通过学习研究总结了Storm+zookeeper+metaq 消息处理的的整个过程以及zookeeper怎样做消息的分发与订阅,通过以下说明相信对学习storm的用户来说是一个质的回升。
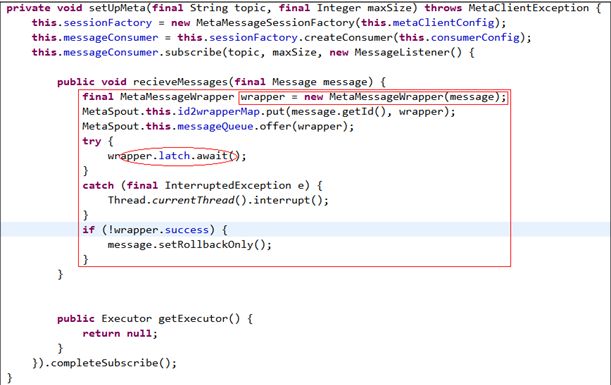
MetaQ主要作为数据传输的工具,Storm是数据获取&处理的工具,Zookeeper是一个协调管理的角色。
数据存储,经Zookeeper协调,消息(数据)发到MetaQ中;
数据获取,Storm-toplogy的Spout经Zookeeper协调到MetaQ,取出消息(数据);
数据处理,Storm-toplogy的Bolt经Zookeeper协调到某一个Supervisor,开始处理。
如图:
通过上图大家会产生疑问:
①怎样利用metaQ客户端代码发送消息与接收消息
②storm基本的代码逻辑是什么
③storm-spout源源不断的接收消息&发送数据
Metaq 客户端的使用
发送消息:
发送消息由消息生产者MessageProducer触发,MessageProducer从MessageSessionFactory中创建,具体环节如图。
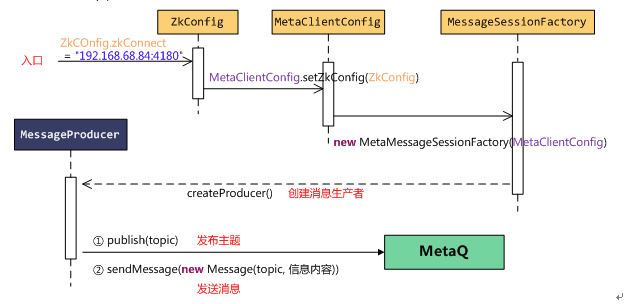
接收消息:
接收消息由消息消费者MessageConsumer触发,MessageConsumer同样从MessageSessionFactory中创建,具体环节如图。

Storm 的基础API 详解:
我们知道,storm编码主要就是topology的编码&发布,topology=Spout(数据源)+Bolt(数据处理),那么简单分析下,这3部分的基本代码是怎么样的?
**Spout两个主要动作:取消息和发射。继承于BaseRichSpout,实现open()、declareOutputFields()、nextTuple()。
nextTuple()包括了取消息和发射动作,取消息=上述MetaQ接收消息的方法,发射则需要SpoutOutputCollector的emit(消息中的数据)来进行。
SpoutOutputCollector则是从open()中获得。
declareOutputFields()主要是declarer.declare(new Fields("***"));可以简单理解为发送数据时所赋予的key标识。
**Bolt继承于BaseRichBolt,实现execute()获取发射过来的数据,进行处理。数据以Tuple为单位,通过key标识获取。
**Topology则主要由TopologyBuilder和StormSubmitter组成。将**Spout、**Bolt设置于TopologyBuilder中,赋予运行线程的个数;最终通过StormSubmitter提交Topology,展开实时计算。

通过以上两点的叙述,我们明白了消息怎么发送,storm怎么接收消息,strom处理环节的大致逻辑,但是有一个问题就是:storm怎么能源源不断的接收消息&发送数据呢?这个就主要在于storm-spout的编程了。
Storm作者在官方网站的示例表明,引入一个storm-metaq-spout.jar来解释的这个问题,这个jar里仅有3个类:MetaMessageWrapper、MetaSpout、StringScheme。所以我们主要明白这3个类的作用,很多问题就迎刃而解了。
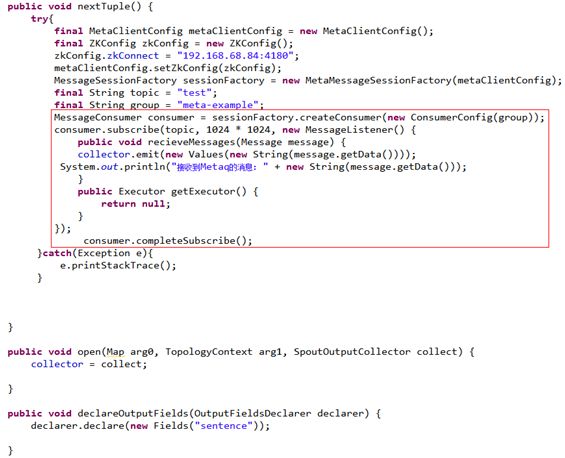
3个类中,个人认为最主要的就是MetaMessageWrapper,因为MetaSpout的nextTuple()取出的消息是从MetaMessageWrapper而来。

但是MetaMessageWrapper却很简单,只是含有消息本身和CountDownLatch,因此,CountDownLatch的理解至关重要。
CountDownLatch类是一个同步计数器(倒计数的锁存器),构造时传入int参数,该参数就是计数器的初始值,每调用一次countDown()方法,计数器减1。计数器大于0时,await()方法会阻塞程序继续执行;当计数减至0时,触发特定的事件。利用这种特性,可以让主线程等待子线程的结束。
MetaSpout,和上述**Spout的代码结构当然是一致的,不同点就是代码的实现。自定义两个数据结构messageQueue和map,它们用在setUpMeta()[由open()调用]中,理解为:消息消费者得到消息,然后将消息交给MetaMessageWrapper,同时将wrapper置入messageQueue和map,这就与nextTuple()对应了起来。
更为关键的是,CountDownLatch进入await()状态,这里就是重点!这里就是与我们基础demo的最大不同点,理解它就击破一切。