编写不易,转载请注明(http://shihlei.iteye.com/blog/2082625)!
一安装概述
Hadoop 安装的三种模式:
1)单机模式(standalone)
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
2)伪分布模式(Pseudo-Distributed Mode)
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
3)全分布模式(Fully Distributed Mode)
Hadoop守护进程运行在一个集群上。
二 程序版本
hadoop-2.3.0-cdh5.0.1.tar.gz
三 单机搭建
1)解压:tar -xvf hadoop-2.3.0-cdh5.0.1.tar.gz
2)配置环境变量:vi ~/.bashrc
# hadoop cdh5
export HADOOP_HOME=/home/zero/hadoop/hadoop-2.3.0-cdh5.0.1
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source ~/.bashrc
3)运行wordcount
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.3.0-cdh5.0.1.jar wordcount $HADOOP_HOME/etc/hadoop /tmp/out
说明:
- 该模式不使用hdfs,hadoop fs -ls / 浏览的是本地文件系统
- 该模式没有修改配置文件,中间临时数据等存放于默认路径/tmp/hadoop-${user}
四 伪分布式搭建
(一)规划
1)启动进程:
- namenode
- datanode
- resourcemanager
- nodemanager
- historyserver
2)管理页面列表:
- NameNode :http://8.8.8.10:50070/dfshealth.html(使用IP默认打开该页面,个人比较习惯使用jsp页面 http://8.8.8.10:50070/dfshealth.jsp)
- ResourceManager : http://8.8.8.10:8088
- MapReduce JobHistory Server : http://8.8.8.10:10998
(二)搭建过程
(1)准备
1)修改/etc/hosts添加映射:8.8.8.10 CentOS-StandAlone
2)关闭防火墙:root用户 : service iptables stop
3)解压:tar -xvf hadoop-2.3.0-cdh5.0.1.tar.gz
4)配置环境变量:vi ~/.bashrc
# hadoop cdh5
export HADOOP_HOME=/home/zero/hadoop/hadoop-2.3.0-cdh5.0.1
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source ~/.bashrc
(2)安装HDFS
1)修改$HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://CentOS-StandAlone:8020</value>
</property>
</configuration> 2)修改$HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<!--开启web hdfs-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/zero/hadoop/hadoop-2.3.0-cdh5.0.1/data/dfs/name</value>
<description> namenode 存放name table(fsimage)本地目录(需要修改)</description>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>${dfs.namenode.name.dir}</value>
<description>namenode粗放 transaction file(edits)本地目录(需要修改)</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/zero/hadoop/hadoop-2.3.0-cdh5.0.1/data/dfs/data</value>
<description>datanode存放block本地目录(需要修改)</description>
</property>
</configuration>
3)namenode 格式化: hdfs namenode -format
4)hdfs 启动:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
5)验证:
进程:
[zero@CentOS-StandAlone hadoop]$ jps
3083 NameNode
3192 Jps
3158 DataNode
页面:8.8.8.10:50070
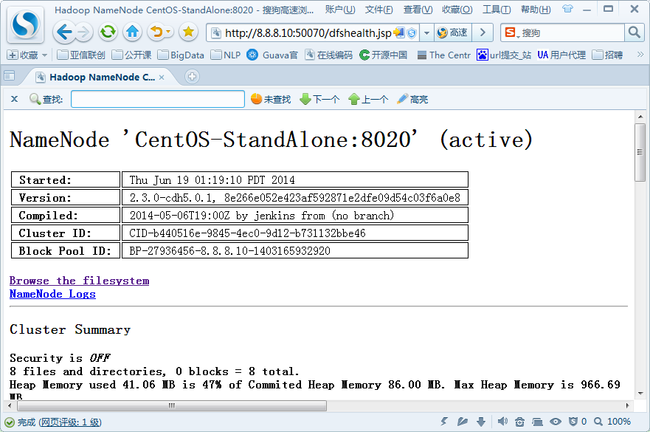
注:停止方法如下:
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode
(3)安装Yarn
1)修改$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> 2)修改$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>CentOS-StandAlone</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> 3)启动:
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
mr-jobhistory-daemon.sh start historyserver
4)验证:
进程
[zero@CentOS-StandAlone hadoop-2.3.0-cdh5.0.1]$ jps
1458 NodeManager
1131 DataNode
1634 Jps
1229 ResourceManager
1056 NameNode
1604 JobHistoryServer
页面:
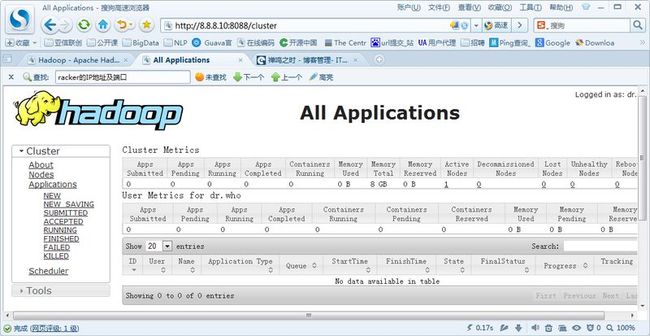
注:停止方法如下:
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop nodemanager
mr-jobhistory-daemon.sh stop historyserver
(4)运行wordcount
1)上传数据:
hadoop fs mkdir /in
hadoop fs -put $HADOOP_HOME/etc/hadoop/* in
2)执行:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.3.0-cdh5.0.1.jar wordcount /in /out
五 Hadoop本地文件系统使用配置
默认配置文件位置:
/hadoop-project-dist/hadoop-common/core-default.xml
/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
/hadoop-mapreduce-client-core/mapred-default.xml
/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
1)core-site.xml
<property>
<name>io.seqfile.local.dir</name>
<value>${hadoop.tmp.dir}/io/local</value>
<description> sequence file机型marge合并时存临时数据目录(可默认)</description>
</property>
2)hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
<description> namenode 存放name table(fsimage)本地目录(需要修改)</description>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>${dfs.namenode.name.dir}</value>
<description>namenode粗放 transaction file(edits)本地目录(需要修改)</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
<description>datanode存放block本地目录(需要修改)</description>
</property>
3)mapred-site.xml
<property>
<name>mapreduce.cluster.local.dir</name>
<value>${hadoop.tmp.dir}/mapred/local</value>
<description>MapReduce的缓存数据存储在文件系统上的位置
</description>
</property>
<property>
<name>mapreduce.jobtracker.system.dir</name>
<value>${hadoop.tmp.dir}/mapred/system</value>
<description>MapReduce在HDFS上存储系统文件的位置
</description>
</property>
<property>
<name>mapreduce.jobtracker.staging.root.dir</name>
<value>${hadoop.tmp.dir}/mapred/staging</value>
<description>用户job相关文件中转区根目录(可默认)</description>
</property>
<property>
<name>mapreduce.cluster.temp.dir</name>
<value>${hadoop.tmp.dir}/mapred/temp</value>
<description>临时文件共享目录(可默认)</description>
</property>
4)yarn-site.xml
<property>
<name>yarn.resourcemanager.fs.state-store.uri</name>
<value>${hadoop.tmp.dir}/yarn/system/rmstore</value>
<description>resourcemanager 状态存放路径(需要修改)</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>${hadoop.tmp.dir}/nm-local-dir</value>
<description>一个Application执行时本地化文件的存放路径,本地话文件具体问题:
${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid}.(可默认)
</description>
</property>