基于HIVE文件格式的map reduce代码编写
by hugh.wangp
我们的数据绝大多数都是在HIVE上,对HIVE的SEQUENCEFILE和RCFILE的存储格式都有利用,为了满足HIVE的数据开放,hive client的方式就比较单一,直接访问HIVE生成的HDFS数据也是一种必要途径,所以本文整理测试了如何编写基于TEXTFILE、SEQUENCEFILE、RCFILE的数据的map reduce的代码。以wordcount的逻辑展示3种MR的代码。
其实只要知道MAP的输入格式是什么,就知道如何在MAP中处理数据;只要知道REDUCE(也可能只有MAP)的输出格式,就知道如何把处理结果转成输出格式。
表1: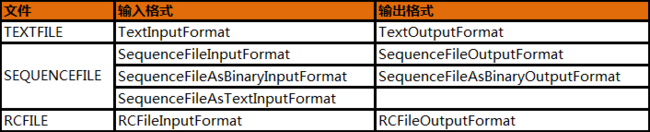
如下代码片段是运行一个MR的最简单的配置:定义job、配置job、运行job
//map/reduce的job配置类,向hadoop框架描述map-reduce执行的工作
JobConf conf = new JobConf(WordCountRC.class);
//设置一个用户定义的job名称
conf.setJobName("WordCountRC");
//为job的输出数据设置Key类
conf.setOutputKeyClass(Text.class);
//为job输出设置value类
conf.setOutputValueClass(IntWritable.class);
//为job设置Mapper类
conf.setMapperClass(MapClass.class);
//为job设置Combiner类
conf.setCombinerClass(Reduce.class);
//为job设置Reduce类
conf.setReducerClass(Reduce.class);
//为map-reduce任务设置InputFormat实现类
conf.setInputFormat(RCFileInputFormat.class);
//为map-reduce任务设置OutputFormat实现类
conf.setOutputFormat(TextOutputFormat.class);
//为map-reduce job设置路径数组作为输入列表
FileInputFormat.setInputPaths(conf, new Path(args[0]));
//为map-reduce job设置路径数组作为输出列表
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
//运行一个job
JobClient.runJob(conf);
而此刻,我们更多的是关注配置InputFormat和OutputFormat的setInputFormat和setOutputFormat。根据我们不同的输入输出做相应的配置,可以选择表1的任何格式。
当我们确定了输入输出格式,接下来就是来在实现map和reduce函数时首选对输入格式做相应的处理,然后处理具体的业务逻辑,最后把处理后的数据转成既定的输出格式。
如下是处理textfile、sequencefile、rcfile输入文件的wordcount代码,大家可以比较一下具体区别,应该就能处理更多其它输入文件或者输出文件格式的数据。
代码1:textfile版wordcount
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class WordCountTxt{
public static class MapClass extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCountTxt.class);
conf.setJobName("wordcounttxt");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(MapClass.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
代码2:sequencefile版wordcount
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.SequenceFileAsTextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCountSeq {
public static class MapClass extends MapReduceBase
implements Mapper<Text, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Text key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
JobConf conf = new JobConf(WordCountSeq.class);
conf.setJobName("wordcountseq");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(MapClass.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(SequenceFileAsTextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
代码3:rcfile版wordcount
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.ql.io.RCFileInputFormat;
import org.apache.hadoop.hive.serde2.columnar.BytesRefArrayWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCountRC {
public static class MapClass
extends MapReduceBase implements Mapper<LongWritable, BytesRefArrayWritable, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word =new Text();
@Override
public void map(LongWritable key, BytesRefArrayWritable value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
Text txt = new Text();
txt.set(value.get(0).getData(), value.get(0).getStart(), value.get(0).getLength());
String[] result = txt.toString().split("\\s");
for(int i=0; i < result.length; i++){
word.set(result[i]);
output.collect(word, one);
}
}
}
public static class Reduce
extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator<IntWritable> value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
int sum = 0;
while (value.hasNext()) {
sum += value.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
/**
* @param args
*/
public static void main(String[] args) throws IOException{
JobConf conf = new JobConf(WordCountRC.class);
conf.setJobName("WordCountRC");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(MapClass.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(RCFileInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
原始数据:
hadoop fs -text /group/alidw-dev/seq_input/attempt_201201101606_2339628_m_000000_0
12/02/13 17:07:57 INFO util.NativeCodeLoader: Loaded the native-hadoop library
12/02/13 17:07:57 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
12/02/13 17:07:57 INFO compress.CodecPool: Got brand-new decompressor
12/02/13 17:07:57 INFO compress.CodecPool: Got brand-new decompressor
12/02/13 17:07:57 INFO compress.CodecPool: Got brand-new decompressor
12/02/13 17:07:57 INFO compress.CodecPool: Got brand-new decompressor
hello, i am ok. are you?
i am fine too!
编译打包完成后执行:
hadoop jarWordCountSeq.jar WordCountSeq /group/alidw-dev/seq_input/ /group/alidw-dev/rc_output
执行完毕就能看到最终结果:
hadoop fs -cat /group/alidw-dev/seq_output/part-00000 am 2 are 1 fine 1 hello, 1 i 2 ok. 1 too! 1 you? 1