从零起步搭建Hadoop单机和伪分布式开发环境图文教程
从零起步搭建Hadoop单机和伪分布式开发环境图文教程
工欲善其事,必先利其器。
本文从零起步构建Hadoop单机版本和伪分布式的开发环境,图文并茂,不放过任何一个细节,涉及:
1,开发Hadoop需要的基本软件;
2, 安装每个软件;
3, 配置Hadoop单机模式并运行Wordcount示例;
4, 配置Hadoop伪分布式模式并运行Wordcount示例;
更多Hadoop交流可以联系家林:
新浪微博:http://weibo.com/ilovepains
QQ:1740415547
QQ群:312494188
Weixin:wangjialinandroid
官方博客:http://www.cnblogs.com/guoshiandroid/
此教程来自于王家林免费发布“云计算分布式大数据Hadoop实战高手之路---从零开始”的第二讲Hadoop图文训练课程:全球最详细的从零起步搭建Hadoop单机和伪分布式开发环境图文教程(长达88页的PDF,不放过任何一个细节),全部免费教材为:云计算分布式大数据Hadoop实战高手之路(共3本书):
1,王家林编写的“云计算分布式大数据Hadoop实战高手之路---从零开始”带领您无痛入门Hadoop并能够处理Hadoop工程师的日常编程工作,进入云计算大数据的美好世界。
2, 王家林编写的“云计算分布式大数据Hadoop实战高手之路---高手崛起”通过数个案例实战和Hadoop高级主题的动手操作带领您直达Hadoop高手境界。
3, 王家林编写的“云计算分布式大数据Hadoop实战高手之路---高手之巅”通过当今主流的Hadoop商业使用方法和最成功的Hadoop大型案例让您直达高手之巅,从此一览众山小。
转载请注明出处。
查看教程:全球最详细的从零起步搭建Hadoop单机和伪分布式开发环境图文教程
PDF教程下载地址:http://pan.baidu.com/share/link?shareid=223236637&uk=4013289088
家林会带您在10分钟内理解云计算分布式大数据处理框架Hadoop并开始动手实践,倒计时开始……
更多Hadoop交流可以联系家林:
新浪微博:http://weibo.com/ilovepains
QQ:1740415547
QQ群:312494188
Weixin:wangjialinandroid
官方博客:http://www.cnblogs.com/guoshiandroid/
第1分钟:
Hadoop要解决的问题是什么?
答:Hadoop核心要解决长期IT界乃至人类社会的两大主题:
1, 海量数据的存储:传统的存储方式昂贵而且日益难以满足核裂变级别数据的增长,例如纽约证券交易所每天要产生T级别的数据量,Facebook要每天要服务过亿的用户(其中图片等数据`量是惊人的),如何使用廉价的设备支持无线增长的数据的安全高效的存储,Hadoop提出了解决方案,即HDFS.
2, 海量数据的分析:如何有效而快速的从海量数据中提取出有价值的信息,Hadoop给出了解决方案,即MapReduce.
HDFS和MapReduce是Hadoop整个项目的基础和核心,Hadoop庞大的家族中的其它子项目都是基于HDFS和MapReduce,所以掌握HDFS和MapReduce也就掌握了Hadoop的核心。
第2分钟:
Hadoop的来源和发展历史是什么?
答:始于2002年Apache搜索引擎项目Nutch,2004年Nutch的开发者基于Google发表的著名的GFS论文开发出了开源版本的GFS即NDFS,2005年基于Google发表的著名的MapReduce论文把MapReduce引入NDFS,2006年改名为Hadoop,NDFS的创始人加入Yahoo,同时Yahoo成立专门的小组发展Hadoop。
可以看出,在Hadoop的发展过程中,除了其创始人外,Google和Yahoo居功至伟。
第3分钟:
Hadoop到底是什么?
答:Hadoop是基于廉价设备利用集群的威力对海量数据进行安全存储和高效计算的分布式存储和分析框架,Hadoop本身是一个庞大的项目家族,其核心家族或者底层是HDFS和MapReduce,HDFS和MapReduce分别用来实现对海量数据的存储和分析,其它的项目,例如Hive、HBase等都是基于HDFS和MapReduce,是为了解决特定类型的大数据处理问题而提出的子项目,使用Hive、HBase等子项目可以在更高的抽象的基础上更简单的编写分布式大数据处理程序。Hadoop的其它子项目还包括Common, Avro, Pig, ZooKeeper, Sqoop, Oozie 等,随着时间的推移一些新的子项目会被加入进来,一些关注度不高的项目会被移除Hadoop家族,所以Hadoop是一个充满活力的系统。
第4分钟:
什么问题场景下适合使用HDFS?什么场景下不适合采用HDFS?
