我眼中的云端架构
文章转自http://www.infoq.com/cn/articles/xw-cloud-in-my-view
在看阿凡达的时候,感叹着他们接口的统一,和获取知识的便利性。有时候在想,现在很多企业所做的工作,不就是要提供这类服务吗。设想一下,我们有一朵公有云,存储了用户的数据、逻辑关系,提供标准的通讯接口,然后大家各自开发丰富的展现逻辑,让云端变的丰富多彩。这次很荣幸能接到这个议题,谈谈我个人对这朵云的理解。
我们需要的云端服务每个人心中都有自己的一朵云,在我设想中,应该存在这么一种公有服务,它能够帮助用户随时随地的获取自己的数据,与朋友交流,获取好友最新状态。在这服务之上,我们有这么一个平台,它能够给用户提供二次开发的接口,让开发者根据用户数据开发丰富的展现层,并且提供这些展现层的运行平台。
为了完成这个功能,我们需要什么准备?
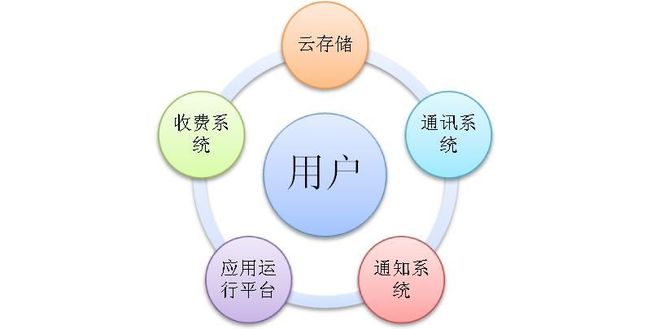
云存储:提供用户数据的存储功能。让用户方便的获取自己的数据。
通讯系统:提供以Mail,IM为基础的通讯方式
通知系统:好友行为推送,能够把握好友最新动态,或者告知好友你在干什么。
在这三个基本服务之上,用户可以开发大量的运用。比如“音乐盒”用于在线播放云存储的MP3,图片系统用于管理、分享,美化自己的照片……然而,用户开发完逻辑应用之后,需要机器运行这个运用。因此,第四个基本服务运行平台孕育而生,它提供所有云应用运行的基本资源,包括内存、CPU、操作系统等。
这四个基本要素构建成一个面向终端用户的操作系统平台(也就是我们的云),它能够随时被访问,通过浏览器或者手机的App。满足用户在任意时刻团购,玩三国杀,看视频,听音乐等需求。为了方便开发者开发更多的应用,我们抽象一种编程模式,提供丰富的SDK,加速运用的开发。由于云端服务,有很大一部分会被手机等嵌入式设备访问,于是需要各种平台的编程框架(android、IOS)。编程框架将更加关心业务逻辑,屏蔽分布式细节和运维问题。
在满足这些开发便利性的前提下,为鼓励用户开发,提高APP质量和数目,需要一套良好的收费系统,帮助开发者更好的盈利。
围绕这这朵云,一点点的展开,发现想说的东西太多,今天我们就谈谈其中的两个核心架构:云端存储和运用运行平台(App Engine)。为什么要选这两个?因为云的核心就是存储和计算,其它都构建在存储和计算之上的基础服务和用户运用。
云端存储架构
云端存储主要是为了存储用户数据,方便用户访问。它涉及了三方面的技术
- 底层架构。包括:分布式存储、文件目录管理、用户权限系统
- 下载优化:各地CDN支持、客户端下载技术(P2P)
- 数据访问前端优化
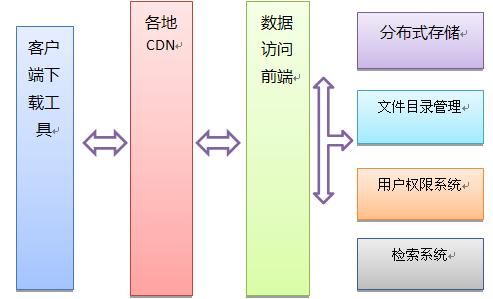
底层架构设计的要点
首先我们比较一下跟传统离线存储的设计指标差异
- 单个文件体积不大
- 文件数会很多
- 需要目录管理
- 读写模式特殊性
- 检索和访问的实时性
存储互联网用户的数据,注定文件不会很大。我们只要支持0-100G左右的单文件大小即可。为什么用户文件会到100G?因为我们要保证用户能分享高清电影。另外相对于海量的容量,如果单文件过小,那么海量空间也没啥意义。多媒体是促进磁盘发展的动力。
跟GFS不一样,云存储的文件数是海量的。因为每个人都会存储他们的文档、mp3、图片……这注定了单机保存全部文件的node是不可能的。
我们需要呈现传统操作系统类似的目录管理方式。另外根据云存储文件数量多的特点,我们要提供可靠的检索做文件管理。
用户对文件的访问模式是一次写入,多次读取,读取支持随机位置的读取(比如视频从中间开始播放)等。另外考虑在用户带宽条件下,100M的文件也算是大文件了,我们要需要支持断点续传功能。另外,存在对单文件的高并发访问。
