Cowboy 源码分析(十一)
上一篇,我们使用debugger和HttpFox很方便了,查看了方法中的变量,不得不说,debugger 断点调试还是比较好用的。这一篇,我们仍将使用这些工具来帮助我们了解代码,好了,接着上一篇继续来看 cowboy_http_protocol:request/2 方法:
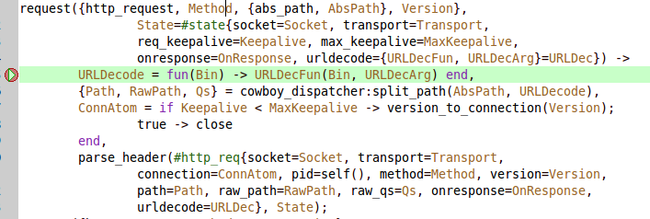
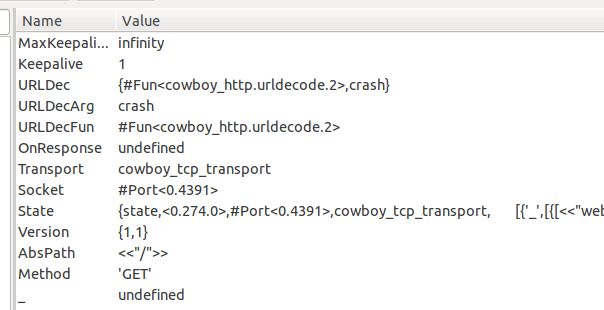
上面两张图,是我们上一篇文章,我们看到的函数,以及变量的值,这一篇,我们继续来看下这个函数:
URLDecode = fun(Bin) -> URLDecFun(Bin, URLDecArg) end,定义了一个匿名函数,Bin是匿名函数定义的变量,我们看下 URLDecFun 这个变量,
urldecode={URLDecFun, URLDecArg}=URLDec
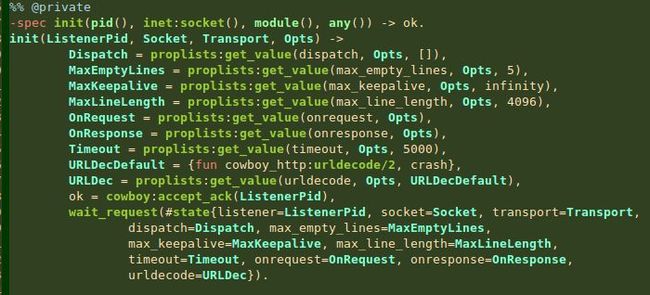
还记得 #state{} 在 cowboy_http_protocol:init/4 方法中,urldecode 的定义吗?我截了个图,方便大家回忆,从下面图,我们可以很清楚看到 urldecode 的值:
那么 urldecode={URLDecFun, URLDecArg}=URLDec 自然就是 urldecode={fun cowboy_http:urldecode/2, crash}=URLDec。
弄明白了这几个参数,我们继续往下看:
{Path, RawPath, Qs} = cowboy_dispatcher:split_path(AbsPath, URLDecode), 看下 cowboy_dispatcher:split_path/2 这个函数:
%% @doc Split a path into a list of path segments. %% %% Following RFC2396, this function may return path segments containing any %% character, including <em>/</em> if, and only if, a <em>/</em> was escaped %% and part of a path segment. -spec split_path(binary(), fun((binary()) -> binary())) -> {tokens(), binary(), binary()}. split_path(Path, URLDec) -> case binary:split(Path, <<"?">>) of [Path] -> {do_split_path(Path, <<"/">>, URLDec), Path, <<>>}; [<<>>, Qs] -> {[], <<>>, Qs}; [Path2, Qs] -> {do_split_path(Path2, <<"/">>, URLDec), Path2, Qs} end. -spec do_split_path(binary(), <<_:8>>, fun((binary()) -> binary())) -> tokens(). do_split_path(RawPath, Separator, URLDec) -> EncodedPath = case binary:split(RawPath, Separator, [global, trim]) of [<<>>|Path] -> Path; Path -> Path end, [URLDec(Token) || Token <- EncodedPath].
