在Solr中该如何使用IK分词器呢,这是小伙伴们问的频率比较高的一个问题,今晚特此更新此篇博客。其实之前我在其他博客里已经使用了IK分词器,只是我没做详细说明。
在schema.xml配置中其实有很多关于分词器的配置示例,我从中摘录一段配置示例,比如:
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
fileType是用来定义域类型的,name即表示域名称,class即表示域类型对应的class类,如果是solr内置的域类型则可以直接使用solr.前缀+域类型的类名即可,如果是你自定义的域类型,则class表示自定义域类型的完整类名(包含完整的包路径),在fileType元素下有analyzer元素,用来配置当前域类型使用什么分词器,你肯定很奇怪,为什么要配置两个analyzer,其实主要是为了区分两个阶段:索引建立阶段和Query查询阶段,索引建立阶段需要分词毋庸置疑,查询阶段是否需要分词,则取决于你的业务需求,用过Google的知道,用户在查询输入框里输入查询关键字,这时候我们需要对用户输入的查询关键字进行分词器,这时候我们就需要配置查询阶段使用什么分词器,为什么把分开配置?两者可以使用统一配置不行吗,配置两遍不是显得很冗余且繁琐吗?analyzer的type元素就表示这两个阶段,之所以要分阶段配置分词器,是为了满足用户潜在的需求,因为查询阶段的分词需求和索引阶段的分词需求不一定是相同的。我们都知道分词器Analyzer是由一个Tokenizer + N个tokenFilter组成,这就是为什么analyzer元素下会有tokenizer元素和filter元素,但tokenizer元素只允许有一个,filter元素可以有N个。之所以这样设计是为了为用户提供更细粒度的方式来配置分词器的行为,即你可以任意组合tokenizer和filter来实现你的特定需求,当然你也可以把这种组合写在Analyzer类里,然后直接在analyzer元素的class属性里配置自定义分词器的完整类名,这样就不需要这么繁琐的配置tokenizer和filter,即把实现细节屏蔽在analyzer类内部,但这样做的话,如果你需要更改实现细节,则需要修改Analyzer源码,然后重新打包成jar,相对来说,比较麻烦点,而使用analyzer,tokenizer,filter这样来配置,虽然繁琐点,但更灵活。而且采用<analyzer class="xxxxxxxx.IKAnalyzer"这样配置方式,看起来是比较简洁,我想你可能会比较喜欢这种方式,遗憾的是,solr在实现这种方式的时候,考虑不够周全,比如IKAnalyzer分词器,我们都知道IK分词器的构造器还有个useSmart参数,表示是否开启智能分词,而<analyzer class="xxxxxxxx.IKAnalyzer"这种方式,本质还是通过SAX方式解析XML,然后得到class类型字符串,然后通过反射去创建Analyzer实例对象,你可能会问我,我为什么知道是这样实现的?我看了Solr的源码所以我知道,无码无真相,来看截图:(在FieldTypePluginLoader类中)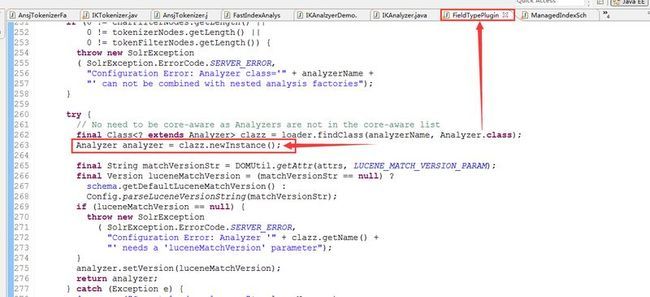
关键点部分我已经使用红色方框标注出来了,class.newInstance()本质就是通过反射的方式去调用类的无参构造函数,这个大家都知道吧,而IKAnalyzer分词器的构造函数代码如图: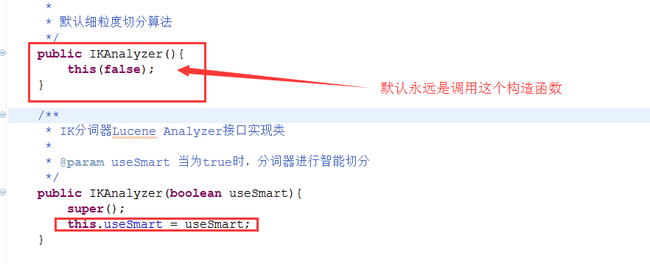
这意味着useSmart参数永远得不到设置,它永远为false,这就是采用<analyzer class="xxxxxxxx.IKAnalyzer"这种方式进行配置的弊端。它看似非常简洁,但暗藏陷阱,坑爹的Solr。那有没办法解决呢?我能想到的办法就是修改源码重新打包,你可能会问怎么修改?听我慢慢说,不要急。
在FieldTypePluginLoader类中有个readAnalyzer(Node node)方法,其中有一句代码非常关键:
NamedNodeMap attrs = node.getAttributes(); String analyzerName = DOMUtil.getAttr(attrs,"class");
其中node对象即表示当前<analyzer元素节点,而DOMUtil.getAttr(attrs,"class");表示通过DOMUtil工具类来获取<analyzer元素的class属性,这个好理解吧,我们在schema.xml中可能是这样配置的
