Heritrix
利用 Heritrix 构建特定站点爬虫
本文由浅入深,详细介绍了 Heritrix 在 Eclipse 中的配置、运行。最后对其进行扩展,介绍如何实现只抓取特定网站的页面。
通过本文,读者可以了解 Heritrix 的相关特点以及在 Eclipse 中的配置运行,能够从零开始构建特定站点的专有爬虫,从而为网站增加全文检索服务。
随着网站内容的增加,为其添加搜索功能是一个常见的需求,搜索引擎也已成为互联网最重要的应用之一。你是否觉得普通的数据库检索已经不能满足 你的查询需求了呢?是否希望花最小的代价为你的网站建立一个像 Google、百度那样的全文搜索引擎?是否希望创建自己专有的搜索引擎而不是想尽办法 SEO(Search Engine Optimization,搜索引擎优化)来等着 Google、百度收录你的网站?借助于开源工具的力量,你将很容易实现上述目标。
搜索引擎的实现过程,可以看作三步:1. 从互联网上抓取网页 2. 对网页进行处理,建立索引数据库 3. 进行查询。因此无论什么样的搜索引擎,都必须要有一个设计良好的爬虫来支持。Heritrix 是 SourceForge 上基于 Java 的开源爬虫,它可以通过 Web 用户界面来启动、设置爬行参数并监控爬行,同时开发者可以随意地扩展它的各个组件,来实现自己的抓取逻辑,因其方便的可扩展性而深受广大搜索引擎爱好者的 喜爱。
虽然 Heritrix 功能强大,但其配置复杂,而且官方只在 Linux 系统上测试通过,用户难以上手。本文由浅入深,详细介绍 Heritrix 在 windows 下 Eclipse 中的配置运行,并对其进行简单扩展,使其只针对某一特定网站进行抓取,为构建相应站点的全文搜索引擎打好基础。
目前 Heritrix 的最新版本是 1.14.4(2010-5-10 发布),您可以从 SourceForge(http://sourceforge.net/projects/archive-crawler/files/)上下载。每 个版本都有四个压缩包,两个 .tar.gz 包用于 Linux 下,.zip 用于 windows 下。其中 heritrix-1.14.4.zip 是源代码经过编译打包后的文件,而 heritrix-1.14.4-src.zip 中包含原始的源代码,方便进行二次开发。本文需要用到 heritrix-1.14.4-src.zip,将其下载并解压至 heritrix-1.14.4-src 文件夹。
首先在 Eclipse 中新建 Java 工程 MyHeritrix。然后利用下载的源代码包根据以下步骤来配置这个工程。
Heritrix 所用到的工具类库都在 heritrix-1.14.4-src\lib 目录下,需要将其导入 MyHeritrix 工程。
1)将 heritrix-1.14.4-src 下的 lib 文件夹拷贝到 MyHeritrix 项目根目录;
2)在 MyHeritrix 工程上右键单击选择“Build PathConfigure Build Path …”,然后选择 Library 选项卡,单击“Add JARs …”,如图 1 所示。
图 1. 导入类库 - 导入前

3)在弹出的“JAR Selection”对话框中选择 MyHeritrix 工程 lib 文件夹下所有的 jar 文件,然后点击 OK 按钮。如图 2 所示。
图 2. 选择类库

