Type 3 Changes
In most dimensional schemas, the bulk of changes to source data generate type 1 and type 2 changes. Occasionally, neither technique satisfies. A third type of change response is called into play when there is a need to analyze all facts, those recorded before and after the change, with either the old value or the new value. Neither type 1 nor type 2 does the job here. Solving this problem by storing natural keys in the fact table renders queries difficult to write and opens the door to serious double-counting issues. The preferred approach is to include two attributes for the changed data element, one to carry the current value and one to carry the prior value. Both are updated when a change occurs. Known as a type 3 solution, this allows either to be used to study the entire history.
Study All Facts with Old or New Dimension Values
During the course of planning the appropriate slow change response for each column in a dimension table, you will occasionally identify an attribute with two seemingly contradictory requirements:
- The ability to analyze all facts, recorded before and after the change occurred, using the new value.
- The ability to analyze all facts, before and after the change occurred, using the old value.
In this situation, neither a type 1 nor a type 2 response is sufficient to keep everyone satisfied. This is best understood in the context of an example.
For example, there were just two regions: East and West. As the company grew, these groupings became insufficient. What began as the East region was broken down into two regions: Northeast and Southeast.When changes like this occur, management begins using the new designations immediately.
Management also needs to hang onto the old designations, at least for a little while, in order to compare this year’s performance to what was reported for the previous year. The requirements for managing changes to a customer’s region are enumerated as follows:
- The ability to use the new regions to analyze all facts, whether recorded before or after the changeover
- The ability to use the old regions to analyze all facts, whether recorded before or after the changeover
The first requirement allows managers to move forward with the new groupings immediately. All order history can be grouped into the new Northeast and Southeast categories. The managers can do “this year versus last” comparisons as if the new groupings had always been in place. The second requirement allows the company to move forward using the old groupings. All orders can be grouped under the old value (East) as if it had never changed. This permits the results for the current year to be reported externally in a format consistent with the way in which forecasts were provided.
Previous Techniques Not Suitable
Neither a type 1 nor a type 2 response is able to address both these requirements. On its own, the first requirement can be satisfied with a type 1 change, overwriting the old value with the new value. A customer in the region “East,” for example, is updated to show “Northeast.” The new region value is, therefore, associated with all facts in any associated fact table—both those recorded before the changeover and after the changeover. Unfortunately, the type 1 response does not meet the second requirement, which calls for the old value to be available. A type 1 change wipes away the previous value of the attribute, as if it never existed. There is no record that the customer whose region has been updated to “Northeast” was ever classified as being in the region “East.”
A type 2 response fares worse; it is not able to meet either requirement. A type 2 response associates each fact with the version that was current at the time it was recorded. Hence, the old region value (East) is associated with facts recorded prior to the change, and the new values (Northeast, Southeast) are associated with facts recorded after the change. These new values cannot be used to analyze past history, conflicting with the first requirement. The old values cannot be applied to facts recorded after the change, conflicting with the second requirement.
The Type 3 Solution
When requirements call for using the old or new values of a changed attribute to study all facts, a type 3 response is used. A pair of attributes is modeled, one attribute for the current value and one for the previous value. When a change occurs, both columns are updated; no rows are added. Users can employ either column in their analysis as desired. The process is repeatable, and the solution can be extended if multiple versions of the changed attribute are required.
A Pair of Attributes, Both to Be Updated
When a dimension attribute is singled out for type 3 treatment, it is modeled as a pair of columns. One column is designated to hold the current value; the other is designated to hold the old value. In the case of customer regions, they might be called region_current and region_previous, as depicted below figure.

When a change to the source value occurs, both attributes are updated. The new value is placed in the column representing the current value; this is a standard type 1 response. The old value is moved to the column representing the previous value. No additional rows are created. Since each fact is linked to a single dimension row containing both values, it is possible to create reports that use either value to group all data.
The Type 3 Change in Action
The mechanics of a type 3 change are illustrated below Figure. In this example, customers in the region called “East” are redesignated as belonging to regions called “Northeast” or “Southeast.” The top half of the diagram shows the state of affairs before the change. Several rows from the customer dimension table are shown. Notice that region_current
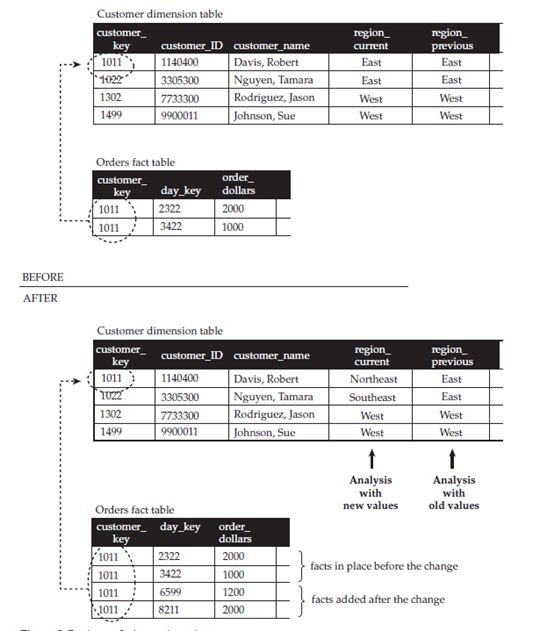
contains each customer’s region—”East” or “West.” There have been no changes yet, so the region_previous is initialized to contain the same values. In the fact table, two rows have been recorded for the customer identified by customer_key 1011. Tracing this back to the customer dimension, you can see that these orders were placed by Robert Davis, who is in the region “East.”
