JDK中HashMap的分析
J2SDK中提供了大量的通用类,供我们在开发的时候使用。其中,HashMap类是我们经常使用的。下面简单的分析了HashMap类的一些主要代码。
概述
HashMap类位于java.util包中。主要作用是提供了一个Map的实现,可以比较方便的进行 关键字(key) – 值(value)的存取。其主要方法为:
public Object put(Object key, Object value) 加入一个对象。
public Object get(Object key) 获得一个对象。如果没找到对应于key的对象,返回null.
下面着重分析这两个方法。
put方法
put方法的作用是将一个对象(value)加入到map中,它的key为(key)。如果key重复了,将替换掉旧的值,并将旧值返回。如果key没有重复,将新的值插入。该部分代码如下(有删节):
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
if (e.hash == hash && eq(k, e.key)) {
Object oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
addEntry(hash, k, value, i);
return null;首先,程序执行了maskNull函数。该函数很简单,仅仅判断如果key非空,直接返回,否则返回一个new Object(). 接下来,使用HashMap类中函数hash(k)来计算key的hash值(这应该就是这个类被命名为HashMap的原因)。比较有意思的是,hash函数中,并没有直接返回k.hashCode(),而是在hashCode()之上进行了额外的计算。按照该函数的javadoc,这是为了抵御"某些不良设计的hashCode函数"。
再往下,是计算hash值在列表中的起始位置。table就是实际保存值的列表,indexFor这个函数返回的是hash值的在table中的位置。具体含义为,一些key的hash值很可能是相同的(冲突),这些key冲突的key--value所在的项组成一个链表,indexFor函数返回的就是这个链表的首项。而这个indexFor函数极其简单:
static int indexFor(int h, int length) {
return h & (length-1);
}很明显,因为传入的hash值(h)可能为很大的数,所以通过与table的长度做AND运算,保证得到的位置在[0, table.length-1]的区间内。
这就带来一个问题:如果table的长度增加了,那么indexFor函数返回的位置可能就变化了,这就产生了错误。实际上,HashMap是能够避免这个问题的,后文分析。
继续查看put函数的代码。在得到了起始的位置之后,是一个while循环。该循环很简单,依次遍历相同hash值的Entry,如果key也相等,那么将value赋入,同时返回旧的值。否则的话,while执行完毕,还没有找到key,那么,执行addEntry函数,将key-value加入到table中。在加入后,进行判断:
if (size++ >= threshold)
resize(2 * table.length);即如果新的容量大于限制值,那么会进行容量扩充的操作,也就是扩充table的大小。新容量是旧容量的2倍。在resize函数中,要生成新的table并设置成新的容量,同时,进行比较重要的操作,即将旧的table中的内容拷贝到新的table中去。在拷贝的过程中,Entry在新的table中的位置是经过重新计算的,所以上文提到的问题不会出现。
get方法
get方法相对put方法很简单,代码如下:
public Object get(Object key) {
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
Entry e = table[i];
while (true) {
if (e == null)
return e;
if (e.hash == hash && eq(k, e.key))
return e.value;
e = e.next;
}
}首先计算hash值,然后调用indexFor函数得到起始的位置,获取该位置上的项,改项即为具有相同hash值的链表的首项。最后使用while循环来遍历这个链表。在循环中,逐个比较如果key也相等了,说明找到了,返回,否则继续找下去。如果没有hash值相等的项了,可以判断为没找到,返回空。
table详细内容
见下图.
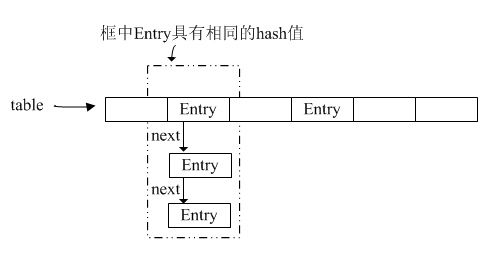
每个key--value对放在Entry对象中。由key计算出的hash值相等的Entry组成一个链表,链表的元素之间使用Entry.next相连,链表的首位置由indexOf计算得到。遍历这个链表即可以得到某个key可能存在的Entry,HashMap也通过这种方式来解决冲突。
一些值得注意的问题
在上文中,我们注意到,如果table容量大于某个限制,那么将要进行扩充。扩充的操作,实际上是新建table,进行拷贝,并且重建Entry链表的过程。这个过程自然是极其耗时的,我们也应该尽量避免这个操作。避免的方法也很简单,就是初始化HashMap的时候,指定一个比较大的容量即可(默认是16). HashMap提供了构造函数 public HashMap(int initialCapacity) 来解决这个问题。
可以看出,无论是在添加的put函数,和获取的get函数,均要遍历冲突的链表,也就是说,如果在HashMap中存在大量的冲突(因为某种原因,key计算出来的hash值重复),那么,HashMap将近似退化为链表的线性查找。这就会比较大的影响性能。这就要求我们仔细设计key对象的hashCode()函数,尽量少的减少不同的key得多相同的hash值的情况(自然,完全不同的hashCode的值是不可能的)
概述
HashMap类位于java.util包中。主要作用是提供了一个Map的实现,可以比较方便的进行 关键字(key) – 值(value)的存取。其主要方法为:
public Object put(Object key, Object value) 加入一个对象。
public Object get(Object key) 获得一个对象。如果没找到对应于key的对象,返回null.
