要想在Sor中使用MMSeg4J分词器,首先你需要自定义一个TokenizerFactory实现类,虽然直接配置Analyzer类也可以,但那样无法配置Analyzer构造函数的参数,不够灵活,存在弊端,所以我一直都是以扩展TokenizerFactory的方式来讲解类似MMSeg4J这样的中文分词器在Solr中的使用。
MMSegTokenizerFactory类我花了3个多小时修改了源码并经过N多测试,表示已经可以使用,我主要的是针对Lucene5 API对MMSegTokenizer类做了升级更新并添加了自定义停用词功能,默认MMSeg4J没有实现自定义停用词功能。相关jar包请到底下的附件里去下载。下面介绍MMSeg4J在solr5中的使用步骤:
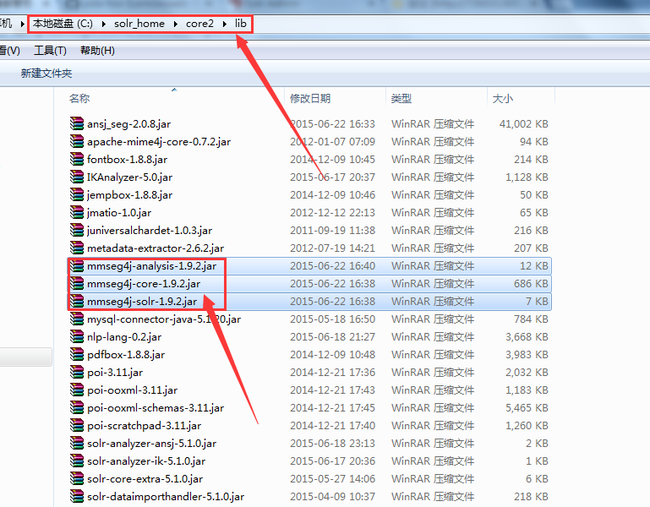
1. copy依赖的jar包到当前core\lib目录下,如图:
2.在你的schema.xml中配置fieldType应用上我扩展的MMSegTokenizerFactory类,具体配置看图: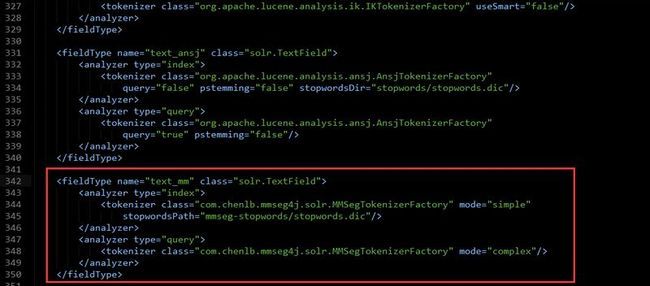
<fieldType name="text_mm" class="solr.TextField">
<analyzer type="index">
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple"
stopwordsPath="mmseg-stopwords/stopwords.dic"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex"/>
</analyzer>
</fieldType>
其中mode参数表示MMSeg4J的分词模式,自带有3种可选值:simple,complex,maxword, mode参数不配置默认为maxword模式;stopwordsPath是用来配置自定义停用词加载路径的,默认是相对于classPath的,自定义停用词字典文件放置路径请看图: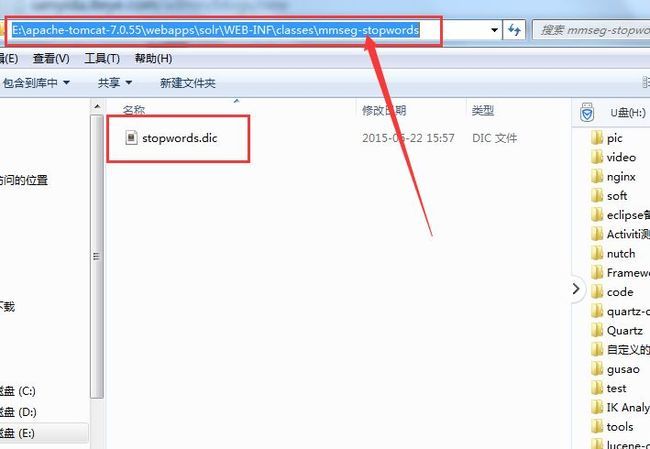