设置完成后如图 3 所示:
图 3. 导入类库 - 导入后

1)将 heritrix-1.14.4-src\src\java 下的 com、org 和 st 三个文件夹拷贝进 MyHeritrix 工程的 src 下。这三个文件夹包含了运行 Heritrix 所必须的核心源代码;
2)将 heritrix-1.14.4-src\src\resources\org\archive\util 下的文件 tlds-alpha-by-domain.txt 拷贝到 MyHeritrix\src\org\archive\util 中。该文件是一个顶级域名列表,在 Heritrix 启动时会被读取;
3)将 heritrix-1.14.4-src\src 下 conf 文件夹拷贝至 Heritrix 工程根目录。它包含了 Heritrix 运行所需的配置文件;
4)将 heritrix-1.14.4-src\src 中的 webapps 文件夹拷贝至 Heritrix 工程根目录。该文件夹是用来提供 servlet 引擎的,包含了 Heritrix 的 web UI 文件。需要注意的是它不包含帮助文档,如果想使用帮助,可以将 heritrix-1.14.4.zip\docs 中的 articles 文件夹拷贝到 MyHeritrix\webapps\admin\docs(需新建 docs 文件夹)下。或直接用 heritrix-1.14.4.zip 的 webapps 文件夹替换 heritrix-1.14.4-src\src 中的 webapps 文件夹,缺点是这个是打包好的 .war 文件,无法修改源代码。
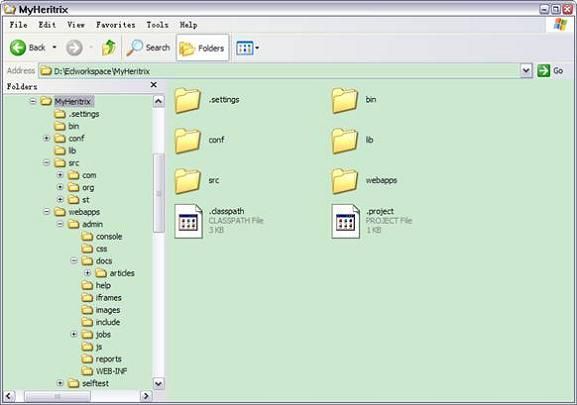
拷贝完毕后的 MyHeritrix 工程目录层次如图 4 所示。这里运行 Heritrix 所需的源代码等已经准备完备,下面需要修改配置文件并添加运行参数。
图 4. MyHeritrix 工程的目录层次
conf 文件夹是用来提供配置文件的,里面包含了一个很重要的文件:heritrix.properties。heritrix.properties 中配置了大量与 Heritrix 运行息息相关的参数,这些参数的配置决定了 Heritrix 运行时的一些默认工具类、Web UI 的启动参数,以及 Heritrix 的日志格式等。当第一次运行 Heritrix 时,只需要修改该文件,为其加入 Web UI 的用户名和密码。如图 5 所示,设置 heritrix.cmdline.admin = admin:admin,“admin:admin”分别为用户名和密码。然后设置版本参数为 1.14.4。
图 5. 设置登陆用户名和密码

在 MyHeritrix 工程上右键单击选择“Run AsRun Configurations”,确保 Main 选项卡中的 Project 和 Main class 选项内容正确,如图 6 所示。其中的 Name 参数可以设置为任何方便识别的名字。
图 6. 配置运行文件—设置工程和类

然后在 Classpath 页选择 UserEntries 选项,此时右边的 Advanced 按钮处于激活状态,点击它,在弹出的对话框中选择“Add Folders”,然后选择 MyHeritrix 工程下的 conf 文件夹。如图 7 所示。
图 7. 添加配置文件

至此我们的 MyHeritrix 工程已经可以运行起来了。下面我们来看看如何启动 Heritrix 并设置一个具体的抓取任务。
找到 org.archive.crawler 包中的 Heritrix.java 文件,它是 Heritrix 爬虫启动的入口,右键单击选择“Run AsJava Application”,如果配置正确,会在控制台输出如图 8 所示的启动信息。
图 8. 运行成功时控制台输出

在浏览器中输入 http://localhost:8080 ,会打开如图 9 所示的 Web UI 登录界面。
图 9. Heritrix 登录界面

输入之前设置的用户名 / 密码:admin/admin,进入到 Heritrix 的管理界面,如图 10 所示。因为我们还没有创建抓取任务,所以 Jobs 显示为 0。
图 10. Heritrix 控制台
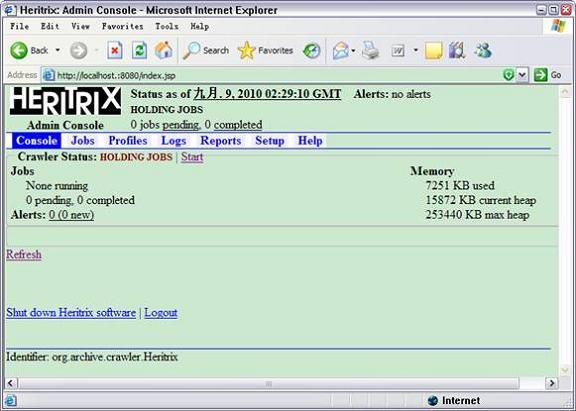
Heritrix 使用 Web 用户界面来启动、设置爬行参数并监控爬行,简单直观,易于管理。下面我们以北京林业大学首页 (http://www.bjfu.edu.cn/) 为种子站点来创建一个抓取实例。
在 Jobs 页面创建一个新的抓取任务,如图 11 所示,可以创建四种任务类型。
图 11. 创建抓取任务