用户上传的数据,在上传成功之后,就应该能访问到完整的数据。并且在检索的时候就能够体现出来。因此不仅要求存储系统要求实时性,而且检索系统也有要求实时性。
归纳一下,因为文件太小导致文件数过多,需要专门的目录存储;针对文件的访问模式,我们需要设计一个比较合理的文件格式;提升检索的实时性。
文件格式介绍
一个文件需要的存储数据:Meta信息和数据块。Meta信息存储这个文件的详细信息,包括文件名、大小、文件类型(doc或者mp3)、MD5、创建者、具体数据块的存放位置、数据块大小,以及该文件格式的版本信息等。数据块是真正存储的文件数据。
我们将一个完整的文件,物理切成多块。比如一个1G的文件,我们按照1M为块大小,切成1024块,然后将1024个块数据散列到N台机器中去。从而保证文件具备高并发的特点,而且也能够方便的为整个集群提供扩展能力。然后我们会将这1024个块的具体位置记录到文件的meta信息中,方便访问。
因此,我们需要一个逻辑文件的访问入口(WebServer),和存储这些数据块与Meta信息的集群Chunk Cluster和Meta Cluster。

将一个不大的文件分散到各台机器上存储有什么好处?
- 方便做负载均衡和集群扩容
- 将热门文件的流量分散到各台机器上,使热门文件的高频访问对后端影响降低。
这个文件格式的设计,大家可能会觉得文件很大的话,Meta信息因需要存储的块位置而导致体积过大。其实这个问题,可以通过二级索引块来解决。
存储架构的工作原理
如上图,WebServer在接收Http请求的时候,会解析参数,然后根据Meta Cluster提供的Meta信息,读取相关块,返回给请求者。Chunck Cluster和Meta Cluster的设计都是一样的,就是提供一套NoSQL系统,支持针对Key(字符串) - value(二进制)的增删改查。但是考虑到访问频率的不同,我们需要针对不同的硬件做单机的优化,比如廉价的Sata盘存放相对静止的数据,SSD盘存放访问频率过高的数据。
NoSQL集群不是我们这篇文件要简述的话题,有机会可以详谈。不过即使是分布式系统,我们也应注重模块的单机性能。因为如果我们的模块单机性能提高一倍,那么我们的集群规模就会下降一倍。在上万台机器中,节约的成本是非常可观的。我们如何衡量这个存储系统的单机引擎性能呢?方法很简单,如果一个单机模块,能够将网卡吞吐跑满或者磁盘顺序读写吞吐跑满,对于存储模块本身来说,可以了。
目录管理系统实现
海量文件的目录管理,很难。这里,我们采用一个分布式有序表的方式来解决,分布式有序表也是NoSQL的一种。它对存储的数据,提供基于字典序的游标查询。比如:我们将所有的用户文件名放入有序表中,该系统就会产生根据文件名排序的分布式数组,如下:
[/a.doc; /a/a.doc; /a/b.doc; /a/c.doc; /b.doc; /b/b/b.doc]
在执行ls /a/命令的时候,我们会寻找/a/的游标得到/a/a.doc,接着我们开始遍历这个游标,直到不是/a/打头为止。如果该过程中碰到子目录,程序会会通过二分查找直接跳过子目录,从而防止遍历过多。如果数目过多,我们会展现100条,其它隐藏。目录管理,主要是给用户组织自己数据的时候用的,理论上,用户不会在一个目录下放太多的文件,即使太多,也没关系,我们就显示100条,然后提供下一页的按钮(因为下一页的游标位置我们是知道的)。
实时检索系统
讨论这个议题的时候,需要假设我们已经有一个传统的检索系统,然后想办法提高检索的实时性。我们设计一个内存索引,把用户新增的文件,对文件名切词后放到内存中检索,检索的结果参与最终的合并。每隔五分钟merge到传统检索系统中,然后释放内存。云存储,不像互联网网页,在5分钟之内,仅文件名的索引,数据量不可能太大,所以内存不会是瓶颈。进一步的,我们可以对文件的内容作检索,但是文件内容没有必要做到实时。