自定义停用词词典文件加载路径配置参数是可选的,不过由于MMSeg4J没有内置停用词功能,所以像空格字符,标点符号等等都会被分出来,所以一般建议添加停用词词典文件。不过要注意的是,自定义的停用词词典文件的编码必须是UTF-8无BOM格式,而且在你使用文本编辑软件打开进行编辑的时候,请务必将你的编辑软件的编码设置为UTF-8,否则可能会出现本来是UTF-8无BOM编码,你打开编辑保存后编码就改变了。当你发现明明停用词在词典文件里,却很奇怪不起作用时,那十有八九是因为词典文件编码已经被破坏,建议词典文件不要自己新建,可以保留一个dic模版文件,每次直接copy过来修改文件名然后再打开编辑。
3.然后你需要在你的某个field域上应用刚才定义的FieldType(域类型),如图: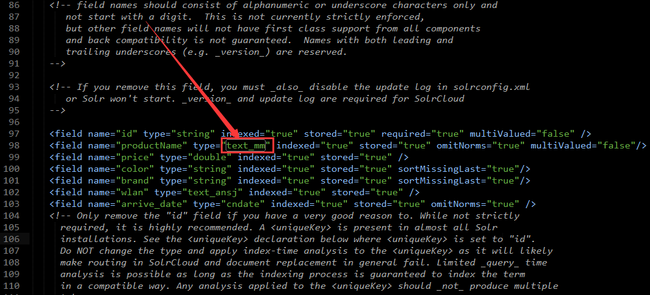
OK,现在你可以启动你的Tomcat进行分词测试了,如图: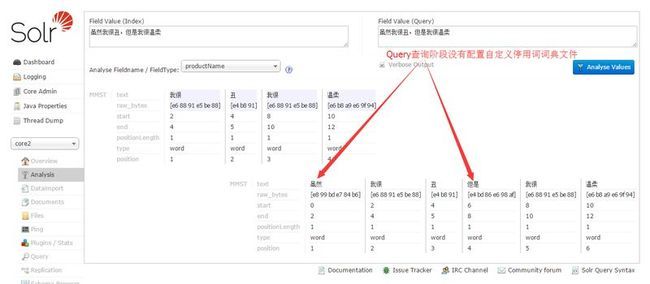
mmseg-stopwrods目录下的stopwords.dic停用词词典文件我添加了如下停用词: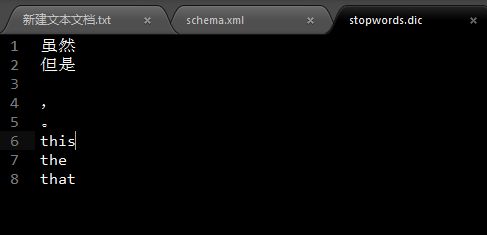
第3个是一个空格字符,第4个是中文状态下的逗号字符,第5个是中文状态下的句号字符。你想要剔除哪些字符,具体留给你们自己去完善。
如果我想配置自定义新词呢,比如么么哒,萌萌哒之类的,默认肯定是分不出来的,该如何配置呢?MMSeg4J默认是内置了自定义词典扩展功能的,且默认加载思路如下:
从默认目录加载词库文件, 查找默认目录顺序:
1.首先从系统属性mmseg.dic.path指定的目录中加载
2.若从系统属性mmseg.dic.path指定的目录中加载不到,再从classpath/data目录加载
3.若从classpath/data目录加载不到,再从user.dir/data目录加载
需要注意的是,MMSeg4J对于字典dic文件的命名有要求,只有以words开头 以.dic结尾的文件才会被加载。
知道上述加载原理,那我们只需要把自定义扩展词典文件如图放置即可: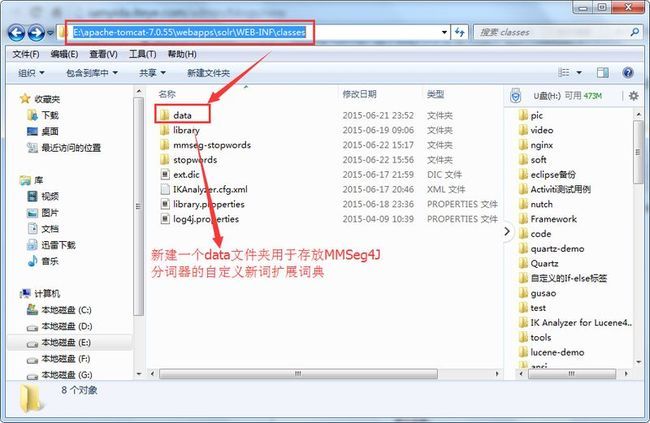
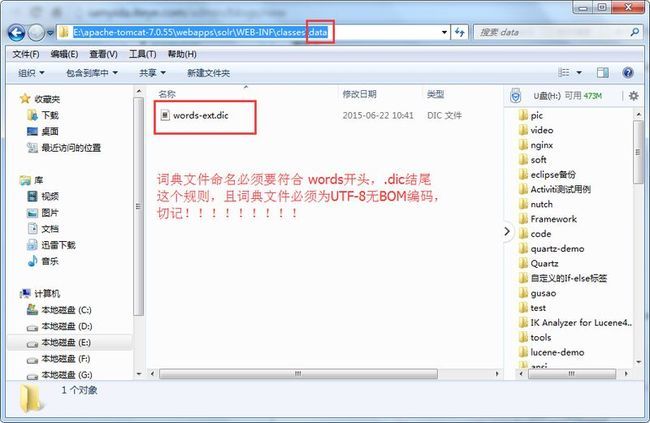
到此,MMSeg4J分词器在Solr5中的使用就讲解完毕了,请照葫芦画瓢,100%会配置成功的,如果你看不到效果,请对照截图看清楚词典文件放置路径,检查你的dic文件的编码是否为UTF-8无BOM,如果你还有任何问题,请通过以下方式联系到我:
益达的GitHub地址:请猛戳我,用力,吃点劲儿!!!
益达Q-Q: 7-3-6-0-3-1-3-0-5
益达的Q-Q群: 1-0-5-0-9-8-8-0-6