HDFS RAID
引自个人blog: http://jiangbo.me/blog/2012/12/21/hdfs-raid/
一、背景
HDFS是构建在普通机器上的分布式文件系统,而这类系统需要解决的一个首要问题就是容错,允许部分节点失效。而为了解决数据的可靠性,HDFS采用了副本策略。默认会为所有的block存放三个副本(具体参见HDFS设计文档)。 副本机制能够有效解决部分节点失效导致数据丢失的问题,但对于大规模的HDFS集群,副本机制会带来大量的存储资源消耗。例如为了存储1PB的数据,默认需要保留3个副本,这意味着实际存储所有副本需要至少3PB的空间。存储空间浪费达到200%。减小浪费的方式主要是减少副本数,而当副本数降低到小于3时,数据丢失的风险会非常高。而HDFS RAID的出现主要是解决降低副本数之后,通过RAID机制中的Erasured Code来确保数据的可用性。
二、整体结构
HDFS RAID的实现(Facebook的实现)主要是在现有的HDFS之上增加了一个包装contrib。之所以不再HDFS上直接修改,原设计者的解释是“HDFS的核心代码已经够复杂了,不想让它更复杂”。
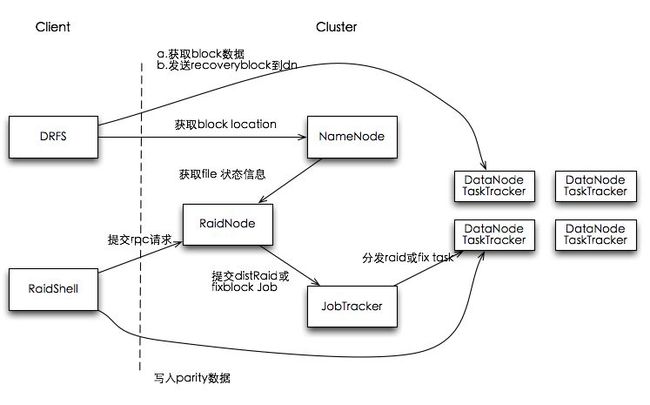
2.1 使用的角度看HDFS RAID(Client端)
HDFS RAID的使用场景主要有两个:raid数据管理和raid数据读取。
2.1.1 Raid数据的管理
对于DRFS的管理,包括DFS中那些文件需要进行raid化,查询raid文件的状态等,主要通过HDFS-RAID提供的RaidShell工具来完成。本质上RaidShell作为一个client工具,通过RPC与集群中的RaidNode通信,完成各种管理操作。
2.1.2 Raid数据读写
使用HDFS RAID的client端需要配置fs.hdfs.impl为DistributedRaidFileSytem,DRFS包装了DFS的读(只是读)请求,当block读取时发生block丢失(抛出MissingBlockException)或损坏(CorruptionException)时,DRFS会捕获这两个异常,并向RaidNode发送RPC对失效的数据进行恢复。
2.2 RaidNode结构(Server端)
RaidNode是HDFS-RAID中除NameNode和JobTracker之外的第三个master node,主要是接收client端的RPC请求和调度各守护线程完成数据的raid化和数据修复,parity文件删除等操作。
2.2.1 两种实现
LocalRaidNode: 在RaidNode本地进行parity计算,parity文件的生成是一个计算密集型任务,而本地计算能力有限,因此该方式的扩展性有限。
DistributedRaidNode: 通过提交mapreduce job来进行parity计算
2.2.2 主要线程
TriggerMonitor: 周期性检查raid-policy配置,根据最新的配置来进行对相应的数据raid化。raid化的调度周期主要收两个配置的影响,raid.config.reload.interval (重新加载raid-policy配置的周期,默认10s)和raid.policy.rescan.interval(重新扫描需要raid化的src的间隔,默认1小时)。简单讲,当新增了一个policy时,默认10s内该policy会被加载执行。而在一个已经raid化的目录中新增了一个文件时,该文件将在1个小时内被raid话。
BlockIntegrityMonitor: 负责通过DFS的fsck来对DRFS中已经raid化的数据进行检查,检查内容主要包括corrupt(损坏)和decomssion(丢失)的文件。一旦检测到这类文件的存在,BlocIntegrityMonitor会通过其维护的CorruptMonitor和DecomissionMonitor的两个线程来进行数据的修复。BlockIntegrityMonitor对应local和dist两种模式有两个实现,分别为LocalBlockIntegrityMonitor和DistBlockIntegrityMonitor。(可通过raid.blockfix.classname配置项设置,默认为dist)。区别主要在获取的corruptionMonitor和DecomissionMonitor的实现不同。
