图解缓存淘汰算法二之LFU
1.概念分析
LFU(Least Frequently Used)即最近最不常用.从名字上来分析,这是一个基于访问频率的算法.与LRU不同,LRU是基于时间的,会将时间上最不常访问的数据淘汰;LFU为将频率上最不常访问的数据淘汰.既然是基于频率的,就需要有存储每个数据访问的次数.从存储空间上,较LRU会多出一些持有计数的空间.
那么LFU算法的主导思想是什么呢?LFU算法认为"如果数据过去访问频率很高,那么将来被访问的频率也很高".好吧,我知道这又是个伪命题,不过所有的可实现的淘汰算法,都是基于对过去数据认识来推断未来的发展,这跟天气预报是一个思路(当然,天气预报要复杂的多).将来的事情哪能说的准,根据过去的情况来推断将来.好了,不罗嗦了.
2.原理分析
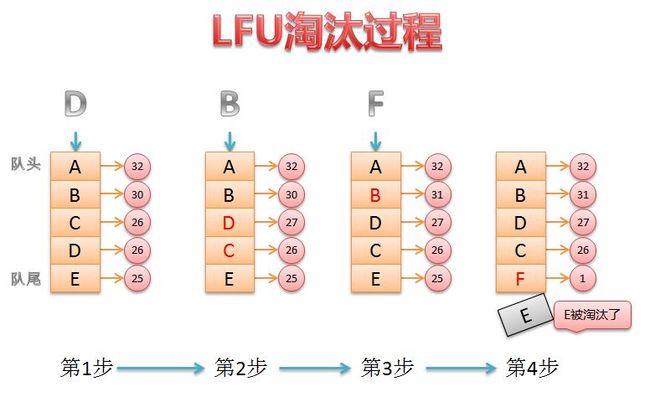
下面简单讲解一下:
- 当缓存池已经满了,此时访问D,D的访问频率为26;
- 访问D后,D的频率+1,此时需要调整缓存池数据需要重新排序,D和C交换;
- 访问B,B的频率+1,由于A的频率仍然比B大,所以不需要调整;
- 新数据F插入缓存池之前,由于E的频率最低,故淘汰E,将F插入缓存池,缓存池重新排序,F放到队尾.
当然,这只是一个简单的模型图,实现方式很多,也可以不需要缓存池重新排序.
3.优略分析
【命中率】
命中率比LRU较高,能够避免周期性或偶发性的情况对LRU的命中影响,但是,一旦访问内容发生较大变化,LFU需要用更长的时间来适应(历史的频率记录会是这些污染数据保持较长的一段时间)
【复杂度】
需要维护所有的访问记录的频率数据结构,实现较LRU复杂.
【存储成本】
需要维护所有的访问记录的频率数据结构.
【缺陷】
仅仅从最近访问频率上考虑淘汰算法,可能会淘汰一些仍有价值的单元.内存和性能消耗较高.
4.实现
暂时略,以后会采用伪代码和java语言的方式做简单的实现.
最后,如有哪里不正确的地方,请多多指教. 后续会将其他缓存淘汰算法一一介绍,敬请期待.
相关文章: