系统全面的认识Solr
文章包括:组件关系,简单搭建,solr目录结构,solr源码分析,Solr性能参数,
链接数据库导数据,Solrj操作索引,自动补齐,解析核心配置文件solrconfig.xml,schema.xml等。
其中还包含来自其他博客的优秀资源。
Solr 是什么?
Solr 是一个开源的企业级搜索服务器,底层使用易于扩展和修改的 Java 来实现。服务 器通信使用标准的 HTTP 和 XML ,所以如果使用Solr 了解 Java 技术会有用却不是必须的要求。
Solr主要特性有:强大的全文检索功能,高亮显示检索结果,动态集群,数据库接口和 电子文档(Word ,PDF 等)的处理。而且 Solr具有高度的可扩展,支持分布搜索和索引的复制。
Solr资源
solr wiki:
http://wiki.apache.org/solr
https://cwiki.apache.org/confluence/display/solr/Apache+Solr+Reference+Guide
solr自动补齐,树结构:
http://www.cnblogs.com/rush/archive/2012/12/30/2839996.html
其他文章:
http://www.aidansu.com/blog/1361.html
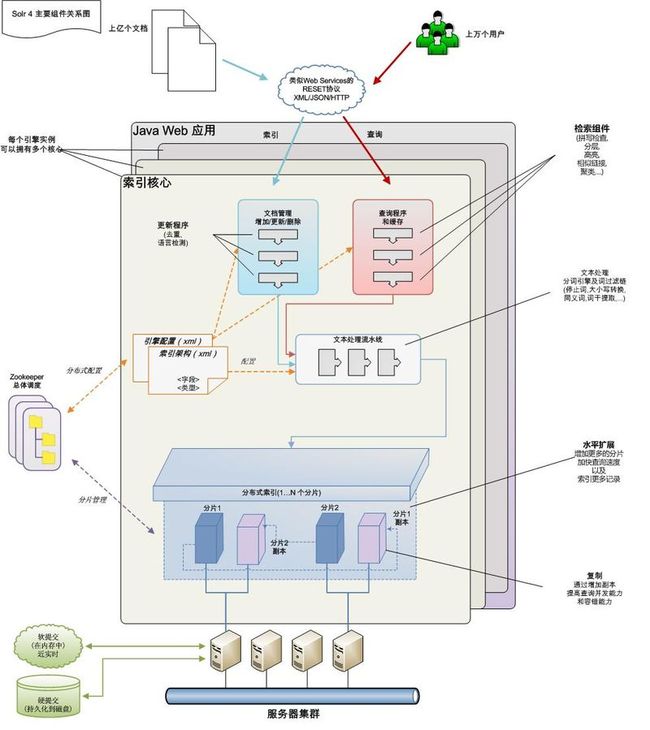
Solr各个组件关系图
solr程序包的目录结构
➔ contrib :存放爱好者贡献的代码。
➔ dist :存放Solr 构建完成的 JAR 文件、WAR 文件和 Solr 依赖的 JAR 文件。
➔ example :是一个安装好的Jetty 中间件,其中包括一些样本数据和 Solr 的配置信息。
➔ example/etc :Jetty 的配置文件。
➔ example/multicore :当安装Slor multicore 时,用来放置多个 Solr 主目录。
➔ example/example-DIH :可以作为solr的主目录,里面包含多个索引库,以及hsqldb的数据,里面有连接数据库的配置示例,以及邮件、rss的配置示例。
➔ example/solr :默认安装时一个Solr 的主目录。
➔ example/webapps :Solr 的 WAR 文件部署在这里。
➔ docs:Solr 的文档。
solr 主目录的目录结构
一个运行的 Solr 服务其主目录包含了 Solr 的配置文件和数据(Lucene 的索引文件) Solr 的主目录展开后为如下结构:
➔ bin :建议将集群复制脚本放在这个目录下。
➔ collection1 :solr的example默认的一个索引库
➔ collection1/conf :放置配置文件。
➔ collection1/conf/schema.xml :建立索引的 schema 包含了字段类型定义和其相关的分析器。
➔ collection1/conf/solrconfig.xml :这个是Solr 主要的配置文件。
➔ collection1/conf/xslt :包含了很多xslt 文件,这些文件能将 Solr 的 XML 的查询结果转换为特定的格式,比如:Atom/RSS 。
➔ data :放置 Lucene 产生的索引数据。
solr简易安装
1)把下载下来的solr解压
2)打开命令提示符(开始–>运行–>cmd–>回车),cd到apache-solr-4.0.0文件夹下的example文件夹
3)输入命令:java -jar start.jar
4)打开浏览器输入网址:http://localhost:8983/solr/ 就可以浏览到solr的主页了
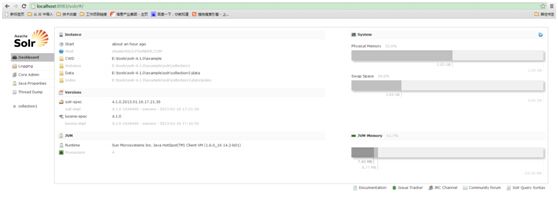
5)往solr添加数据:打开一个新的命令提示符,cd到apache-solr-4.0.0文件夹下的example文件夹下的exampledocs文件夹,输入命令:java -jar post.jar -h(帮助命令,可以查看post.jar的执行参数) 执行完毕后再输入:java -jar post.jar *.xml
这时查看solr默认的索引库collection1就能看到增加了新的索引文档
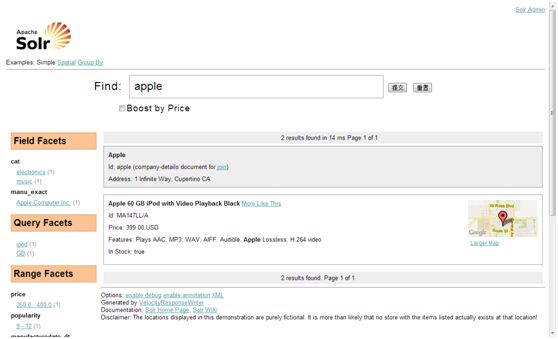
6)尝试查询数据:打开浏览器输入网址:http://localhost:8983/solr/collection1/browse 在Find:输入窗口输入:apple 按提交按钮即可搜索到有关apple的信息。
solr+Tomcat部署
1)将E:\tools\solr-4.1.0\dist\solr-4.1.0.war拷贝到Tomcat的webapp目录下
2)solr.solr.home的配置:主要有两种
基于环境变量solr.solr.home
在当前用户的环境变量中(.bash_profile)或在/opt/tomcat/catalina.bat中添加如下环境变量
