在Hive中,如果一个很大的表和一个小表做join,Hive可以自动或者手动使用MapJoin,将小表的数据加载到DistributeCache中,从而在使用Map Task扫描大表的同时,完成join,这对join的性能提升非常多。
在SparkSQL中,目前还不支持自动或者手动使用MapJoin。变通的方法是,将小表进行cache,然后再和大表做join。 SparkSQL中cache的作用就是将小表数据广播到每一个Worker的内存中,和加载到DistributeCache中是一个道理。
具体实现如下:
create table t_lxw1234 as
SELECT a.cookieid,
b.brand,
a.orderid AS ad_activity_id,
a.orderitemid AS ad_id,
a.siteid AS media_id,
a.inventoryid AS ad_area_id,
SUM(1) AS pv
FROM lxw1234.t_log a
join lxw1234.t_config b
ON (a.orderid = b.ad_activity_id)
WHERE a.pt = '2015-06-15'
GROUP BY a.cookieid,
b.brand,
a.orderid,
a.orderitemid,
a.siteid,
a.inventoryid
上面SQL中,大表 lxw1234.t_log 有3亿多条记录,而小表 lxw1234.t_config 中只有1000多条,一般情况下,SparkSQL的执行计划如下图所示:
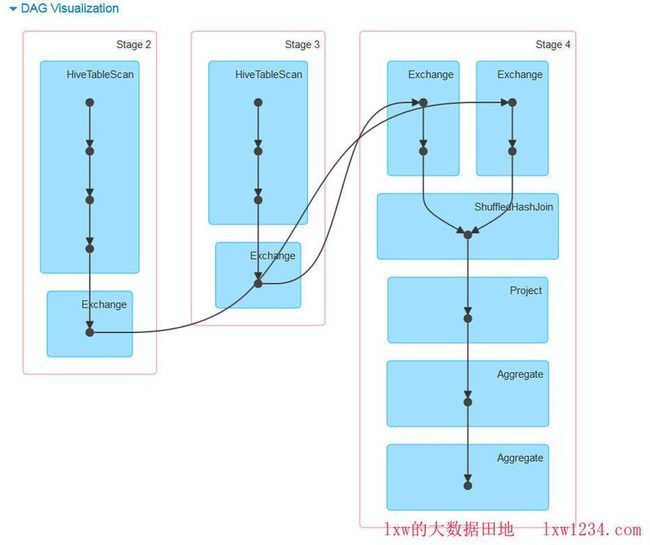
可以看出,先分别扫描两张表,之后在做ShuffledHashJoin,而在这一步,由于小表数据量非常小,也就是能关联上的键值很少,因此这里发生了数据倾斜,导致最后的几个task处理的数据量非常大,直到内存溢出而报错,如图:

SparkSQL中提供了CACHE TABLE的命令,可以将一个表或者查询进行广播,命令如下:
CACHE TABLE t_config AS SELECT ad_activity_id,brand FROM lxw1234.t_config
这样,等于是将t_config这张table加载到DistributeCache中,接下来再用这张内存表和大表做join:
create table t_lxw1234 as
SELECT a.cookieid,
b.brand,
a.orderid AS ad_activity_id,
a.orderitemid AS ad_id,
a.siteid AS media_id,
a.inventoryid AS ad_area_id,
SUM(1) AS pv
FROM lxw1234.t_log a
join t_config b
ON (a.orderid = b.ad_activity_id)
WHERE a.pt = '2015-06-15'
GROUP BY a.cookieid,
b.brand,
a.orderid,
a.orderitemid,
a.siteid,
a.inventoryid
再看执行计划:
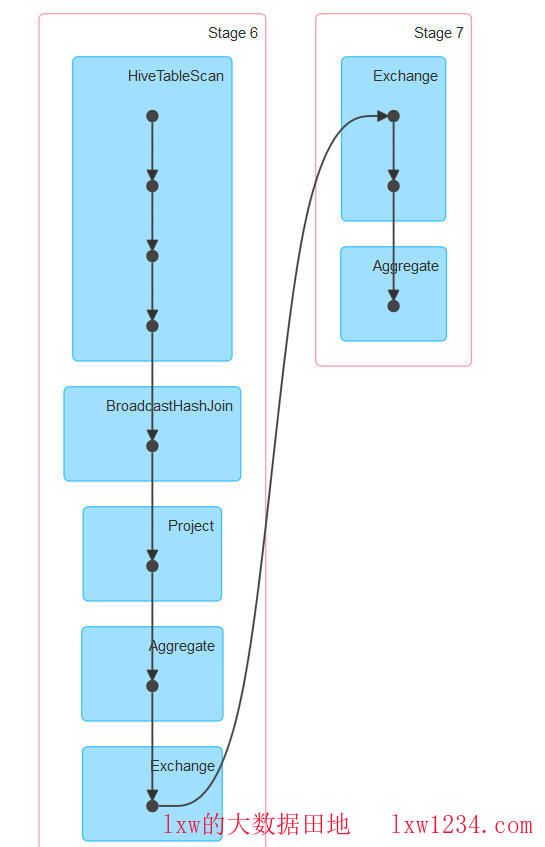
这次,在一个Stage中,便完成了大表的扫描和与小表的BroadcastHashJoin,性能上自然不用说了,很快就跑完了。
在Hive中试了下同样的语句,Hive中走MapJoin,使用的时间比SparkSQL中多近50%,但需要注意的是,Hive中MapReduce消耗的资源,却是SparkSQL消耗资源的好几倍,这也证实,尽管是从HDFS中读数据,Spark仍然要优于MapReduce。
另外,SparkSQL从Hive表(HDFS)中读数据,全部用的NODE_LOCAL task,如果是ANY,那就要慢一些了,而且会消耗很大的网络资源。
本文同步自我的大数据田地(关注Hadoop、Spark、Hive等大数据技术)。