<analyzer class="xxxxx.IKAnalyzer",那一句目的就是获取分词器的class类名,知道类名了就可以反射去创建分词器实例对象啊,就这么简单,所以我们可以自己在<analyzer元素中加一个参数,比如这样:
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="true"/>
然后我们在代码里String useSmart = DOMUtil.getAttr(attrs,"useSmart");就可以获取到属性值了,然后就是通过反射把属性值设置到IKAnalyzer类的useSmart属性中了,这是基本的Java反射操作,下面我提供几个反射工具方法:
/**
* 循环向上转型, 获取对象的DeclaredField. 若向上转型到Object仍无法找到, 返回null.
*/
protected static Field getDeclaredField(final Object object, final String fieldName) {
if (null == object || null == fieldName || fieldName.equals("")) {
return null;
}
for (Class<?> superClass = object.getClass(); superClass != Object.class; superClass = superClass.getSuperclass()) {
try {
return superClass.getDeclaredField(fieldName);
} catch (NoSuchFieldException e) {
// Field不在当前类定义,继续向上转型
continue;
}
}
return null;
}
/**
* 直接设置对象属性值, 无视private/protected修饰符, 不经过setter函数.
*/
public static void setFieldValue(final Object object, final String fieldName, final Object value) {
Field field = getDeclaredField(object, fieldName);
if (field == null) {
throw new IllegalArgumentException("Could not find field [" + fieldName + "] on target [" + object + "]");
}
makeAccessible(field);
try {
field.set(object, value);
} catch (IllegalAccessException e) {
throw new RuntimeException("直接设置对象属性值出现异常", e);
}
}
/**
* 强行设置Field可访问
*/
protected static void makeAccessible(final Field field) {
if (!Modifier.isPublic(field.getModifiers()) || !Modifier.isPublic(field.getDeclaringClass().getModifiers())) {
field.setAccessible(true);
}
}
直接调用setFieldValue方法即可,比如在Analyzer analyzer = clazz.newInstance();这句下面添加一句
setFieldValue(analyzer,"useSmart",Boolean.valueOf(useSmart ));
这样我们在xml中配置的useSmart参数就设置到Analyzer类中了,这样才能起作用。solr源码如何导入Eclipse上篇博客里我已经介绍过了,至于如果把修改过后的代码打包成jar,直接使用eclipse自带的export功能即可,如图:




然后一路Next即可。我只是说说思路,剩下留给你们自己去实践。
