虚机环境配置
目前只有一台虚拟机,设置IP为192.168.26.131,对这台虚拟机进行环境和Hadoop相关的配置后,关闭它然后克隆两个相同的虚拟机,然后针对每台虚拟机做虚拟机独有的设置
- 设置主机名
- 设置SSH免密码登陆
在一台虚机上,做如下操作:
- IP与域名绑定
- 关闭防火墙
- Hadoop相关配置
1. IP与域名绑定
编辑文件sudo vim /etc/hosts,输入如下内容:
192.168.26.131 hadoop.master 192.168.26.132 hadoop.slave1 192.168.26.133 hadoop.slave2
2. 关闭防火墙
systemctl status firewalld.service #查看防火墙状态 sudo systemctl stop firewalld.service #停止防火墙服务 sudo systemctl disable firewalld.service #永久不启用防火墙服务
3. Hadoop相关配置---见后面Hadoop相关配置
Hadoop相关的配置主要涉及/home/hadoop/software/hadoop-2.5.2/etc/hadoop目录下的其个文件:
- yarn-site.xml
- mapred-site.xml
- core-site.xml
- hdfs-site.xml
- slaves
- hadoop-env.sh
- yarn-env.sh
3.1. yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop.master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop.master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop.master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop.master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop.master:8088</value>
</property>
</configuration>
3.2 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop.master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop.master:19888</value>
</property>
</configuration>
3.3 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop.master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/data/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value></value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value></value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
</configuration>
3.4 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop.master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
3.5 slaves
hadoop.slave1 hadoop.slave2
3.6 yarn-env.sh
添加export JAVA_HOME=/home/hadoop/software/jdk1.7.0_67
3.7 hadoop-env.sh
添加export JAVA_HOME=/home/hadoop/software/jdk1.7.0_67
关闭上面的虚拟机,复制两份虚机,每个虚机做如下操作
- 配置主机名
1. 在192.168.26.131上设置主机名为hadoop.master
sudo hostnamectl set-hostname hadoop.master #查看主机名 hostname
2. 在192.168.26.132上设置主机名为hadoop.slave1
sudo hostnamectl set-hostname hadoop.slave1 #查看主机名 hostname
3. 在192.168.26.133上设置主机名为hadoop.slave2
sudo hostnamectl set-hostname hadoop.slave2 #查看主机名 hostname
- SSH免密码登录
1.在192.168.26.131,192.168.26.132,192.168.26.133上分别执行如下命令,生成RSA私有密钥和公有密钥
ssh-keygen -t rsa -P ""
2. 在每个虚机上,执行如下操作:
2.1 将当前目录切换到/home/hadoop/.ssh
2.2 执行如下命令将id_rsa.pub复制到authorized_keys文件中(这个命令首先创建authorized_keys文件)
cat id_rsa.pub > authorized_keys
4.在每台虚拟机上设置.ssh目录和authorized_keys文件的权限
chmod 700 .ssh chmod 600 authorized_keys
5. 在192.168.26.131上执行如下命令,检查SSH免密码登录是否起作用
ssh localhost exit ssh 192.168.26.132 exit ssh 192.168.26.133 exit5.在其它两台虚拟机上分别执行步骤4
运行Hadoop
- 在192.168.26.131上格式化Hadoop的Namenode
- 在192.168.26.131上启动Hadoop
1. 切换到/home/hadoop/software/hadoop-2.5.2/sbin目录
- 查看Hadoop进程
1. 在192.168.26.131执行jps命令,查看主节点进程
[hadoop@hadoop hadoop]$ jps 3537 SecondaryNameNode 3330 NameNode 5278 Jps 3700 ResourceManager
2. 在192.168.26.132执行jps命令,查看子节点Slave1进程
2400 DataNode 2533 NodeManager 3621 Jps
3. 在192.168.26.133执行jps命令,查看子节点Slave2进程
2235 DataNode 3565 Jps 2376 NodeManager
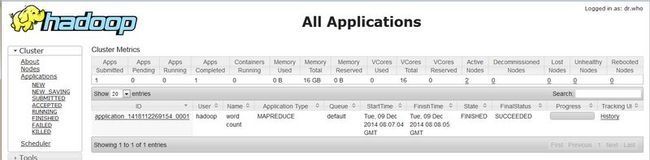
- 运行WordCount程序
- 查看Hadoop的web页面
访问:http://hadoop.master:8088
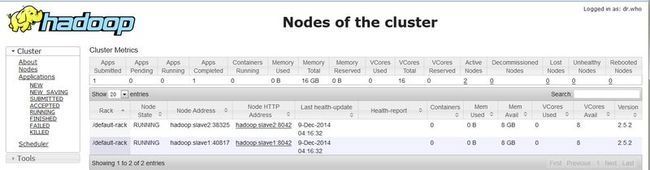
http://hadoop.master:8088/cluster/nodes
http://hadoop.master:8088/cluster/apps
HDFS状态
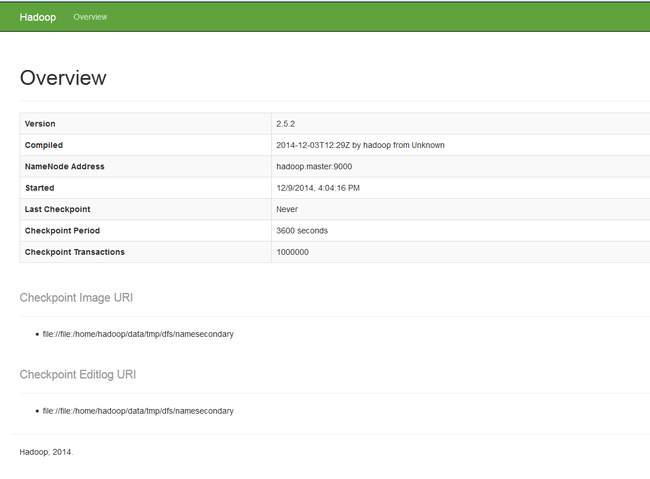
访问http://hadoop.master:50070



访问http://hadoop.master:9001/status.html查看secondary namenode的状态