http://www.rol.cn.net/talk/talk1.htm
其计算机域名为www.rol.cn.net。超级文本文件(文件类型为.html)是在目录/talk下的talk1.htm。这是瑞得聊天室的地址,可由此进入瑞得聊天室的第1室。
2.文件的URL
用URL表示文件时,服务器方式用file表示,后面要有主机IP地址、文件的存取路径(即目录)和文件名等信息。有时可以省略目录和文件名,但“/”符号不能省略。例:file://ftp.yoyodyne.com/pub/files/foobar.txt
上面这个URL代表存放在主机ftp.yoyodyne.com上的pub/files/目录下的一个文件,文件名是foobar.txt。例:file://ftp.yoyodyne.com/pub
代表主机ftp.yoyodyne.com上的目录/pub。例:file://ftp.yoyodyne.com/
代表主机ftp.yoyodyne.com的根目录。
爬虫最主要的处理对象就是URL,它根据URL地址取得所需要的文件内容,然后对它进行进一步的处理。因此,准确地理解URL对理解网络爬虫至关重要。从下一节开始,我们将详细地讲述如何根据URL地址来获得网页内容。
1.1.2 通过指定的URL抓取网页内容
上一节详细介绍了URL的构成,这一节主要阐述如何根据给定的URL来抓取网页。
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的内容发送到服务器端,然后读取服务器端的响应资源。
Java语言是为网络而生的编程语言,它把网络资源看成是一种文件,它对网络资源的访问和对本地文件的访问一样方便。它把请求和响应封装为流。因此我们可以根据相应内容,获得响应流,之后从流中按字节读取数据。例如,java.net.URL类可以对相应的Web服务器发出请求并且获得响应文档。java.net.URL类有一个默认的构造函数,使用URL地址作为参数,构造URL对象:
URLpageURL=newURL(path);
接着,可以通过获得的URL对象来取得网络流,进而像操作本地文件一样来操作网络资源:
InputStreamstream=pageURL.openStream();
在实际的项目中,网络环境比较复杂,因此,只用java.net包中的API来模拟IE客户端的工作,代码量非常大。需要处理HTTP返回的状态码,设置HTTP代理,处理HTTPS协议等工作。为了便于应用程序的开发,实际开发时常常使用Apache的HTTP客户端开源项目——HttpClient。它完全能够处理HTTP连接中的各种问题,使用起来非常方便。只需在项目中引入HttpClient.jar包,就可以模拟IE来获取网页内容。例如:
//创建一个客户端,类似于打开一个浏览器 HttpClienthttpclient=newHttpClient(); //创建一个get方法,类似于在浏览器地址栏中输入一个地址 GetMethodgetMethod=newGetMethod("http://www.blablabla.com"); //回车,获得响应状态码 intstatusCode=httpclient.executeMethod(getMethod); //查看命中情况,可以获得的东西还有很多,比如head、cookies等 System.out.println("response="+getMethod.getResponseBodyAsString()); //释放 getMethod.releaseConnection();
上面的示例代码是使用HttpClient进行请求与响应的例子。第一行表示创建一个客户端,相当于打开浏览器。第二行使用get方式对http://www.blablabla.com进行请求。第三行执行请求,获取响应状态。第四行的getMethod.getResponseBodyAsString()方法能够以字符串方式获取返回的内容。这也是网页抓取所需要的内容。在这个示例中,只是简单地把返回的内容打印出来,而在实际项目中,通常需要把返回的内容写入本地文件并保存。最后还要关闭网络连接,以免造成资源消耗。
这个例子是用get方式来访问Web资源。通常,get请求方式把需要传递给服务器的参数作为URL的一部分传递给服务器。但是,HTTP协议本身对URL字符串长度有所限制。因此不能传递过多的参数给服务器。为了避免这种问题,通常情况下,采用post方法进行HTTP请求,HttpClient包对post方法也有很好的支持。例如:
//得到post方法 PostMethodPostMethod=newPostMethod("http://www.saybot.com/postme"); //使用数组来传递参数 NameValuePair[]postData=newNameValuePair[2]; //设置参数 postData[0]=newNameValuePair("武器","枪"); postData[1]=newNameValuePair("什么枪","神枪"); postMethod.addParameters(postData); //回车,获得响应状态码 intstatusCode=httpclient.executeMethod(getMethod); //查看命中情况,可以获得的东西还有很多,比如head、cookies等 System.out.println("response="+getMethod.getResponseBodyAsString()); //释放 getMethod.releaseConnection();