答:
适合使用Hadoop的场景:非常大的文件,包括单个文件非常大(例如超过100G大小的文件)和文件总大小非常大(例如达到P级别),即支持海量的数据;“write-once,read-many-times”的Streaming的文件访问方式;普通的硬件系统支持大数据的处理;
不适用Hadoop的场景:低延迟的数据访问;有很多细小文件的系统;要多次写入和修改的文件系统;
第5分钟:
如何解读HDFS架构图?
答:架构图如下:
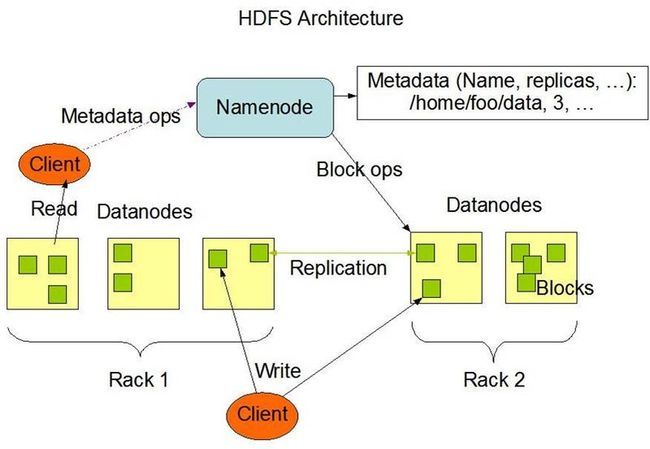
HDFS架构图的解读:
1,HDFS会把一个大文件分成很多小些的文件,把这些小文件存放在不同的节点上;
2, 这些数据存放的节点叫做DataNode,DataNade中存放HDFS中定义的Block,即数据块,每块的大小是64M;
3,HDFS把大文件分成的多个小文件不仅存放在不同的节点上,而且同一个文件块在不同的节点上有多个副本;
4,记录这些数据和数据划分以及存储信息的节点叫做NameNode,NameNode是关键性的配置文件,而且是单一节点存在的,在2.x开始使用了HA策略,即HDFS支持NameNode的active-standy模式了;
5, 客户端请求Hadoop中的数据时先要访问NameNode,从NameNode中获取DataNode中数据存储的信息后,才进行具体数据的访问;
第6分钟:
MapReduce到底是如何工作的?
答:家林举个例子你就明白了:求20个数据中的最大数,一般的编程方式把第一个数据开始往后面一个个的比较,总是把更大的数据记录下来,这样顺序比较下去,最后就得到了最大的数据;但是MapReduce的做法是把这20个数据分成4组,每组5个数据,每组采用Map函数求出最大值,然后后每组把求得的各自最大值交给Reduce,由Reduce得出最后的最大值;
简言之:MapReduce的工作方式就是大事化小,并行工作,各个击破。
第7分钟:
为什么要学习Hadoop?
答:Hadoop是云计算的具体实践技术,是处理大数据的开源框架,而大数据处理是IT界越来越热的主题,通过Hadoop开源代码的学习也是工程师提升自己功力的一个绝佳途径。
第8分钟:
如何开始学习Hadoop?
答:先搭建好Hadoop的单击环境、伪分布式环境和分布式环境。
第9分钟:
如何没有任何障碍的成为Hadoop高手?
答:学习免费发布王家林的云计算分布式大数据Hadoop实战高手之路(共3本书):
1,王家林编写的“云计算分布式大数据Hadoop实战高手之路---从零开始”带领您无痛入门Hadoop并能够处理Hadoop工程师的日常编程工作,进入云计算大数据的美好世界。
2,王家林编写的“云计算分布式大数据Hadoop实战高手之路---高手崛起”通过数个案例实战和Hadoop高级主题的动手操作带领您直达Hadoop高手境界。
3,王家林编写的“云计算分布式大数据Hadoop实战高手之路---高手之巅”通过当今主流的Hadoop商业使用方法和最成功的Hadoop大型案例让您直达高手之巅,从此一览众山小。
第10分钟:
进入家林的Hadoop教程,开始搭建Hadoop开发环境!