下面着重分析这两个方法。
put方法
put方法的作用是将一个对象(value)加入到map中,它的key为(key)。如果key重复了,将替换掉旧的值,并将旧值返回。如果key没有重复,将新的值插入。该部分代码如下(有删节):
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
if (e.hash == hash && eq(k, e.key)) {
Object oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
addEntry(hash, k, value, i);
return null;首先,程序执行了maskNull函数。该函数很简单,仅仅判断如果key非空,直接返回,否则返回一个new Object(). 接下来,使用HashMap类中函数hash(k)来计算key的hash值(这应该就是这个类被命名为HashMap的原因)。比较有意思的是,hash函数中,并没有直接返回k.hashCode(),而是在hashCode()之上进行了额外的计算。按照该函数的javadoc,这是为了抵御"某些不良设计的hashCode函数"。
再往下,是计算hash值在列表中的起始位置。table就是实际保存值的列表,indexFor这个函数返回的是hash值的在table中的位置。具体含义为,一些key的hash值很可能是相同的(冲突),这些key冲突的key--value所在的项组成一个链表,indexFor函数返回的就是这个链表的首项。而这个indexFor函数极其简单:
static int indexFor(int h, int length) {
return h & (length-1);
}很明显,因为传入的hash值(h)可能为很大的数,所以通过与table的长度做AND运算,保证得到的位置在[0, table.length-1]的区间内。
这就带来一个问题:如果table的长度增加了,那么indexFor函数返回的位置可能就变化了,这就产生了错误。实际上,HashMap是能够避免这个问题的,后文分析。
继续查看put函数的代码。在得到了起始的位置之后,是一个while循环。该循环很简单,依次遍历相同hash值的Entry,如果key也相等,那么将value赋入,同时返回旧的值。否则的话,while执行完毕,还没有找到key,那么,执行addEntry函数,将key-value加入到table中。在加入后,进行判断:
if (size++ >= threshold)
resize(2 * table.length);即如果新的容量大于限制值,那么会进行容量扩充的操作,也就是扩充table的大小。新容量是旧容量的2倍。在resize函数中,要生成新的table并设置成新的容量,同时,进行比较重要的操作,即将旧的table中的内容拷贝到新的table中去。在拷贝的过程中,Entry在新的table中的位置是经过重新计算的,所以上文提到的问题不会出现。
get方法
get方法相对put方法很简单,代码如下:
public Object get(Object key) {
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
Entry e = table[i];
while (true) {
if (e == null)
return e;
if (e.hash == hash && eq(k, e.key))
return e.value;
e = e.next;
}
}首先计算hash值,然后调用indexFor函数得到起始的位置,获取该位置上的项,改项即为具有相同hash值的链表的首项。最后使用while循环来遍历这个链表。在循环中,逐个比较如果key也相等了,说明找到了,返回,否则继续找下去。如果没有hash值相等的项了,可以判断为没找到,返回空。
table详细内容
见下图.
每个key--value对放在Entry对象中。由key计算出的hash值相等的Entry组成一个链表,链表的元素之间使用Entry.next相连,链表的首位置由indexOf计算得到。遍历这个链表即可以得到某个key可能存在的Entry,HashMap也通过这种方式来解决冲突。
一些值得注意的问题
在上文中,我们注意到,如果table容量大于某个限制,那么将要进行扩充。扩充的操作,实际上是新建table,进行拷贝,并且重建Entry链表的过程。这个过程自然是极其耗时的,我们也应该尽量避免这个操作。避免的方法也很简单,就是初始化HashMap的时候,指定一个比较大的容量即可(默认是16). HashMap提供了构造函数 public HashMap(int initialCapacity) 来解决这个问题。
可以看出,无论是在添加的put函数,和获取的get函数,均要遍历冲突的链表,也就是说,如果在HashMap中存在大量的冲突(因为某种原因,key计算出来的hash值重复),那么,HashMap将近似退化为链表的线性查找。这就会比较大的影响性能。这就要求我们仔细设计key对象的hashCode()函数,尽量少的减少不同的key得多相同的hash值的情况(自然,完全不同的hashCode的值是不可能的)