- Based on existing job:以一个已经有的抓取任务为模板生成新的抓取任务。
- Based on a recovery:在以前的某个任务中,可能设置过一些状态点,新的任务将从这个设置的状态点开始。
- Based on a profile:专门为不同的任务设置了一些模板,新建的任务将按照模板来生成。
- With defaults:这个最简单,表示按默认的配置来生成一个任务。
这里我们选择“With defaults”,然后输入任务相关信息,如图 12 所示。
图 12. 创建抓取任务“BJFU”

注意图 11 中下方的按钮,通过这些按钮可以对抓取工作进行详细的设置,这里我们只做一些必须的设置。
首先点击“Modules”按钮,在相应的页面为此次任务设置各个处理模块,一共有七项可配置的内容,这里我们只设置 Crawl Scope 和 Writers 两项,下面简要介绍各项的意义。
1)Select Crawl Scope:Crawl Scope 用于配置当前应该在什么范围内抓取网页链接。例如选择 BroadScope 则表示当前的抓取范围不受限制,选择 HostScope 则表示抓取的范围在当前的 Host 范围内。在这里我们选择 org.archive.crawler.scope.BroadScope,并单击右边的 Change 按钮保存设置状态。
2)Select URI Frontier:Frontier 是一个 URL 的处理器,它决定下一个被处理的 URL 是什么。同时,它还会将经由处理器链解析出来的 URL 加入到等待处理的队列中去。这里我们使用默认值。
3)Select Pre Processors:这个队列的处理器是用来对抓取时的一些先决条件进行判断。比如判断 robot.txt 信息等,它是整个处理器链的入口。这里我们使用默认值。
4)Select Fetchers:这个参数用于解析网络传输协议,比如解析 DNS、HTTP 或 FTP 等。这里我们使用默认值。
5)Select Extractors:主要是用于解析当前服务器返回的内容,取出页面中的 URL,等待下次继续抓取。这里我们使用默认值。
6)Select Writers:它主要用于设定将所抓取到的信息以何种形式写入磁盘。一种是采用压缩的方式(Arc),还有一种是镜像方式(Mirror)。这里我们选 择简单直观的镜像方式:org.archive.crawler.writer.MirrorWriterProcessor。
7)Select Post Processors:这个参数主要用于抓取解析过程结束后的扫尾工作,比如将 Extrator 解析出来的 URL 有条件地加入到待处理的队列中去。这里我们使用默认值。
设置完毕后的效果如图 13:
图 13. 设置 Modules

设置完“Modules”后,点击“Settings”按钮,这里只需要设置 user-agent 和 from,其中:
- “@VERSION@”字符串需要被替换成 Heritrix 的版本信息。
- “PROJECT_URL_HERE”可以被替换成任何一个完整的 URL 地址。
- “from”属性中不需要设置真实的 E-mail 地址,只要是格式正确的邮件地址就可以了。
对于各项参数的解释,可以点击参数前的问号查看。本次任务设置如图 14 所示。
图 14. 设置 Settings