上面的例子说明了如何使用post方法来访问Web资源。与get方法不同,post方法可以使用NameValuePair来设置参数,因此可以设置“无限”多的参数。而get方法采用把参数写在URL里面的方式,由于URL有长度限制,因此传递参数的长度会有限制。
有时,我们执行爬虫程序的机器不能直接访问Web资源,而是需要通过HTTP代理服务器去访问,HttpClient对代理服务器也有很好的支持。如:
//创建HttpClient相当于打开一个代理 HttpClienthttpClient=newHttpClient(); //设置代理服务器的IP地址和端口 httpClient.getHostConfiguration().setProxy("192.168.0.1",9527); //告诉httpClient,使用抢先认证,否则你会收到“你没有资格”的恶果 httpClient.getParams().setAuthenticationPreemptive(true); //MyProxyCredentialsProvder返回代理的credential(username/password) httpClient.getParams().setParameter(CredentialsProvider.PROVIDER, newMyProxyCredentialsProvider()); //设置代理服务器的用户名和密码 httpClient.getState().setProxyCredentials(newAuthScope("192.168.0.1", AuthScope.ANY_PORT,AuthScope.ANY_REALM), newUsernamePasswordCredentials("username","password"));
上面的例子详细解释了如何使用HttpClient设置代理服务器。如果你所在的局域网访问Web资源需要代理服务器的话,你可以参照上面的代码设置。
这一节,我们介绍了使用HttpClient抓取网页的内容,之后,我们将给出一个详细的例子来说明如何获取网页。
1.1.3 Java网页抓取示例
在这一节中,我们根据之前讲过的内容,写一个实际的网页抓取的例子。这个例子把上一节讲的内容做了一定的总结,代码如下:
publicclassRetrivePage{ privatestaticHttpClienthttpClient=newHttpClient(); //设置代理服务器 static{ //设置代理服务器的IP地址和端口 httpClient.getHostConfiguration().setProxy("172.17.18.84",8080); } publicstaticbooleandownloadPage(Stringpath)throwsHttpException, IOException{ InputStreaminput=null; OutputStreamoutput=null; //得到post方法 PostMethodpostMethod=newPostMethod(path); //设置post方法的参数 NameValuePair[]postData=newNameValuePair[2];postData[0]=new NameValuePair("name","lietu");postData[1]=new NameValuePair("password","*****"); postMethod.addParameters(postData); //执行,返回状态码 intstatusCode=httpClient.executeMethod(postMethod); //针对状态码进行处理(简单起见,只处理返回值为200的状态码) if(statusCode==HttpStatus.SC_OK){ input=postMethod.getResponseBodyAsStream(); //得到文件名 Stringfilename=path.substring(path.lastIndexOf('/')+1); //获得文件输出流 output=newFileOutputStream(filename); //输出到文件 inttempByte=-1; while((tempByte=input.read())>0){ output.write(tempByte); } //关闭输入输出流 if(input!=null){ input.close(); } if(output!=null){ output.close(); } returntrue; } returnfalse; } /** *测试代码 */ publicstaticvoidmain(String[]args){ //抓取lietu首页,输出 try{ RetrivePage.downloadPage("http://www.lietu.com/"); }catch(HttpExceptione){ //TODOAuto-generatedcatchblock e.printStackTrace(); }catch(IOExceptione){ //TODOAuto-generatedcatchblock e.printStackTrace(); } } }
