在进行文本处理时,有时候需要从多级目录的多个文件中取出某些数据。命令行难以处理较复杂的过程,而高级语言虽然可以实现这种算法,但代码比较难写,再加上可能存在大文件,处理起来会更加困难。集算器支持游标读取大文件、脚本递归调用,易于实现批量文件处理,下面通过例子来看一下具体作法。
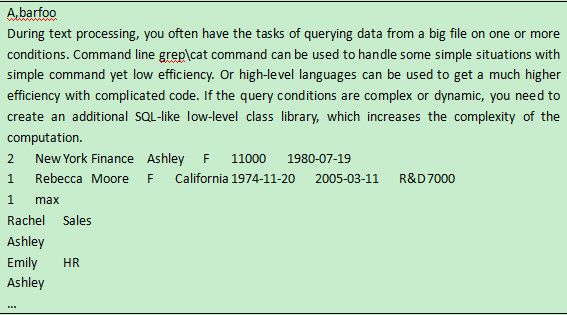
目录“D:\files”包含多级子目录,每个目录下都有许多文本格式的文件,从这些文件中读取指定的行(比如第二行),并将这些数据写入新的文件result.txt。目录D:\files的部分结构如下:
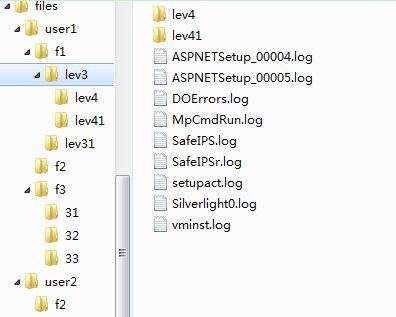
集算器代码:
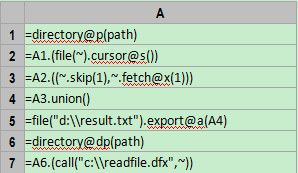
首先定义一个参数path,初始值设为“D:\files”,这样就可以从该目录开始抽取数据。如下图:
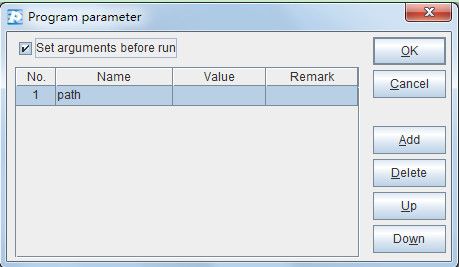
A1=directory@p(path)
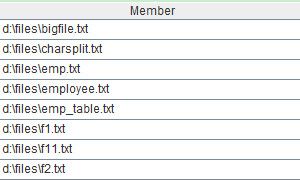
函数directory用来读出参数path中根目录的文件列表,选项@p表示文件名带全路径,部分结果如下:
A2=A1.(file(~).cursor@s())
这句代码用来以游标的方式依次打开A1中的文件。A1.(…)表示对A1的成员依次进行计算,~用来表示当前成员,函数file用来建立文件对象,函数cursor表示根据文件对象返回游标对象。
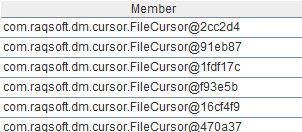
函数cursor的默认分隔符是tab,默认列名是_1,_2…_n,选项@s表示忽略分割符并将文件内容读成单列字符串,列名是_1。值得注意的是,这句代码只是建立游标对象,并没有读入数据,实际的读入动作会在遇到函数fetch时触发。A2的计算结果如下:
A3=A2.((~.skip(1),~.fetch@x(1)))
这句代码可以从A2的每个文件游标中读取第二行。A2.(…)表示对A2中的每个游标依次计算,(~.skip(1),~.fetch@x(1))表示依次计算括号内的表达式,并返回最后一个表达式的结果。其中~.skip(1)表示跳过一行,~.fetch@x(1)表示从当前位置读取一行(即第二条)并关闭游标,选项@x表示取完数据后自动关闭游标,~.fetch@x(1)就是括号运算符要返回的结果。
函数skip可以跳过多行,也可以通过参数来决定需要跳过几行。函数fetch也可以取出多行,比如从第10行开始取2行,可以写作~.skip(10),fetch@x(2)。
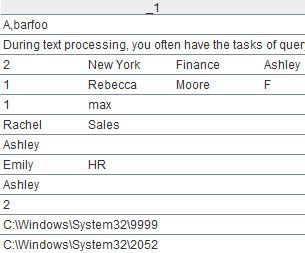
A3的部分计算结果如下:

A4=A3.union()
这句代码将A3的计算结果合并。函数union执行并集操作,比如对两个集合[1,2]和[2,3]计算并集,代码是[12],[2,3]].union(),结果等于[1,2,3]。函数union会去除重复数据,如果想保留重复,应该使用函数conj(也叫合集)。A4的部分结果如下:
A5=file("d:\\result.txt").export@a(A4)
这句代码用来将A4追加到result.txt中。函数export执行写文件操作,选项a表示追加。
上述A1-A5已经完成了当前目录里文件的抽取,下面只要取出当前目录的子目录,并递归调用本脚本即可。
A6=directory@dp(path)
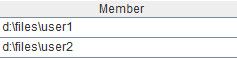
函数directory可以取出当前目录的所有子目录,选项d表示取目录名,选项p表示取全路径。对于目录D:\files,A6的计算结果如下:
A7=A6.(call("c:\\readfile.dfx",~))
这句代码依次对A6中的成员(各子目录)进行计算,算法是:调用集算器脚本c:\\readfile.dfx,并将当前成员(子目录)作为入口参数。注意:readfile.dfx就是本脚本的文件名。
通过A7的递归调用,集算器就可以对D:\files下的多级目录进行批量抽取,打开result.txt可以看到最终计算结果: