最近在公司调研消息中间件,参考metaq设计总结了需要focus的点
1 项目背景
消息队列作为中间件核心的产品,在电商平台体系中扮演着异构系统解耦、数据同步等极其重要的作用,目前公司采用了开源的rabbitMq,存在以下几个问题:
(1) erlang语言,学习成本高,出现问题难以把控,基本是黑盒
(2) 消息数据的完整性、实时性无法得到保障
(3) 不支持批量操作,吞吐量不高
(4) 对事务支持薄弱,难以使用
(5) 负载、水平扩展、消息堆积、容灾恢复等有待验证
基于上述原因,为更好服务满足业务发展,也为相关技术储备和沉淀,vq项目应运而生(其中v指代微店,q即消息队列messageQueue的缩写)
2 业务描述【可选】
(1)电商平台各系统异步解耦。比如下单减库存,由交易平台发送一个订单创建成功消息到商品中心,商品中心根据订单商品进行减库存操作
(2)数据同步,如主从一致性,将master的数据丢入消息队列,slave从队列中获取消息进行更新
(3)搜索引擎增量,从db的binlog增量解析到实时更新引擎,中间数据通过消息队列保存
(4)离线或定时调度任务,通过消息机制传递
1 系统方案
3.1名词解释
l 消息主题topic:消息的识别属性,一般同类消息具有相同的topic,比如商品中心发出的消息为itemcenter
l 服务broker:消息服务端,包括消息路由、存储,基于zk进行分布式服务协调,是消息生产者和消费者之间的中间人
l 发布者producer:消息的生产端,按一定主题发送到broker
l 消费者consumer:消息的消费端,分主动pull和被动push两种模式
l 分区partition:消息主题的数据分片,单个broker服务器可以包括多个topic消息的partition数据,同一topic的不同partition也可以跨多个broker存在
l 消费组group:多个消费者组成一个消费组共同消费同一topic消息,消息被组中任意消费者消费成功即认为消费成功,
l 消费偏移offset:对于消费者而言,消费偏移量纪录了当前已消费的位置信息,是相对于partition文件的逻辑偏移量,会持久化保存以便失败恢复
3.2总体解决方案

图3.1.1 总体设计

图3.1.2 broker设计
broker拥有的核心组件
l Dispatcher
实现数据的缓存、交换、路由分发,参考disruptor。并维护自身状态的生命周期,负责与zk交互信息等
l ChannelGroup
一组channel的集合,channel可以看作是数据流的通道,通过该通道数据最终被写入磁盘。Channel实现了pipeline模式,具有filter过滤和消息确认机制
l Storer
负责将消息从内存刷进磁盘,采用mmap方式提高性能
关于消费端push/pull模式的对比选型
| |
push |
pull |
| 实时性 |
好,数据产生即可发送 |
一般,取决于pull的时间间隔 |
| 状态保存(服务端、客户端均可) |
需要知道哪些推送成功,哪些推送失败 |
保存拉取的信息以便故障恢复 |
| 负载 |
在服务端无法满足客户端处理能力情况下需流控,无效push对服务端有负载 |
对客户端空的请求或无效数据传输会浪费服务端带宽和处理能力 |
| 可靠性 |
差,被动接受 |
高,主动控制 |
出于简单、稳定的原则,消费端采用pull模式
服务层:zookeeper+quartz
内核层:disruptor+hessian2/protobuf
网络层:netty/zeroMq
控制台:webx、mysql
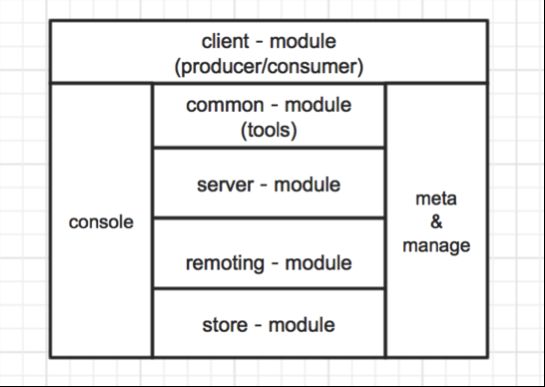
图3.2 模块分层及依赖
client:客户端以二方包形式提供给业务使用,包括producer和consumer的api接口
common:通用tools、领域模型定义、配置常量等
server:服务端broker核心逻辑
remoting:高级封装的网络通用组件
store:消息存储组件
console&meta manage:统一的监控发布、元数据维护管理平台
略
略
3.3模块详细设计
(1)分布式集群
publisher:业务集群的多台机器可以发送同一topic的消息
broker:多台服务器可以组成集群为同一topic消息服务,其中publisher按一定分布规则发送消息,consumer拉取消息进行消费
consumer:业务集群的多台机器可以组团消费同一topic消息,它们具有相同的分组名