LocalBlockIntegrityMonitor: 提供了CorruptMonitor实现会循环通过fsck检查corrupt文件,通过BlockReconstructor.CorruptBlockReconstructor重建这些文件。但该实现不提供Decomissioning文件的监控处理。local模式下corrput文件的重建是在RaidNode上进行的,对大量数据的重建,会对RaidNode有较大的压力。
DistBlockIntegrityMonitor: Dist模式提供的CorruptionMonitor和DecomissionMonitor是通过DFSck获取corrupt和decomissed的文件列表,计算优先级后,通过向集群提交job来完成重建,Job的输入是一个包含所有文件path的sequence file,Mapper实现是通过Reconstructor来重建每个文件。
BlockFixer(CorruptionMonitor): BlockIntegrityMonitor构建的用于修复corrupt文件的worker线程。
BlockCopier(DecomissionMonitor): BlockIntegrityMonitor构建用于修复decomission文件的worker线程。
PlacementMonitor: PlacementMonitor主要是通过blockMover完成为DRFS中的根据placement策略提供在Datanode之间move block的工具线程。BlockMover通过一个ClusterInfo线程周期性(默认1min)获取集群中live节点的最新topo结构。对于parity block过于集中的节点,需要将其分散开。分散的过程主要是:为每个的block构建一个BlockMoveAction线程,该线程在所有datanode中除当前block所在的节点外随机选取一个datanode,并选取一个proxysource datanode,proxysource datanode是用于将block复制到datanode的源节点,选取规则是优先选取当前block副本所在dn中与目标datanode所属同一rack的节点,如果没有,则从副本列表中随机选取一个作为源节点。
PurgeThread: PurgeThread封装了PurgeMonitor,它会定期扫描Parity文件中是否有孤儿Parity文件(即拥有该Parity文件的source文件已经不存在了),如果有则需要将其删除,如果没有,会对Parity文件和对应的source文件进行placement检查。
HarThread: 为了减少RAID后Parity文件对Namenode的负担,HarThread封装了HarMonitor,它定期对超期的Parity文件进行归档处理(HAR),超期时间由raid.parity.har.threshold.days指定,默认是3天。
三、 raid和unraid流程详解
3.1 数据raid化
文件数据的raid化有两种场景,一种是通过raidShell之行 raidFile命令触发
hadoop raidshell -raidFile /path/to/file
另一种是TiggerMonitor线程周期行扫描policy,根据新的配置信息进行相应的raid化。
3.1.1 raidShell执行raidFile
当前client端执行raidfile请求时,大致的处理流程如下:
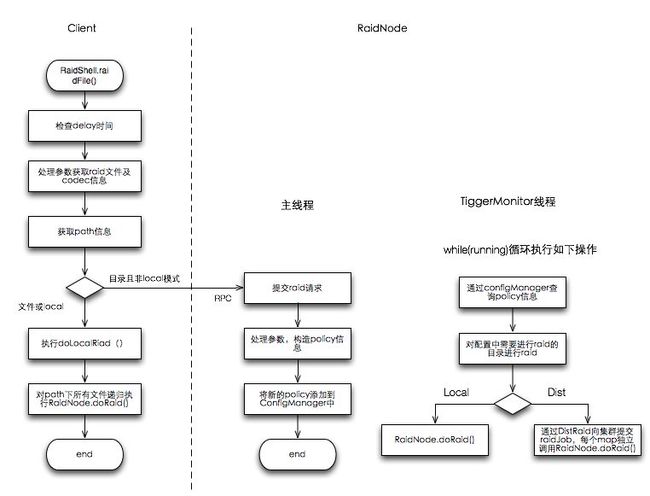
- 首先检查请求的delay时间,还未到delay时间则不执行
- 参数处理,包括path路径校验,codec设置等
- 查询path路径状态,如果是文件或者当前模式是local模式,则执行doLocalRaid,通过RaidNode.doRaid()对path下所有文件进行raid。
- 如果是目录且当前配置的raid模式是dist,则通过raidNode.submitRaid() rpc请求向RaidNode提交raid请求。