export JAVA_OPTS="$JAVA_OPTS -Dsolr.solr.home=/opt/solr-tomcat/solr"
评价:此种方法侵入性太大,需要直接修改TOMCAT启动脚本,因此不建议使用
基于JNDI配置
在tomcat的文件夹下增加solr.xml文件,位置如下tomcat/conf/Catalina/localhost/solr.xml ,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<Context docBase="E:\tools\tomcat\webapps\solr.war" debug="0" crossContext="true" >
<Environment name="solr/home" type="java.lang.String" value="E:\tools\tomcat\webapps\solr" override="true" />
</Context>
评价:此种方法侵入性小,无需修改启动脚本,只需在TOMCAT程序目录的conf/Catalina/localhost下新建一个solr.xml文件即可
3)配置好solr.solr.home之后,直接启动即可。
solr+IKAnalyzer分词
1)下载IK文件包 地址:http://code.google.com/p/ik-analyzer/
2)解压,将其中的jar文件放到之前部署的Tomcat的solr 文件夹下位置如下:\tomcat\webapps\solr\WEB-INF\lib
3)修改配置文件solr/collection1/conf/中的schema.xml
<!-- IKAnalyzer 配置 -->
<fieldType name="text" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
solr分词器配置http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters
solr使用log4j (或见专题文章)
1)将WEB_INF\lib下的slf相关的jar包删除即将slf4j-jdk-1.7.2.jar删除,增加log4j的jar
2)在src文件夹下增加log4j.properties
增加相应配置即可。但是log4j没有实现logWatch,是的solr主页面logging面板无法设置。
solr+eclipse调试环境搭建
源码编译导入
1)在官网下载对应源码,解压
2)使用ant进行编译为eclipse工程,耗时比较长 (ant要求ant1.8.2+ 地址:http://ant.apache.org/)
3)导入eclipse就可以调试了
4)在源码中新建一个WebContent文件夹,复制 solr-4.1.0-src\solr\webapp\web 下的内容至 WebContent;复制 solr-4.1.0-src \solr\example中的solr文件夹复制到 WebContent中,作为solr/home
5)jetty中新建 jetty webapp,设置参数如下

在Arguments面板中的VM arguments中增加 -Dsolr.solr.home=WebContent/solr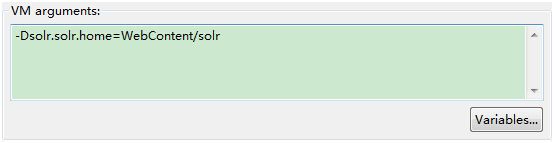
6)启动jetty即可。
solr+jetty嵌入式部署启动
1)找到StartSolrJetty类,修改配置如:
2)直接RUN AS--》JAVA Application即可。
新建空白工程
1)在eclipse中新建一个空白的web 工程
2)将WebContent中的内容全部删除,将solr-4.1.0.war解压,解压出来的文件全部复制到WebContent文件夹中;复制 solr-4.1.0-src\solr\example下的solr 文件夹复制到WebContent中,作为solr/home
3)同上小节中的5)设置,启动jetty即可。
连接数据库导入数据
1)在默认主目录的solrconfig.xml中没有配置DataImportHandler,增加这个配置就可以直接连接数据库导入数据。具体参考:http://wiki.apache.org/solr/DataImportHandler
配置如下:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
2)conf文件夹下新建data-config.xml文件,配置dataSource,配置如下:
<dataConfig>
<dataSource name="jdbc" driver="oracle.jdbc.driver.OracleDriver" url="jdbc:oracle:thin:@//172.18.83.56:1521/orcl" user="boco2" password="boco2"/>
<document name="books">