(2)负载均衡
假设topicA下有5个partition,分散在3台broker服务器上,另外包括两个发布者,两个组名为groupB的消费者,如下图所示:
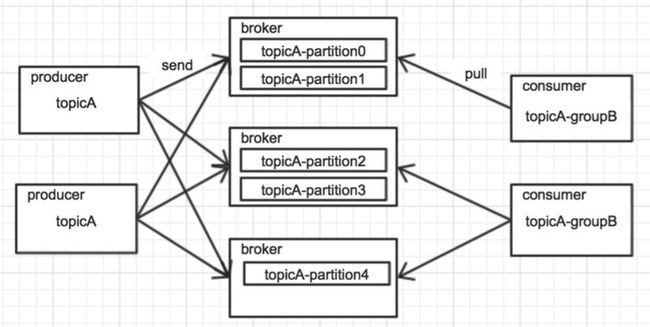
图3.3 分布式集群下的负载均衡
broker
可以把每个broker看作一个容器资源,启动的时候向zk注册自己。业务在申请资源的时候通过console分配broker,并根据业务吞吐量、延时等需求考虑资源最优调度。调度中有个强需求就是不同的业务topic相互隔离,一是可以独立划分broker集群;二是定向调度,如商品中心的消息只放在集群中指定broker服务器上
如上图所示,主题为topicA的消息被分配到3台broker上,partition序号为0-4,这些元数据都保存在zk上。producer在启动的时候会将这些元数据同步到本地,并watcher数据做到动态变更
producer
producer将同步的broker信息根据topic组成一系列的partition列表,采用一定负载策略向这些partition列表发送消息,主要的策略有以下几种:
(1) 轮循RR:partition列表按字典序排列成一个首尾相连环形队列,每次发布消息从队列中选择next partition进行发送,依次往返进行
(2) 业务id hash:根据“业务主键% partition num=partition index”,如有商品itemId为1001,对上述topicA计算1001%5=1,即得到partition1的broker地址
(3) LRU:类似“最近最少使用”原则,producer在发送前通过计算选择topic下“最少使用”的partition。当然这里的“最少使用”具有一定的语义扩展,比如可以是存储消息量最少的partition,或是吞吐量最高的partition,甚至可以是所在broker系统负载最低的partition
轮询RR是简单高效的负载方式,可以满足绝大部分业务需求,系统应提供默认支持。而对于hash和LRU,可以预留接口,让业务可以根据具体场景自行实现
consumer
在pull模式下,集群中的每个消费者可以任意选择partition拉取数据。假设partition数为n,消费集群规模为m,
a) 若n >= m,则每个消费者最少消费n/m个partition,最多消费n/m + 1个partition
b) 若n < m,则存在m - n个消费者无需拉取partition,剩下的每个消费1个partition
支持以下两种模型
(1) p2p端到端
(2) publish/subscribe发布与订阅
(1) 过滤
分为broker端和consumer端,由producer增加消息tag标签。broker端过滤可以减少网络数据的传输量,但增加了服务端系统开销。consumer端过滤则相反,将计算逻辑搬移到消费者
(2) 压缩
支持参数配置,建议当消息内容超过一定大小限制(如128k)才使用,默认不开启
在分布式环境下要保证消息的严格顺序很难,原因如下:
a) 首先是producer,如果多个producer同时向一个partition发送数据,由于网络延迟的存在有可能先发送的后到,导致消息在存储时就已经乱序了,更别说后续的消费
b) 其次是consumer,考虑只有一个partition情况
集群消费,消费顺序因网络环境、不同消费者自身的处理速度无法得到保证
即使是单个消费者,若采用批量并发的消费方式,最终的顺序也因并发过程无法保证
c) 再者就是broker集群,当顺序消息分布在跨机器的多个partition中,对于消费者而言本身就已经变得无序了
综上所述,要实现分布式环境下的消息顺序性,前提条件必须是单produer向单partition发送,并在consumer端进行单消费者单线程消费。这对系统吞吐量带来极大伤害,只有极其苛刻的场景下才考虑使用
(1) 顺序写,随机读
参考3.5消息存储结构
(2)刷盘策略
a). 批量大小,每1000条消息调用一次系统IO写入磁盘
b). 定时,每10s调用一次系统IO将内存数据写入磁盘
以上两种方式,无论哪种达到阈值都强制执行刷盘,阈值大小支持参数化配置
(3)已消费历史数据的删除,每天晚上凌晨2点对昨日文件进行归档压缩(zip)处理,删除服务器上3天前的历史数据
(1) publish可靠消息