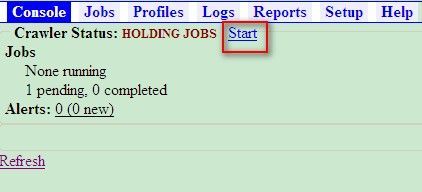
完成上述设置后点击“Submit job”链接,然后回到 console 控制台,可以看到我们刚刚创建的任务处于 pending 状态,如图 15 所示。
图 15. 启动任务
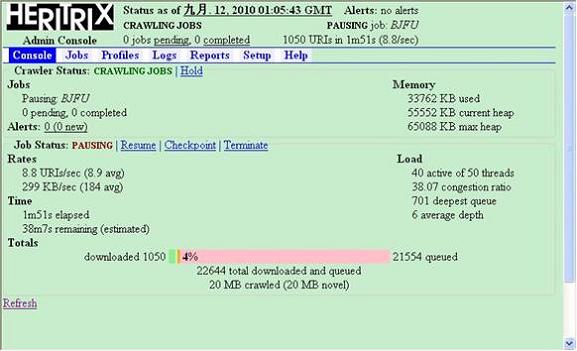
点击“Start”启动任务,刷新一下即可看到抓取进度以及相关参数。同时可以暂停或终止抓取过程,如图 16 所示。需要注意的是,进度条的百分比数量并不是准确的,这个百分比是实际上已经处理的链接数和总共分析出的链接数的比值。随着抓取工作不断进行,这个百分 比的数字也在不断变化。
图 16. 开始抓取
同时,在 MyHeritrix 工程目录下自动生成“jobs”文件夹,包含本次抓取任务。抓取下来网页以镜像方式存放,也就是将 URL 地址按“/”进行切分,进而按切分出来的层次存储。如图 17 所示。
图 17. 抓取到的网页

从图 17 也可以看出,因为我们选择了 BroadScope 的抓取范围,爬虫会抓取所有遇到的 URL,这样会造成 URL 队列无限制膨胀,无法终止,只能强行终止任务。尽管 Heritrix 也提供了一些抓取范围控制的类,但是根据实际测试经验,如果想要完全实现自己的抓取逻辑,仅仅靠 Heritrix 提供的抓取控制是不够的,只能修改扩展源代码。
下面本文以实现抓取北京林业大学(www.bjfu.edu.cn )下相关页面为例说明如何扩展 Heritrix 实现自己的抓取逻辑。
我们先来分析一下 Heritrix 的总体结构和 URI 的处理链。
Heritrix 采用了模块化的设计,用户可以在运行时选择要用的模块。它由核心类(core classes)和插件模块(pluggable modules)构成。核心类可以配置,但不能被覆盖,插件模块可以由第三方模块取代。所以我们就可以用实现了特定抓取逻辑的第三方模块来取代默认的插件 模块,从而满足自己的抓取需要。
Heritrix 的整体结构如图 18 所示。其中 CrawlController(下载控制器)整个下载过程的总控制者,整个抓取工作的起点,决定整个抓取任务的开始和结束。每个 URI 都有一个独立的线程,它从边界控制器(Frontier)获取新的 URI,然后传递给 Processor chains(处理链)经过一系列 Processor(处理器)处理。
图 18. Heritrix 整体结构

处理链由多个处理器组成,共同完成对 URI 的处理,如图 19 所示。
图 19. URI 处理链
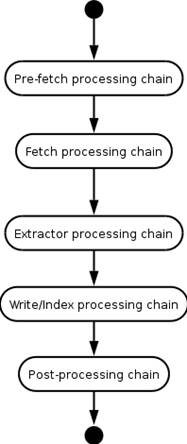
1)Pre-fetch processing chain( 预处理链 ),用来判断抓取时的一些先决条件,如 robot 协议、DNS 等。
2)Fetch processing chain(抓取处理链),解析网络传输协议,从远程服务器获取数据。
3)Extractor processing chain(抽取处理链),从网页中抽取新的 URL。
4)Write/index processing chain(写处理链),负责把数据写入本地磁盘。
5)Post-processing chain(后置处理链),在整个抓取解析过程结束后,进行一些扫尾工作,比如将前面 Extractor 解析出来的 URL 有条件的加入到待处理队列中去。这里我们只需要控制加入到待处理队列中的 URL,就可以控制抓取的范围。
扩展 FrontierScheduler 来抓取特定网站内容
FrontierScheduler 是 org.archive.crawler.postprocessor 包中的一个类,它的作用是将在 Extractor 中所分析得出的链接加入到 Frontier 中,以待继续处理。在该类的 innerProcess(CrawlURI) 函数中,首先检查当前链接队列中是否有一些属于高优先级的链接。如果有,则立刻转走进行处理;如果没有,则对所有的链接进行遍历,然后调用 Frontier 中的 schedule() 方法加入队列进行处理。其代码如图 20 所示。
图 20. FrontierScheduler 类中的 innerProcess() 和 schedule() 函数

