深入理解java集合类
目的:1,能够全面了解有关集合类的构造细节
2,通过对集合类的深入理解,在实际开发中能够更精准的使用这些集合类
引子
Java集合类是java程序员的编程利器。熟练,深入的理解集合类的实现细节,
能够在实际应用中做到游刃有余,更合理,更好的使用这些集合类。本文从数据结构出发,逐一分析List,String,Map等相关数据结构。本文不是教你如何使用集合类的API,而是从数据结构的角度出发去观察各个数据结构的实现过程。数组和链表是计算机语言中最根本,最基础的两种数据结构。在接下来的分析过程中,我们将会看到java设计者如何通过这两个基本数据结构构造出丰富多彩的java结合工具。
1,List是我们平时开发中最常用的数据结构,他有两个典型的实现,ArrayList与LinkedList。从名字既可以ArrayList是用数组实现的,LinkedList使用链表实现的。
以下是ArrayList的数据结构:![]()
代码段:![]()
这么简单的数据结构还要分析是否有点多此一举,浪费笔墨呢。这里有一个小问题需要叨扰一下,既然是数组实现的,大家都知道数组一旦定义,其大小是不可变的,那么我们在实际应用过程中为什么没感觉到这一点呢? 以下是这个疑问的源码段
privatevoid grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
当调用add方法的时候,如果ArrayList判断出需要扩容就会调用grow自动为其增加容量。以上黄色部分为扩容量大小,不难看出每次以1.5倍的速度在扩充。我们来总结一下ArrayList的扩充步骤
1),判断是否需要扩充
2),计算新容量大小,扩充1.5倍(这里有个实现小细节,是通过移位而不是*1.5来实现的,编程技巧,从点滴学起)
3),拷贝以前的数组到新的数组;
通过以上分析我们可以看到,所谓的自动增长并不是毫无代价的,特别是当数据量大的时候,频繁扩容会导致大量数组拷贝,进而影响性能。建议:在使用时尽可能的给一个合理的初始值。
2,LinkedList,
我们首先看一下LinkedList所实现的接口
通过以上截图我们不难看出LinkedList至少有两个语义,列表和双端队列,实际上双端队列是队列的特殊形式。我们来分析一下LinkedList是如何通过链表实现这两种数据结构的。
如图![]()
Linkedlist本质上是一个双向链表,是通过其内部类node来实现这种数据结构的。
节点由三个部分组成,需要存储的对象引用、前一个节点的引用、后一个节点的引用。如果大家熟悉链表数据结构,不难推出一个双端列表,是同时满足队列和双端队列的语义的,只要知道了数据结构的头和尾,就可以遍历出所有关系链上的数据。LinkedList正式通过这种方式实现的:

更进一步,如果把last节点的prev属性设置成first,那么整个双端列表就成了一个环。Linkedlist就是这样一个双向链表环。
通过以上数据结构的分析,我们能够知道,对于存储的任何一个对象,我们都需要创建一个辅助的node节点对象,两个上/下引用,单纯的从存储方面讲,这是件费内存的事儿,从创建的过程来分析,它要比数组存放一个对象更复杂点,所以性能也会差一点。如果针对一个已经存在的超级列表,如果从中间部分插入一条数据,对于数组来说,中间之后都要移位向后移动移位,而对于链表而言,只是单纯的将node的上/下指针重新指向就可以了。我们不再复述这两个数组的使用场景。
3,String,StringBuilder,StringBuffer。
String在java中是一个很有意思的对象,它不是基本数据类型,但是他的使用频率与基本类型同样高调,有些网络应用,为了编解码的方便,直接使用String串来作为网络传输,然后根据具体业务去解析成不同的数据类型(当然这个本身是否合理还有待商榷)。String的拘留也是让很对程序员迷惑的地方之一。我们这里只是从存储结构方面来分析String。我们都知道String对象是不可变对象,这不只是因为String类被定义为final类,更主要的是因为String本身是由一个数组实现的。如图
被定义后不可改变是数组本身的一个特性,String对象当然不会例外。
StringBuilder和StringBuffer的数据结构,唯一的不同是StringBuilder是StringBuffer的非同步版。StringBuilder是我们平时常用的拼串工具之一(如果你还有String+,那你就out了,近一步讲String+在本质上也用了StringBuilder),如图: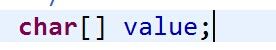
这又是一个用数组来实现的数据结构,单从数据结构来看这跟String并没有本质的区别,那为什么String是不可变,而StringBuilder是可变的呢(这个问题是否曾经相识呢)?我们只需要分析一下append方法便可找到答案。
以上代码是StringBuilder自动扩充最核心的部分,这个方法主要完成了两件事,A,扩大1倍(当然还有+2),B,把原来的数组拷贝到新的数据结构中。
通过以上分析,我们可以用数组,ArrayList分别与String,StringBuilder做类比,不难看出java中所谓的自动扩容本质。
3,Map,真对于Map数据结构,我们讨论最常用的HashMap数据结构。Map也是我们平时最常使用的结构,他提供了一种字典的语义。通过Map我们很容易的建立一种一一对应的关系。
HashMap是通过数组+链表的数据结构来实现的,如图
在hashmap中有如下代码段![]()
这是一个数组结构。这个结构直接对应了上图中的第一列entry数组。
由于篇幅问题,这里不粘贴代码了。大家有兴趣的可以看看put方法,存入一条数据主要需要几个步骤
A,计算key的hash值,通过%或者&的方式寻找数组对应的位置
B,如果该数组位置还没有数组,直接创建Node对象存入该数组位置,负责
C,node对象本身又是一个链表的结构,新创建Node对象连接到该链表的头部或者尾部(注意,不同版本的jdk可能不一致)
通过以上三个步骤完成了一个新节点的添加,我们可以简单理解成HashMap就是一个数组,只是数组存储的元素本身又是一个链表。考虑极端情况,如果散列的不够好的话所有的数据都在一条链表上,那整个hashmap就成了一个链表,这个性能是极端差也是不允许出现的。这就有了HashMap重新计算hash值,对整个数据结构进行重新分配的方法。不难想象这个过程是损耗性能的,特别当数据量很大时。由于时间关系,本文暂时省略这个过程
通过以上过程的分析我们可以看出,要存储一个对象,为其存储的辅助对象比链表更为复杂,更费内存。还有一个细节就是在使用map时尽量为其分配一个合理的初始值,以避免HashMap自动扩容,一旦自动扩容,就会导致hash值重新计算,会殃及整个表的数据结构。还有HashMap的容量是2的n次幂的方式存在的,所以尽量给出2的n次幂的数值,以减少初始值的计算。
4,Set,我们常用的HashSet是以HashMap为根本设计的,数据结构完全一致,只是value为这是为空对象了,这里不再复述。
有关集合类的数据结构到这里基本接近尾声了,我们通过数据结构中两类最简单的结构,数组和链表讨论了java集合工具中的list,queue,map等数据结构。如果回去查看一下整个集合类的子集,你会发现,已经基本上囊括了集合类的大部分内容。除了TreeMap这种为排序而生的数据结构使用了树结构,大部分都是基于这两种数据结构创建的。深入理解这些数据结构能够使我们在实际应用中减少很对不必要的性能损失和内存浪费。虽然现在内存和cpu都已经很廉价了,但是追求程序的最佳性能,依然是程序员每个程序员的奋斗目标。