- RaidNode接收到client提交的请求后,根据提交的额参数构造一个raid-policy,并添加到configMangaer中。等待RaidNode上TiggerMonitor守护线程下次运行是处理该policy。
3.1.2 triggerMonitor线程处理流程
triggerMonitor作为RaidNode上的守护线程,周期性从configManager中获取policy列表,对每个policy进行如下处理:
- 查询该policy的状态,如果未执行过,则立即处理,获取path中文件列表。如果该policy已经处理过,过滤其path中尚未处理的file。
- 如果是local模式,对列表中的file执行RaidNode.doRaid()
- 如果是dist模式,通过DistRaid构建一个raid job,该job的输入文件是所有待raid文件path构成的sequence file。mapper主要是调用RaidNode.doRaid()对输入中的file path进行raid。
RaidNode.doRaid()流程
上述表明,hdfs raid中对文件的raid最终都是由RaidNode.doRaid()来完成,不通场景下的区别主要是raid过程的执行地点不同:
- raidshell执行的local模式或者单个文件,raid过程是在client上完成
- local模式下tiggermonitor触发的raid, raid过程是在RaidNode上完成
- raidshell执行的dist模式且是目录时进行的raid,或者dist模式下triggermonitor触发的raid,是通过job的方式提交到集群上由每个task节点完成。
RaidNode.doRaid()的主要流程如下:
- 获取文件的block信息,如果block数小于3,则不进行raid。
- 对于为打到delay时间的也不进行raid
- 如果已经到达delay时间且block数>2 时进行生成parity文件
- 生成parity文件过程如图右半部所示:首先获取src文件path,生成parity文件的path,parity文件path的生成规则是 $parity_dir+src_path(codec中配置的是parity_dir是/raid, src文件path是data/file1.log, 那么该文件的parity文件path就是/raid/data/file1.log)
- 检查相应的parity文件是否已经存在,如果存在,检查parity文件的mtime(更新时间)是否与源文件mtime一致,如果是,则认为该源文件已经raid且是最新。不需要再进行raid。
- 如果parity文件不存在或不是最新,则重新通过Encoder来生成parity文件
- 设置parity文件的mtime为源文件的mtime。
- 检查parity文件的最终状态,主要是mtime是否与源文件一致。通过则raid完成
3.1.3 Encoder.encode过程
raid过程中最终的编码生成parity的工作有Encoder完成。编码过程主要如下:
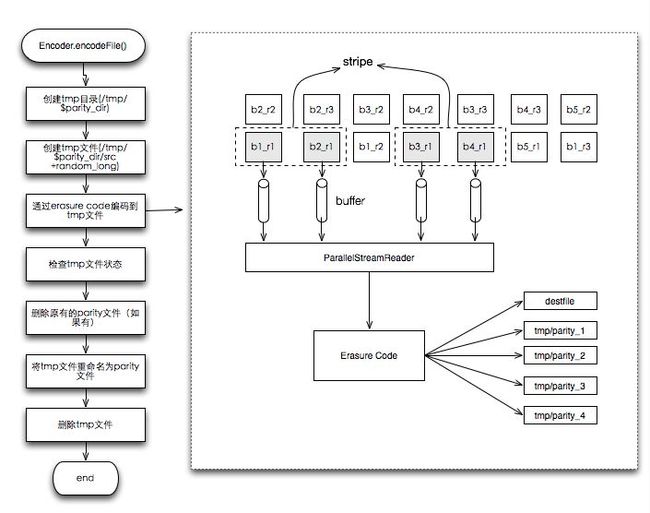
- 由于编码过程会比较长,所以先生成™p文件。™p文件的目录可以通过™p_parity_dir配置,默认是™p/$parity_dir
- 构建™p文件path,™p文件的path为™p目录下parity文件path加上一个随机long值构成,$™p_parity_dir/$parity_file+randomlong。
- 通过Erasued Code来进行编码到™p文件
- 删除原有的parity文件
- 将™p文件重命名为parity文件。
- 删除™p文件。
对于Erasured Code的生成过程大至流程如下: 从源文件中block列表中选取一些(数量有stripe_length指定,默认是10)block,构成一个strip(条?)。通过ParallelStreamReader工具构建一个并行读取10个block的的数据,每个block每次读取1个buff的数据(buffer大小有raid.encoder.bufsize指定,默认是1m),一次读取构成一个二维byte数组byte[stripe_length][buff_size],这个二维数组做为Erasure Code的输入数据,进行编码生成erasued code。输出也是一个byte二维数组byte[parity_length][buffer_size]。