但是采用改源码方式不是很优雅,因为你本地虽然是修改好了,哪天你由Solr5.1.0升级到5.2.0,还要再改一遍,没升级一次就要改一次,你的代码copy给别人用,别人运行代码后看不到效果,增加沟通成本,你还得把你改过源码的jar包共享给别人,这也就是为什么有那么多人找我要什么IK jar包。
在Solr中可以使用TokenizerFactory方式来解决我刚才提出的问题:IKAnalyzer分词器的useSmart参数无法通过schema.xml配置文件进行设置。我花了点时间扩展了IKTokenizerFactory类,代码如下:
package org.apache.lucene.analysis.ik;
import java.util.Map;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeFactory;
import org.wltea.analyzer.lucene.IKTokenizer;
public class IKTokenizerFactory extends TokenizerFactory {
public IKTokenizerFactory(Map<String, String> args) {
super(args);
useSmart = getBoolean(args, "useSmart", false);
}
private boolean useSmart;
@Override
public Tokenizer create(AttributeFactory attributeFactory) {
Tokenizer tokenizer = new IKTokenizer(attributeFactory,useSmart);
return tokenizer;
}
}
同时我对IKTokenizer类也稍作了修改,修改后源码如下:
/**
* IK分词器 Lucene Tokenizer适配器类
* 兼容Lucene 4.0版本
*/
public final class IKTokenizer extends Tokenizer {
//IK分词器实现
private IKSegmenter _IKImplement;
//词元文本属性
private final CharTermAttribute termAtt;
//词元位移属性
private final OffsetAttribute offsetAtt;
//词元分类属性(该属性分类参考org.wltea.analyzer.core.Lexeme中的分类常量)
private final TypeAttribute typeAtt;
//记录最后一个词元的结束位置
private int endPosition;
private Version version = Version.LATEST;
/**
* Lucene 4.0 Tokenizer适配器类构造函数
* @param in
* @param useSmart
*/
public IKTokenizer(Reader in , boolean useSmart){
//super(in);
offsetAtt = addAttribute(OffsetAttribute.class);
termAtt = addAttribute(CharTermAttribute.class);
typeAtt = addAttribute(TypeAttribute.class);
_IKImplement = new IKSegmenter(input , useSmart);
}
public IKTokenizer(AttributeFactory factory, boolean useSmart) {
super(factory);
offsetAtt = addAttribute(OffsetAttribute.class);
termAtt = addAttribute(CharTermAttribute.class);
typeAtt = addAttribute(TypeAttribute.class);
_IKImplement = new IKSegmenter(input , useSmart);
}
/* (non-Javadoc)
* @see org.apache.lucene.analysis.TokenStream#incrementToken()
*/
@Override
public boolean incrementToken() throws IOException {