权限系统
用户权限系统,对于云存储来说,也是个用户文件,所以没什么特别的,只不过我们需要专门的缓存做访问优化。因为每一次读写请求,都要判断访问者是否有相关的权限。
CDN技术
P2P技术和CDN支持,主要是为了减少带宽成本而做的,在云存储这种数据量巨大的服务中,这两种技术,显的尤为重要。这两块是两个专题,我们在这里不多做介绍。不过这两个技术在解决热点问题效果比较好,但是海量文件并不是所有文件都放CDN的,因此有些工作,数据访问前端不得不做。
数据访问与客户端优化考虑
客户端访问速度差别,是我们要考虑的问题。如果是内部的访问,带宽可以保证是1000M以上,但是面向互联网用户,各种各样的带宽需求都有,比如GPRS、3G、ADSL,从20k-16M不等。这就要求我们的前端技术,在处理这些请求下要工作的很好。另外我们还要考虑在正常服务下,网络带宽最小化,比如一个视频是100分钟,我们就应该保证100分钟内传完,满足正常播放,不能太快,因为太快,你不能保证用户有耐心看完,可能他就看10分钟,然后就关了,于是后面传输的带宽全浪费了。如果是用户下载,那么当然是越快越好。这些控制,我们都通过WebServer来实现。
WebServer最主要的功能就是高并发支持,限速。再加上云存储的数据是海量的,传统的Apache做WebServer肯定不适合,这里我们采用异步的WebSever比如lighttpd或者nginx,然后对客户端句柄进行速度控制。为了支持大文件的断点上传,我们需要有一个专门的客服端,能够将文件分块上传。Webserver必须支持根据md5查询这个文件哪些块已经上传了,哪些没上传,从而通知客户端正常工作。
云存储有很多节约带宽的优化,比如上传文件的时候,先上传md5,如果云端已经存在,就不需要上传了,这样可以做到大文件的秒传,节约网络带宽。另外它提供对外标准的Http协议,可以采用迅雷等p2p软件下载,从而提高访问速度,减少服务器带宽冲击。为了数据安全性,我们还得提供https协议的数据访问。
App Engine
完成云存储的设计之后,我们需要一个开发平台,这个开发平台提供用户逻辑的运行环境。这环境包括
- MYSQL集群化管理
- 离线任务的处理
- PHP的运行环境
MySQL集群化管理
因为云存储没有提供关系数据的存储功能,为了降低用户的开发门槛,我们需要一个MYSQL的集群化来完成类似的功能。MYSQL的集群化,主要是完成MYSQL读写分离和主从同步功能。
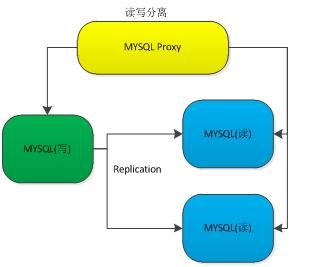
通过这种架构,保证了开发者不需要关心MYSQL的数据故障等问题。因为MYSQL Proxy会自动的进行主从切换和读写分离。这里我们要开发的就是解析SQL语句,完成相关的用户认证,并完成相关的后台转发、接收。
MYSQL的集群化管理没有解决分布式的问题,这个地方我们认为不需要解决。因为互联网在线业务类的关系数据不会太大,大的数据都放到云存储里面了,数据库只存索引。还有,数据库的分库分表也相对成熟,索引数据也很难快速膨胀。如果用户有对分布式索引的需求,可以考虑前面我们谈到的有序表。
离线任务处理
离线任务处理主要解决,用户需要做大量的cpu密集型的工作,包括图片转化,视频转化等。我们这里采用了一套消息队列的方式进行离线处理。用户将处理请求扔给消息队列,执行机获取消息队列的消息之后,会执行相关的的用户代码。
php运行环境