从上面的代码可以看出 innerProcess() 函数并未直接调用 Frontier 的 schedule() 方法,而是调用自己内部的 schedule() 方法,进而在这个方法中再调用 Frontier 的 schedule() 方法。而 FrontierScheduler 的 schedule() 方法实际上直接将当前的候选链接不加任何判断地直接加入到抓取队列当中了。这种方式为 FrontierScheduler 的扩展留出了很好的接口。
这里我们需要构造一个 FrontierScheduler 的派生类 FrontierSchedulerForBjfu,这个类重载了 schedule(CandidateURI caUri) 这个方法,限制抓取的 URI 必须包含“bjfu”,以保证抓取的链接都是北林内部的地址。派生类 FrontierSchedulerForBjfu 具体代码如图 21 所示。
图 21. 派生类 FrontierSchedulerForBjfu

然后,在 modules 文件夹中的 Processor.options 中添加一行 “org.archive.crawler.postprocessor.FrontierSchedulerForBjfu|FrontierSchedulerForBjfu”, 这样在爬虫的 WebUI 中就可以选择我们扩展的 org.archive.crawler.postprocessor.FrontierSchedulerForBjfu 选项。如图 22 所示。
图 22. 用 FrontierSchedulerForBjfu 代替 FrontierScheduler

最终抓取的页面如图 23 所示,全部都是 http://www.bjfu.edu.cn 下的页面。是不是很简单呢?当然,如果只是想实现这个抓取目标,不用修改源代码,通过在 Web UI 中设置抓取规则也可以满足要求。本文只是以此为例说明 Heritrix 如何扩展 Heritrix。
图 23. 扩展后的抓取效果

错误信息:
Access restriction: The type FileURLConnection is not accessible due to restriction on required library C:\Program Files\Java\jdk1.6.0_20\jre\lib\rt.jar,如图 24 所示。
图 24. Access restriction 错误

解决方案:
这是 JRE 的访问限制导致报错,在 MyHeritrix 工程上右键单击选择“Build PathConfigure Build Path …”,然后选择 Library 选项卡,将“JRE System Library”删除然后重新导入一下即可修复。或者选择 “WindowsPreferencesJavaCompilerErrors/Warnings”找到“Deprecated and restricted API”下的“Forbidden reference (access rules)”,将默认设置“Error”改为“Warning”或“Ignore”。
错误信息如图 25 所示:
图 25. NullPointerException 错误

解决方案:
这个错误的原因是缺少了“tlds-alpha-by-domain.txt”文件,在 heritrix-1.14.4-src\src\resources\org\archive\util 下可以找到该文件,将其拷贝到 MyHeritrix\src\org\archive\util 中即可。
错误信息如图 26 所示。
图 26. Modules 界面无法改变选择项