//清除所有的词元属性
clearAttributes();
Lexeme nextLexeme = _IKImplement.next();
if(nextLexeme != null){
//将Lexeme转成Attributes
//设置词元文本
termAtt.append(nextLexeme.getLexemeText());
//设置词元长度
termAtt.setLength(nextLexeme.getLength());
//设置词元位移
offsetAtt.setOffset(nextLexeme.getBeginPosition(), nextLexeme.getEndPosition());
//记录分词的最后位置
endPosition = nextLexeme.getEndPosition();
//记录词元分类
typeAtt.setType(nextLexeme.getLexemeTypeString());
//返会true告知还有下个词元
return true;
}
//返会false告知词元输出完毕
return false;
}
/*
* (non-Javadoc)
* @see org.apache.lucene.analysis.Tokenizer#reset(java.io.Reader)
*/
@Override
public void reset() throws IOException {
super.reset();
_IKImplement.reset(input);
}
@Override
public final void end() {
// set final offset
int finalOffset = correctOffset(this.endPosition);
offsetAtt.setOffset(finalOffset, finalOffset);
}
修改后重新打包的IKAnalyzer jar请见底下的附件。
然后我把它打包成了solr-analyzer-ik-5.1.0.jar,只需要把这个jar包复制到你的core\lib目录下即可,然后你就可以像配置StandardTokenizerFactory一样的使用我们自定义的IKTokenizerFactory类了,并且能配置useSmart参数,这正是我想要的,能灵活的控制分词器参数,so cool。配置示例如下:
然后field域里应用我们配置的这个text_ik域类型,如图:
然后你还需要把IKAnalyzer jar包以及我们自定义的IKTokenizerFactory的jar包copy到你当前core\lib目录下,如图:
IKAnalyzer jar建议使用底下附件里我新上传的,因为源码我稍作了修改,上面已经提到过了。然后你需要把IKAnalyzer.cfg.xml配置文件copy到E:\apache-tomcat-7.0.55\webapps\solr\WEB-INF\classes目录下,其中E:\apache-tomcat-7.0.55为我的Tomcat安装根目录,请类比成你自己的tomcat安装根目录,你懂的。如图: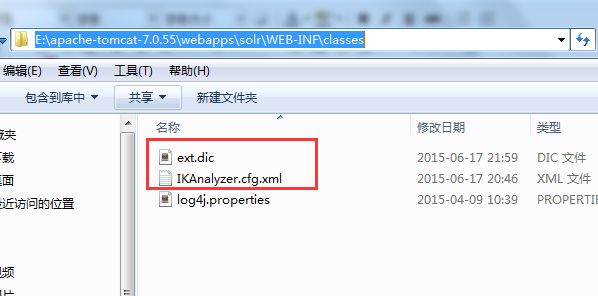
IKAnalyzer.cfg.xml配置如图: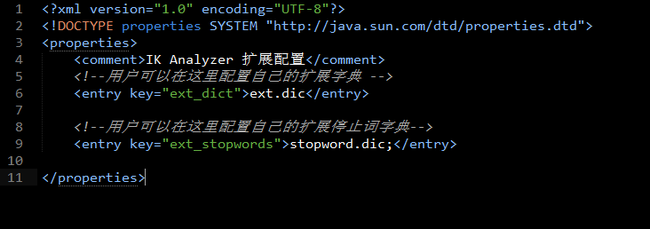
ext.dic为IK分词器的自定义扩展词典,内容如图:
我就在里面加了两个自定义词语。
然后你就可以启动你的tomcat,然后如图进行分词测试了,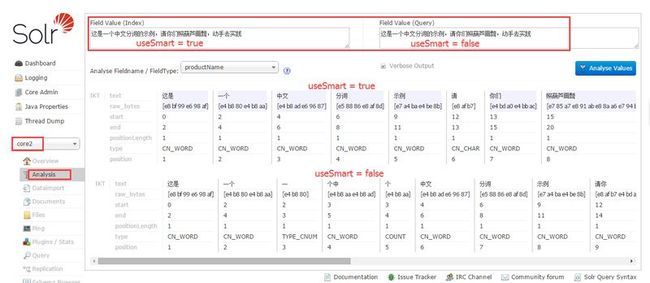
上图是用来测试useSmart参数设置是否有生效,如果你看到如图的效果,说明配置成功了。
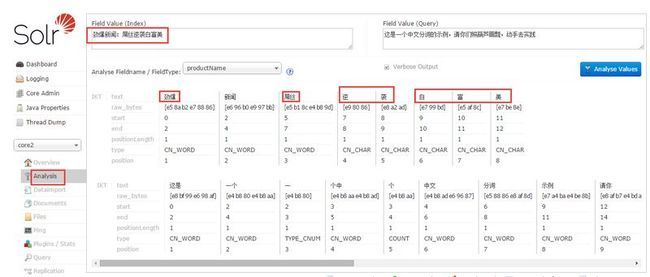
上图是用来测试自定义词典是否有生效,因为我在ext.dic自定义词典里添加了 劲爆 和 屌丝 这两个词,所以IK能分出来,逆袭和白富美没有在自定义扩展词典里添加,所以IK分不出来。如果你能看到如图效果,说明IK的自定义扩展词典也配置成功了。到此,关于在Solr中使用IK分词器就介绍到这儿了,如果你还有任何疑问,请通过以下方式联系到我,谢谢!!!博客里提到的相关jar包配置文件等等资源文件,我待会儿都会上传到底下的附件里,特此提醒!!!!!
益达Q-Q: 7-3-6-0-3-1-3-0-5
益达的Q-Q群: 1-0-5-0-9-8-8-0-6