从逻辑上看,只有将publisher的数据写入broker对应partition磁盘文件才认为该数据的发布是可靠的。Ack机制是broker接受数据并响应publisher,表明数据已收到并落盘的过程。
如果是同步ack,则每发送一条消息后都会等待这条消息被成功落盘的回应;更常用的是异步ack,publisher发送消息后不用被动等待,只是维护已发送的消息集合,待broker处理成功后将对应消息从保留集合中删除即可。
为防止响应时间过长需对已发送的消息作超时处理,超过时间阈值还没有得到响应的消息自动认为失败,对于失败的消息,应重新发送
考虑服务器断电,broker的缓存数据将丢失,但这些数据还没有被写入磁盘没有被ack,pushliser会在timeout后重新发送,所以ack机制也可以防止这种极端情况下的数据丢失
(2) consume可靠消息
对于consume消费失败的情况,优先采用重试(默认3次);若重试仍失败,则跳过失败的消息继续消费,将失败的消息纪录在consumer本地,并结合日志予以提示
(1) publish
当broker成功写入消息返回ack时,由于网络原因ack没有被publisher成功接收到,导致消息被重复发送并写入。这种情况是由于网络等不可控因素造成的,系统无法避免
(2) consume
对于消费者,成功消费的消息会以offset位点的形式纪录。通常的纪录方式有
a) zk:存在zk节点上,节点类型是持久化persistent
b) mysql:单独的数据表进行存储
如果成功消费了一批数据,但在更新offset时由于服务器crash掉,重启后仍以没更新的位点进行拉取数据,则会出现重复消费的情况
包括本地事务和分布式事务,分布式事务参考 JTA规范,具体实现待研究
考虑broker的master/slave结构来实现服务的高可用,master和slave的broker包含的topic及partition完全一样,任务时刻只有一个处于服务状态,即master;而另一个处于待命状态,即slave。master和slave为了保持数据一致性,需要进行复制
a) 同步复制:publisher同时发送消息到master和slave,任何一个失败则失败,数据一致性最高,但可用性降低
b) 异步复制:publisher只发送消息到master,master采用异步线程复制数据到slave,存在数据不一致的风险,但可用性高
failover
当master crash掉后,slave顶替上来成为master继续服务,down掉的master恢复后自动成为slave作为备选,并向新的master同步数据。在这个过程中,若采用异步复制有可能会出现数据不一致的情况。比如最终down掉的master数据还未来得及复制到slave上,则新的master数据不完整
3.4消息结构化数据
| 字段 |
说明 |
| id |
消息唯一id,由系统自动生成 |
| topic |
消息主题,标志同类型消息 |
| tag |
消息过滤标签,业务可根据该字段对消息进行过滤 |
| content |
消息内容,消息传输的有效负载,长度限制1M |
3.5消息存储结构
参考metaq设计
- message length(4 bytes),包括消息tag和content,理论能容纳232大小数据,实际已超过4g
- checksum(4 bytes)
- message id(8 bytes)
- message flag(4 bytes)
- tag length(4 bytes) + tag,可选
- payload,有效负载,限制不超过1M
checksum采用md5算法,计算包括tag length + tag + content,tag为空则不参与计算。消息在consumer端会根据checksum进行数据验证
一个partition包括多个block文件,文件是顺序写随机读的,任何时刻只有一个文件在写,其它的可读。当一个文件达到预定阈值后就切换到新文件写。因为文件是顺序写的,所以可以根据递增偏移量命名文件,如topicA下的partition0拥有如下block文件:
0000000000000000.block
0000000000001024.block
0000000000002048.block
…
如上,每个文件的存储大小是1024bytes,0000000000001024.block存储了partition0从第1024个字节到第2047的byte数据。对于这样的存储方式, offset能快速定位查询,比如当前offset为1536,通过二分查找发现1536介于[1024,2048]之间,即从0000000000001024.block文件中的第1536-1024=512个byte开始获取数据,最终传输大小根据consumer传入的length判断是否需要跨文件读取