XOR算法中:parity_length为1, 即根据10位输入byte生成1位的奇偶校验码。
RS算法中: parity_length默认为4, 及根据10为输入生成4为的RS code,这四位分别写入4个™p文件中,在一个buffer全部编码完成后,将4个parity文件进行合并。生成一个™p文件。
3.2 损坏数据的恢复
raid数据的修复同样也有多个触发场景:
- client端使用DRFS读取数据发生数据丢失或损坏延长
- RaidNode上BlockIntegrityMonitor周期获取block数据发现数据异常时
- 通过raidshell执行 fixblock时
3.2.1 block读取时修复损坏数据流程
在client通过DRFS读取raid话的数据是,DRFS首先通过其内部封装的DFS去读block数据,当DFS读取时跑出CorruptionException或DecomissionException时,会被DRFS捕获,并对出错的block在client进行修复。主要流程如下:
- 在client配置了DRFS并使用DFS作为内置fs时,当通过FS.open获取文件InputStream时,返回一个ExtFSDataInputStream实例。
- 通过该inputStream读取数据时,首先通过内置DFS读取响应的block,正常情况下,返回需要的数据。
- 当内置的DFS读取block时跑出CorruptionException或DecomissionException时,会被ExtFSDataInputStream捕获。通过调用RaidNode.unRaidCorrputionBlock()来获取一个恢复的block,并从该block读取数据。
RaidNode.unRaidCorruptionBlock()过程首先获取该block的parity文件信息,然后构建一个恢复文件的path路径(该路径位于hdfs.raid.local.recovery.location配置的目录下,默认是/tmp/raidrecovery,文件名为原文件名+”.”+随机long+”.recoveryd”),并通过Decoder.fixErasedBlock()来根据parity文件生成恢复文件。
注意:对于恢复文件所在的文件系统是可以通过fs.raid.recoveryfs.uselocal来配置的,默认是false,即使用DFS,恢复文件将在储与分布式系统中,当配置成true是,使用LocalFileSystem,将恢复文件存储在client端本地。
3.2.2 BlockIntegrityMonitor线程修复
RaidNode上的BlockIntegrityMonitor线程会通过DFSck工具检查系统中corrupt或decomission的数据,通过BlockCopier和BlockFixer线程周期行对出错的数据进行修复。local模式下,修复过程在RaidNode上之行,Dist模式下修复过程通过提交Job的方式提交给集群完成。
Local模式 LocalBlockIntegrity线程的核心是周期调用doFix方法修复corrupt文件,主要流程如下:
- 通过DFSck获取currput文件信息(HTTP访问)
- 过滤掉不能恢复的corrupt文件(没有parity文件的)
- 将corrput的文件排序,排序规则如下
- parity文件优先,source文件在后
- parity文件中codec.priority高的在先(codec.priority通过JSON中coder_priority配置)
- 对排序号的corrupt文件列表依次通过BlockRecontsturer来恢复。
Dist模式 DistBlockIntegrity中的有两个worker线程blockCopier和blockFixer,分别对应修复decomssion和corrput的文件。实际上两个线程的处理流程基本一致,大体如下:
- 检查当前正在运行的修复job数,如果当前job已经大于job上限,则等待之前的job运行完(该上线可以通过raid.blockfix.maxpendingjobs来配置,默认是100L)
- 通过DFSck获取损坏的文件信息,blockfixer线程获取corrupt文件信息,blockCopier获取decomission文件信息
-
计算获得的损坏文件的优先级:
corrput文件的优先级如下(R为文件副本数,C为该文件corrput的block数):
- 默认为LOW
- R>1 && C>0时: HIGH
- R==1 && C>1时: HIGH
- parityfile corrput && C>0时: HIGH
decomission优先级计算规则如下(D为decomission的block数):
- 默认为LOW
- D>4时: HIGH
-
将计算好优先级的文件列表按优先级排序,作为参数构建修复Job。
- Job的输入是所有需要修复的文件path的sequence file。会根据raid.blockfix.filespertask配置的值进行sync,即在job的split阶段会按照该值设置的进行split,默认是20
- Job的Mapper主要是通过Reconstruter在task机上完成响应文件的恢复。
注意:对于修复Job还有一个参数限制,及每次job最多进行的task数,该值为固定值50,这意味着一个Job一次最多能修复的文件数是100个(raid.blockfix.filespertask*50)
3.2.3 RaidShell之行fixblock
通过raidshell执行 fixblock时, raidShell会通过BlockReconstructor来完成文件的修复。
3.2.4 BlockReconstructor文件修复过程
BlockIntegrityMonitor和RaidShell对文件的修复最终都通过BlockReconstructor来完成。 BlockReconstructor修复文件过程主要分为三类:Har parity文件,parity文件和源数据文件。
Har parity文件
- 获取har文件的基本信息及index
- 获取har文件中的lost block,对每个block进行如下处理:
- 在本地文件系统创建该block的临时文件,
- 对该block涉及的所有parity文件,获取对应的source文件,通过Encoder重新encode,在本地生成parity数。
- 将本地生成的block数据发送到一个datanode上,datanode的选取规则是从集群中除原block所属节点外随机选取一个。发送过程同时生成block的meta文件。
parity文件
parity文件的修复处理相对简单:
- 在本次创建lost block的临时文件
- 获取parity文件的源文件,通过Encoder重新encode,在本地生成parity文件的block
- 选取一个dn(选取规则和har parity文件修复一致),将block数据发送到该dn上,并同时生成meta文件
源数据文件
源文件的恢复与parity文件的修复相反,是一个decode过程:
- 对于file中丢失的每个block执行修复操作
- 在本地创建block的临时文件
- 通过Decoder恢复block数据
- 选取一个target dn,将block数据发送给target dn,并同时生成meta文件。
3.2.5 Decoder的修复过程
Decoder的修复过程即一个parity文件的decode过程:
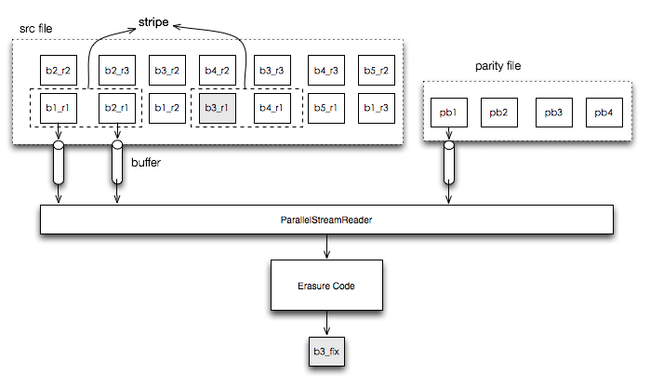
- 根据文件中出错的位置,计算出错的block,该block所在的stripe,以及在stripe中的位置,计算parity文件相应block的位置。
- 通过ParallelStreamReader读取源block数据和parity数据,读取方式与编码时类似
- 通过Erasured Code将源block和parity数据的进行解码,生成丢失的block数据。