PHP运行环境,主要解决PHP的分布式化问题。云平台上跑的服务,千奇百怪,可能因为没有流量,只用到实际机器的千分之一,也可能拥有巨额流量,需要上百台机器支持。当然大部分服务没有什么流量。对于传统的虚拟化来说,1台机器能虚拟化成32台,已经慢的不行。这样,一台物理机只能部署32个app运用,对于基础架构来说是不可接受的。因为互联网上的云端运用,会急剧膨胀,所以我们需要一种新的虚拟化架构,能将机器的粒度切的更细。
这里我们使用PHP为开发语言展示一个轻量级的虚拟化技术。我们通过轻量级虚拟化技术,为每个用户分配一组FAST CGI进程资源,通过Web端的调度,将请求引到各自的FAST CGI进程组中处理。这样一台机器能启动多少个进程,我们就能虚拟化多少份。
如果网站流量很大,单机处理不了,该如何解决?我们是通过FAST CGI进程个数来调度的,单机资源不够的情况下,我们会在多台机器上分配进程,组成一个FAST CGI组,然后通知Web端,这个网站的请求可以分流到哪些FAST CGI中去。我们会有一个总控的Master来观察各台机器的负载,从而判断是否要迁移FAST CGI进程。FAST CGI进程的迁移是简单的,这台机器KILL,在另外一台机器重启即可。
这个是我们PHP执行环境的架构。
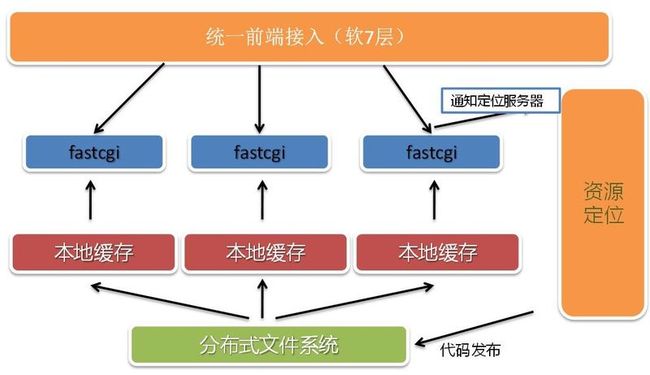
架构依赖与资源定位服务。资源定位通知前端接入,哪些机器负载还行,可以引流,哪些已经故障,或者压力过大,不能引流。当A.baidu.com的流量过来的时候,前端接入会解析域名,并且根据资源定位获取的数据(本地有缓存),分发到对应的某台机器的FAST CGI端口上,执行PHP代码后返回。因为FAST CGI读取的用户代码存储在网络文件系统中,所以前端接入无论选择哪台FAST CGI都能够有效的做处理。在实际过程中,我们发现网络文件系统对性能,尤其是HTML的访问性能影响很大,因此我们对每台机器做了单机缓存。不过Cache失效是个非常难解决的问题,我们这里采用的方法是一但文件发生修改,资源定位会通知所有客户机的该文件缓存失效,而且更新必须走同一的入口。由于我们只存储代码,效果还可以。有了分布式的网络文件系统,用户代码更新也变得异常简单。只要更新完成,通知缓存失效即可。
另外一个问题,如果运行平台跑大量的垃圾网站,比如很多一天只有少量请求的网站。用轻量级虚拟化,即使1台机器切出2000千份资源,还是很浪费的。对于这种运用,我们采用了FAST CGI复用,即很多小网站的请求都落到1个FAST CGI上,然后FAST CGI根据目前处理的网站,来获取相关的配额控制。真正做到资源消耗跟访问量成正比,没访问没成本。这里可能用CGI更好点,不过为了架构统一下,这点优化不算麻烦。
小结
简单介绍了App Engine所具有的能力,一个PHP的轻量级虚拟化,能够将1台机器虚拟成万分之一,也能将万台机器合成1个大的虚拟环境。实现从万分之一到万倍计算资源的渐进分配。它成功解决了一个网站,从小到大的计算能力的无限扩展问题。
也介绍了云存储所具备的能力,它支持海量的数据存储,成功解决了一个网站,从小到大的存储能力无限扩展问题。
整个云端运用,就是基于强悍可伸缩的计算能力和存储能力之下构建的网站。我们真正做的就是逻辑开发,和各个终端下的特殊展现形式。用这套架构,实现一个视频分享网站,电子书阅读网站是容易的。减少了云端应用的开发门槛,整个云端产品也将丰富多彩。它们都用统一的架构,计算和存储分离,程序开发无状态化,持久性存储放在云存储中。
有给力的基础架构,云端运用随手拈来。目前在百度公司内部,这种架构已经有成型的运用,它极大的提高了应用服务的开发效率,降低服务运维成本和开发人员的技术门槛。百度内部云平台迁移了大量的在线服务,有关百度的最新进展和数据,大家可以参考《QCon北京2011全球企业开发大会》公布的一些关于BAE的资料。