3.6客户端API
//消息工厂接口,负责发布者或消费者的创建,单例模式
public interface MessageFactory {
//根据配置初始化factory
public void open(MessageFactoryConfig messageFactoryConfig);
//根据配置创建消息发布者,配置中可指定是否需要ack,是否需要严格保证顺序性等
public MessageProducer createProducer(ProducerConfig producerConfig);
//根据配置创建消息消费者,配置中可指定offset
public MessageConsumer createConsumer(ConsumerConfig consumerConfig);
//获取所有broker的状态信息
public Map<InetSocketAddress, StatusResult> getStatus();
//获取指定broker的状态信息
public StatusResult getStatus(InetSocketAddress addr);
//查询指定topic的所有分区信息
public List<Partition> getPartitionsForTopic(Topic topic);
//关闭factory
public void shutdown();
}
//消息发布接口
public interface MessageProducer {
//返回发布者配置
public ProducerConfig getConfig();
//申明发布的topic,向zk同步broker信息
public void publish(Topic topic);
//同步发送消息
public SendResult sendSync(Message message);
//同步发送消息,设置超时时间
public SendResult sendSync(Message message, Timeout timeout);
//异步发送消息
public void sendAsync(Message message, Callback callback);
//异步发送消息,设置超时时间
public void sendAsync(Message message, Callback callback, Timeout timeout);
//开始事务
public void beginTransaction();
//提交事务
public void commit();
//回滚事务
public void rollback();
}
//消息消费接口
public interface MessageConsumer {
//返回消费者配置
public ConsumerConfig getConfig();
//拉取传入partition指定位点的消息
public List<Message> get(Topic topic, Partition partition, Offset offset, Long length);
//拉取传入partition指定位点的消息,设置超时时间
public List<Message> get(Topic topic, Partition partition, Offset offset, Long length, Timeout timeout);
//订阅消费指定topic的消息
public MessageConsumer subscribe(Topic topic, Long length, MessageListener listener);
//订阅消费指定topic的消息,设置消息过滤器
public MessageConsumer subscribe(Topic topic, Long length, MessageListener listener, MessageFilter messageFilter);
//获取指定topic的位点信息
public Offset getOffset(Topic topic);
}
3.7消息时序图
略