nutch inject 详解
nutch的inject 有二个job
第一个job 如下图

map :InjectMapper 功能如下
1 url是否有tab分割的k-v 对如果有记录下来,
2 如果配置了过滤使用 URLNormalizers和 URLFilters 对url 进行格式化和过滤,
3 如果过滤的url 不为空则创建CrawlDatum对象,状态 STATUS_INJECTED,设置fetcher 间隔时间从fetchdb.fetch.interval.default 配置中取,如果没有默认2592000s 为30 天
4 设置fectchtime 为当前时间 datum.setFetchTime(curTime);
5 设置 score 根据db.score.injected 配置分数,默认为1
这个job 只有map 没有reduce,所以使用默认的reduce
map 输入 : 存放url的目录 如果 bin/nutch crawl urls -dir crawl -topN 1 -depth 1 这个命令 输入是urls,默认的使用TextInputFormat输入的 key:偏移量 value:一行的文本 ,map的输出为 key :Text 为url, value:CrawlDatum
没有设置reduce 使用默认的Reducer
reduce输出 :mapred.temp.dir 配置的属性值目录下面的(inject-temp-当前时间)下面 输出为 key :Text 为url, value:List<CrawlDatum>
第二个job如下图
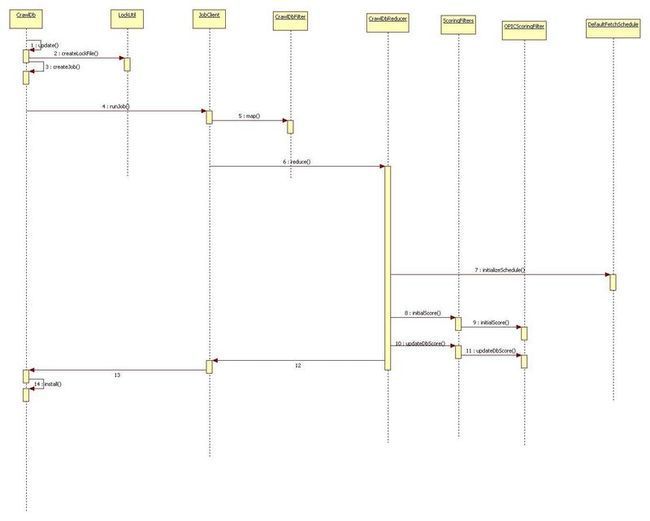
这个job 叫mergerjob主要是合并第一个job的输出和crawldb/current 下面的值进行合并,输出目录为crawldb/current 。
map :CrawlDbFilter 功能如下
输入目录为参数crawlDb/current 和上次job的输出目录
key:Text value:CrawlDatum
如果设置了urlNormalizers=true 对url进行normalize
如果设置了urlFiltering=true 对url进行过滤
如果url不为空 写入
key : Text 为url value: CrawlDatum
reduce :InjectReducer
对一个key 的value,设置状态,如果value中的CrawlDatum 如果状态是CrawlDatum.STATUS_INJECTED 则设置状态为CrawlDatum.STATUS_DB_UNFETCHED
里面的多值去重复,否则不设置状态,使用当前的状态,如果存在多值,如果有状态不是CrawlDatum.STATUS_INJECTED,使用这个状态,否则使用 CrawlDatum.STATUS_DB_UNFETCHED,写入
输出目录为 crawldb 下面的先建一个随机数命名的目录
Path newCrawlDb =
new Path(crawlDb,
Integer.toString(new Random().nextInt(Integer.MAX_VALUE)));
CrawlDb.install 替换 current目录
逻辑如下
1 如果crawlDb 下面有old目录删除old目录
2 把crawlDb 下面的current目录变成old目录
3 把job是输出目录变成current目录删除old目录
第一个job 如下图
map :InjectMapper 功能如下
1 url是否有tab分割的k-v 对如果有记录下来,
2 如果配置了过滤使用 URLNormalizers和 URLFilters 对url 进行格式化和过滤,
3 如果过滤的url 不为空则创建CrawlDatum对象,状态 STATUS_INJECTED,设置fetcher 间隔时间从fetchdb.fetch.interval.default 配置中取,如果没有默认2592000s 为30 天
4 设置fectchtime 为当前时间 datum.setFetchTime(curTime);
5 设置 score 根据db.score.injected 配置分数,默认为1
这个job 只有map 没有reduce,所以使用默认的reduce
map 输入 : 存放url的目录 如果 bin/nutch crawl urls -dir crawl -topN 1 -depth 1 这个命令 输入是urls,默认的使用TextInputFormat输入的 key:偏移量 value:一行的文本 ,map的输出为 key :Text 为url, value:CrawlDatum
没有设置reduce 使用默认的Reducer
reduce输出 :mapred.temp.dir 配置的属性值目录下面的(inject-temp-当前时间)下面 输出为 key :Text 为url, value:List<CrawlDatum>
第二个job如下图
这个job 叫mergerjob主要是合并第一个job的输出和crawldb/current 下面的值进行合并,输出目录为crawldb/current 。
map :CrawlDbFilter 功能如下
输入目录为参数crawlDb/current 和上次job的输出目录
key:Text value:CrawlDatum
如果设置了urlNormalizers=true 对url进行normalize
如果设置了urlFiltering=true 对url进行过滤
如果url不为空 写入
key : Text 为url value: CrawlDatum
reduce :InjectReducer
对一个key 的value,设置状态,如果value中的CrawlDatum 如果状态是CrawlDatum.STATUS_INJECTED 则设置状态为CrawlDatum.STATUS_DB_UNFETCHED
里面的多值去重复,否则不设置状态,使用当前的状态,如果存在多值,如果有状态不是CrawlDatum.STATUS_INJECTED,使用这个状态,否则使用 CrawlDatum.STATUS_DB_UNFETCHED,写入
输出目录为 crawldb 下面的先建一个随机数命名的目录
Path newCrawlDb =
new Path(crawlDb,
Integer.toString(new Random().nextInt(Integer.MAX_VALUE)));
CrawlDb.install 替换 current目录
逻辑如下
1 如果crawlDb 下面有old目录删除old目录
2 把crawlDb 下面的current目录变成old目录
3 把job是输出目录变成current目录删除old目录