函数的注释意思为:分割路径中的参数成为一个列表。我们看下 case binary:split(Path, <<"?">>) of 这行,这个函数第一次遇到,同样查下erlang doc:http://www.erlang.org/doc/man/binary.html#split-2 比较简单,就是按照第二个参数,分割第一个参数,返回分割后的列表。在这里 Path = <<"/">> ,那么分割后为 [<<"/">>]。
往下看 cowboy_dispatcher:do_split_path/3 这个函数,同样用到了 binary:split/3 函数,只不过这次是三个参数,如果你认真看了上面我给出的 erlang doc 链接,你应该能知道 binary:split/2 其实调用了 binary:split/3,只不过最后一个参数是 []。那么我们看下这次出现的第三个参数是什么意思呢?下面是erlang doc 给出的说明:
- trim
-
Removes trailing empty parts of the result (as does trim in re:split/3)
移除结果中尾部为空的部分。
- global
-
Repeats the split until the Subject is exhausted. Conceptually the global option makes split work on the positions returned by matches/3, while it normally works on the position returned by match/3.
重复分隔直到不能按Pattern项分割Subject。
好了,弄清楚这2个参数的意思,我们就知道结果:
EncodedPath = case binary:split(RawPath, Separator, [global, trim]) of
EncodedPath = case binary:split(<<"/">>, <<"/">>, [global, trim]) of
EncodedPath = []
接下来看下:[URLDec(Token) || Token <- EncodedPath]. 这里是一个列表解析,URLDec = URLDecode = fun(Bin) -> URLDecFun(Bin, URLDecArg) end.
这里依次对 EncodedPath列表中的元素,依次调用 URLDec(Token),然后返回每个调用后的结果组成的列表。
这边我把 cowboy_http:urldecode/2 方法贴下下面,我并不打算去解释这个方法,大家详细看下,其实这个方法很简单,就是对 URL 中的参数解码:
%% @doc Decode a URL encoded binary. %% @equiv urldecode(Bin, crash) -spec urldecode(binary()) -> binary(). urldecode(Bin) when is_binary(Bin) -> urldecode(Bin, <<>>, crash). %% @doc Decode a URL encoded binary. %% The second argument specifies how to handle percent characters that are not %% followed by two valid hex characters. Use `skip' to ignore such errors, %% if `crash' is used the function will fail with the reason `badarg'. -spec urldecode(binary(), crash | skip) -> binary(). urldecode(Bin, OnError) when is_binary(Bin) -> urldecode(Bin, <<>>, OnError). -spec urldecode(binary(), binary(), crash | skip) -> binary(). urldecode(<<$%, H, L, Rest/binary>>, Acc, OnError) -> G = unhex(H), M = unhex(L), if G =:= error; M =:= error -> case OnError of skip -> ok; crash -> erlang:error(badarg) end, urldecode(<<H, L, Rest/binary>>, <<Acc/binary, $%>>, OnError); true -> urldecode(Rest, <<Acc/binary, (G bsl 4 bor M)>>, OnError) end; urldecode(<<$%, Rest/binary>>, Acc, OnError) -> case OnError of skip -> ok; crash -> erlang:error(badarg) end, urldecode(Rest, <<Acc/binary, $%>>, OnError); urldecode(<<$+, Rest/binary>>, Acc, OnError) -> urldecode(Rest, <<Acc/binary, $ >>, OnError); urldecode(<<C, Rest/binary>>, Acc, OnError) -> urldecode(Rest, <<Acc/binary, C>>, OnError); urldecode(<<>>, Acc, _OnError) -> Acc.
又跑了老远,回到 cowboy_dispatcher:split_path/2,最后返回 {[], <<"/">>, <<>>};
接着,我们回到 cowboy_http_protocol:request/2 方法,看下这一行:
{Path, RawPath, Qs} = cowboy_dispatcher:split_path(AbsPath, URLDecode), 可以得到下面几个参数的值为:
Qs = <<>>
Path = []
RawPath = <<"/">>
继续往下:
ConnAtom =
if Keepalive < MaxKeepalive ->
version_to_connection(Version);
true -> close
end,
下面是 cowboy_http_protocol:version_to_connection/1 函数:
-spec version_to_connection(cowboy_http:version()) -> keepalive | close. version_to_connection({1, 1}) -> keepalive; version_to_connection(_Any) -> close.
这段代码主要是判断 同时和服务器保持连接。而我们看下 HTTP 关于Keep-Alive的介绍:使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。如果暂时不理解,没关系,先跳过,以后我还会回过头来整体介绍。
再往下:
parse_header(#http_req{socket=Socket, transport=Transport, connection=ConnAtom, pid=self(), method=Method, version=Version, path='*', raw_path= <<"*">>, raw_qs= <<>>, onresponse=OnResponse, urldecode=URLDec}, State);
这行是解析 HTTP 头部,我们将在下一篇继续和大家分享接下来的代码,谢谢大家支持。