上面的例子是抓取猎兔搜索主页的示例。它是一个比较简单的网页抓取示例,由于互联网的复杂性,真正的网页抓取程序会考虑非常多的问题。比如,资源名的问题,资源类型的问题,状态码的问题。而其中最重要的就是针对各种返回的状态码的处理。下一节将重点介绍处理状态码的问题。
1.1.4 处理HTTP状态码
上一节介绍HttpClient访问Web资源的时候,涉及HTTP状态码。比如下面这条语句:
intstatusCode=httpClient.executeMethod(getMethod);//回车,获得响应状态码
HTTP状态码表示HTTP协议所返回的响应的状态。比如客户端向服务器发送请求,如果成功地获得请求的资源,则返回的状态码为200,表示响应成功。如果请求的资源不存在,则通常返回404错误。
HTTP状态码通常分为5种类型,分别以1~5五个数字开头,由3位整数组成。1XX通常用作实验用途。这一节主要介绍2XX、3XX、4XX、5XX等常用的几种状态码,如表1.1所示。
| 状态代码 | 代码描述 | 处理方式 |
| 200 | 请求成功 | 获得响应的内容,进行处理 |
| 201 | 请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 | 爬虫中不会遇到 |
| 202 | 请求被接受,但处理尚未完成 | 阻塞等待 |
| 204 | 服务器端已经实现了请求,但是没有返回新的信息。如果客户是用户代理,则无须为此更新自身的文档视图 | 丢弃 |
| 300 | 该状态码不被HTTP/1.0的应用程序直接使用,只是作为3XX类型回应的默认解释。存在多个可用的被请求资源 | 若程序中能够处理,则进行进一步处 理,如果程序中不能处理,则丢弃 |
| 301 | 请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 | 重定向到分配的URL |
| 302 | 请求到的资源在一个不同的URL处临时保存 | 重定向到临时的URL |
| 304 | 请求的资源为更新 | 丢弃 |
| 400 | 非法请求 | 丢弃 |
| 401 | 未授权 | 丢弃 |
| 403 | 禁止 | 丢弃 |
| 404 | 没有找到 | 丢弃 |
| 5XX | 回应代码以“5”开头的状态码表示服务器端发现自己出现错误,不能继续执行请求 | 丢弃 |
当返回的状态码为5XX时,表示应用服务器出现错误,采用简单的丢弃处理就可以解决。
当返回值状态码为3XX时,通常进行转向,以下是转向的代码片段,读者可以和上一节的代码自行整合到一起:
//若需要转向,则进行转向操作 if((statusCode==HttpStatus.SC_MOVED_TEMPORARILY)||(statusCode== HttpStatus.SC_MOVED_PERMANENTLY)||(statusCode==HttpStatus.SC_SEE_OTHER) ||(statusCode==HttpStatus.SC_TEMPORARY_REDIRECT)){ //读取新的URL地址 Headerheader=postMethod.getResponseHeader("location"); if(header!=null){ StringnewUrl=header.getValue(); if(newUrl==null||newUrl.equals("")){ newUrl="/"; //使用post转向 PostMethodredirect=newPostMethod(newUrl); //发送请求,做进一步处理…… } } }
当响应状态码为2XX时,根据表1.1的描述,我们只需要处理200和202两种状态码,其他的返回值可以不做进一步处理。200的返回状态码是成功状态码,可以直接进行网页抓取,例如:
//处理返回值为200的状态码 if(statusCode==HttpStatus.SC_OK){ input=postMethod.getResponseBodyAsStream(); //得到文件名 Stringfilename=path.substring(path.lastIndexOf('/')+1); //获得文件输出流 output=newFileOutputStream(filename); //输出到文件 inttempByte=-1; while((tempByte=input.read())>0){ output.write(tempByte); } }
202的响应状态码表示请求已经接受,服务器再做进一步处理。