解决方案:
这是因为没有添加运行时所需的配置文件,参照本文“4. 配置运行方式 ”为 Classpath 添加参数即可。
Heritrix 属于多线程下载爬虫,在公司内网使用有抓取限制。
在搜索引擎的开发过程中,使用一个优秀的爬虫来获得所需要的网页信息是第一步,也是整个系统成功的关键。Heritrix 是一个功能强大而且高效的爬虫,具有良好的可扩展性。本文介绍了它在 windows 下 Eclipse 中的配置运行以及扩展,使您可以以最快的速度上手使用 Heritrix,享受您的爬虫之旅。
学习
- 查看 Heritrix 网站 ,学习更多关于 Heritrix 的知识。
- 从 SourceForge 上下载 Heritrix 1.14.4 。
- 查看文章“使用 HttpClient 和 HtmlParser 实现简易爬虫 ”,学习如何利用开源工具自己写爬虫。
- 下载 Eclipse IDE 。
- 访问 developerWorks Open source 专区 获得丰富的 how-to 信息、工具和项目更新以及最受欢迎的文章和教程 ,帮助您用开放源码技术进行开发,并将它们与 IBM 产品结合使用。
- 随时关注 developerWorks 技术活动 和网络广播 。
讨论
- 欢迎加入 My developerWorks 中文社区 。
![]() 平均分 (58个评分)
平均分 (58个评分)
2 星
3 星
4 星
5 星
标签
搜索所有标签
热门标签
- 1 (5)
- 2 (3)
- activity (6)
- ajax (3)
- android (57)
- apache (23)
- cache (4)
- cakephp (4)
- cas (5)
- cassandra (6)
- debug (6)
- derby (11)
- dojo (3)
- eclipse (115)
- erlang (6)
- facebook (3)
- geronimo (14)
- hadoop (7)
- heritrix (4)
- j2ee (3)
- j2ee_(java_2_e... (6)
- java (14)
- java_技术 (31)
- javascript (5)
- jface (4)
- jquery (5)
- lamp (4)
- linux (9)
- lucene (3)
- mongodb (5)
- mybatis (4)
- ndk (3)
- node.js (7)
- nodejs (3)
- open (3)
- osgi (13)
- perl (5)
- php (51)
- php_(hyperte... (38)
- python (17)
- rcp (3)
- re (3)
- roo (5)
- ruby (9)
- selenium (4)
- spring (16)
- test (3)
- tomcat (6)
- web (11)
- web_2.0 (7)
- web_服务 (5)
- xdebug (3)
- xml (7)
- zend (3)
- zookeeper (7)
- 安全 (6)
- 部分 (4)
- 存储 (5)
- 的 (4)
- 管理 (8)
- 集成开发环境 (20)
- 开发工具 (55)
- 开发简介 (6)
- 开放源码 (4)
- 全球化 (5)
- 软件开发生命周期 (5)
- 商业智能 (7)
- 设计模式 (5)
- 社区 (11)
- 数据访问 (6)
- 数据库和数据管理 (10)
- 体系架构 (3)
- 图形 (17)
- 文档和文本管理 (4)
- 性能 (5)
- 移动和嵌入式系统 (16)
- 应用开发 (35)
- 硬件平台 (6)
- 云计算 (12)
- 自动化测试 (10)
热门标签结束
我的标签
我的标签结束
- 1 (5)
- 2 (3)
- activity (6)
- ajax (3)
- android (57)
- apache (23)
- cache (4)
- cakephp (4)
- cas (5)
- cassandra (6)
- debug (6)
- derby (11)
- dojo (3)
- eclipse (115)
- erlang (6)
- facebook (3)
- geronimo (14)
- hadoop (7)
- heritrix (4)
- j2ee (3)
- j2ee_(java_2_e... (6)
- java (14)
- java_技术 (31)
- javascript (5)
- jface (4)
- jquery (5)
- lamp (4)
- linux (9)
- lucene (3)
- mongodb (5)
- mybatis (4)
- ndk (3)
- node.js (7)
- nodejs (3)
- open (3)
- osgi (13)
- perl (5)
- php (51)
- php_(hyperte... (38)
- python (17)
- rcp (3)
- re (3)
- roo (5)
- ruby (9)
- selenium (4)
- spring (16)
- test (3)
- tomcat (6)
- web (11)
- web_2.0 (7)
- web_服务 (5)
- xdebug (3)
- xml (7)
- zend (3)
- zookeeper (7)
- 安全 (6)
- 部分 (4)
- 存储 (5)
- 的 (4)
- 管理 (8)
- 集成开发环境 (20)
- 开发工具 (55)
- 开发简介 (6)
- 开放源码 (4)
- 全球化 (5)
- 软件开发生命周期 (5)
- 商业智能 (7)
- 设计模式 (5)
- 社区 (11)
- 数据访问 (6)
- 数据库和数据管理 (10)
- 体系架构 (3)
- 图形 (17)
- 文档和文本管理 (4)
- 性能 (5)
- 移动和嵌入式系统 (16)
- 应用开发 (35)
- 硬件平台 (6)
- 云计算 (12)
- 自动化测试 (10)
查看方式云 | 列表
添加评论:
请 登录 或 注册 后发表评论。
注意:评论中不支持 HTML 语法