Now suppose that the business decides to change the regional groupings. The region that was formerly known as East will be subdivided into Northeast and Southeast. For each customer who was in the East region, a type 3 change occurs. The region_current is updated with the new values. The result can be seen in the above Figure. Robert Davis now has a region_current of “Northeast.”The two orders that Robert Davis placed before the change are still in the fact table. In addition, Robert has placed two additional orders since the change occurred. All four rows are associated with the same row in the dimension table, identified by surrogate key 1011.
This solution allows you to employ either version of the region categorization in queries or reports, simply by using the appropriate column. When you want to study orders using the new scheme, you group order_dollars by region_current. This causes all the orders from Robert Davis to be rolled up under the designation of “Northeast,” whether they were recorded before or after the change. When you want to study orders using the old scheme, you group order_dollars by region_previous. Robert’s orders now appear under the grouping for “East,” regardless of when they occurred.
Tip A type 3 response associates the old and new values of the changed attribute with all transactions.
Two dimension attributes are required. One will hold the current value; the other will hold the previous
value. When the source changes, both are updated
Notice that the region_current attribute provides a standard type 1 response to the changed data. It always contains the most recent value; it is always overwritten when the value changes. For this reason, the region_current column can be designated as a type 1 attribute in design documentation if you prefer. You may even prefer to think of the change as a type 1/3 change to region. Designating the attributes that produce a type 3 response as a pair, however, may be more useful in communicating to ETL developers how changes should be processed.
It is important to recognize that a type 3 change does not preserve the historic context of facts. Each time a type 3 change occurs, the history is restated. There is no way to know, for example, what region Robert Davis was a part of when a particular order was placed. This requires a type 2 approach. Type 2 and type 3 responses can be combined, in a hybrid response known as type 1/2/3.
Type 3 changes are comparatively rare, but they are occasionally warranted. Redistricting and geographic realignments are the most common examples. Finance and accounting groups often designate new names or classifications for accounts on an annual basis. Such cases have the lucky distinction of occurring at predictable intervals, although this is not always the case.
Repeatable Process
A type 3 change is not a one-time-only process. It can be repeated once, twice, or as many times as needed. Robert Davis’s region, for example, may subsequently be changed again. Perhaps as a result of redrawing the region boundaries, he is redesignated as being in the Southeast. When this occurs, what was formerly in region_current (Northeast) is moved to region_previous. The new value (Southeast) is placed in region_current.
A type 3 change preserves only one old version of the changed attribute. Once a second change occurs, the fact that Robert Davis was once in the East region is lost. In some cases, it may be useful to maintain multiple values. This can be done by designating three, four, or however many versions of the region column are required. Each time a change occurs, the values are all shifted among these columns.
With multiple versions, the columns can be difficult to name. If the changes occur on a predictable basis, they might be named region_2009, region_2008, region_2007, and so forth. This approach has two distinct disadvantages. First, it requires the DBA to periodically change the names of columns. For example, if requirements call for the current version and the two previous versions, it is necessary at the end of 2009 year to drop the 2007 column and add one for 2010. Second, encoding the year into the column names means new queries and reports will need to be designed each year to refer to the new column names. An alternative that avoids these drawbacks is to name the columns region_current, region_last_year, and region_two_years_ago.
Special Scheduling Not Necessary
The type 3 change is often misunderstood as requiring special advanced scheduling. Although developers may take advantage of the predictability of a type 3 change and handle it with a special process, this is not strictly required. As with any other slow change processing, it is possible to design an ETL process that looks for changes to the attribute in question and applies them if and when they are detected. All that is necessary is to anticipate the possibility of the type 3 change and engineer the ETL process accordingly. There may be good reasons to handle a type 3 change via a special process.
• In most cases, type 3 changes occur en masse. A change to the region designations, for example, may affect every customer in the dimension table.
• The information that drives a type 3 change may come from a separate source or involve special rules. Region designations, for example, may be driven by a spreadsheet that maps to Zip codes.
• A type 3 change with multiple versions may involve renaming database columns and developing new reports. Its implementation must be coordinated with these activities.
• The change may occur on a predicable basis, in which case it is not necessary to monitor for it as part of standard processing.
For any of these reasons, it may be useful to handle the type 3 change through a separate scheduled process. This is not mandatory, but it may be convenient for processing purposes.
Documenting the Type 3 Change
When it comes to documenting a type 3 change, designers have varying preferences. In figure above, each attribute is designated as a surrogate key, as a natural key, or according to its slow change characteristic. The type 3 attribute pair is highlighted and labeled as type 3.
As noted, you may prefer to designate the current member of the attribute pair as a type 1 attribute, since it behaves in exactly the same way as any other type 1 attribute. Modeling tools often impose limitations on how you can document the slow change behavior associated with an attribute. Some dimensionally aware modeling tools allow you to note slow change characteristics, but most tools will not let you highlight a pair of type 3 attributes. Naming conventions and comments may be your only route to associating them.
Some modeling tools do not include the concept of a type 3 change, limiting your options to type 1 and type 2. Using these tools, you may be forced to label both members of the attribute pair as type 1. This will require some careful annotation to distinguish each attribute’s purpose. You may convey the behavior of the attribute containing the previous value by noting its data source is the attribute that holds the current value.
参考至:《Star Schema The Complete Reference》
本文原创,转载请注明出处、作者
如有错误,欢迎指正