<entity name="book" query="select * from T_TYBOOK_BEFORE_EBOOKDATABASE">
<field column="CODE" name="code" />
<field column="NAME" name="title" />
<field column="ALTERNATIVETITLE" name="alternativeTitle" />
<field column="CREATOR" name="creator" />
<field column="PRICE" name="price" />
<field column="PUBLISH_DATE" name="publishDate" />
<field column="ISBN" name="isbn" />
<field column="TYPE" name="type" />
<field column="PUBLISH_NAME" name="publishName" />
<field column="PAGE" name="page" />
<field column="ABSTRACT" name="abstract" />
<field column="SALEONDATE" name="saleOnDate" />
<field column="SALEOFFDATE" name="saleOffDate" />
<field column="BOOKSTATE" name="bookState" />
<field column="BOOK_SOURCE" name="bookSource" />
<field column="IMAGE" name="image" />
</entity>
</document>
</dataConfig>
3)修改相应schema.xml,字段与data-config.xml中的字段配置一致,fields块配置如下:
<schema name="example" version="1.5"> <fields> <field name="code" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="title" type="text_general" indexed="true" stored="true" multiValued="false"/> <field name="alternativeTitle" type="text_general" indexed="true" stored="true" multiValued="false"/> <field name="creator" type="text_general" indexed="true" stored="true" multiValued="false"/> <field name="price" type="float" indexed="true" stored="true"/> <field name="publishDate" type="date" indexed="true" stored="true"/> <field name="isbn" type="string" indexed="true" stored="true" multiValued="false" /> <field name="type" type="string" indexed="true" stored="true" multiValued="false"/> <field name="publishName" type="text_general" indexed="true" stored="true" multiValued="false"/> <field name="page" type="int" indexed="true" stored="true"/> <field name="abstract" type="text_ik" indexed="true" stored="true" multiValued="false"/> <field name="saleOnDate" type="date" indexed="true" stored="true"/> <field name="saleOffDate" type="date" indexed="true" stored="true"/> <field name="bookState" type="int" indexed="true" stored="true"/> <field name="bookSource" type="int" indexed="true" stored="true"/> <field name="image" type="string" indexed="false" stored="true"/> <field name="text" type="text_general" indexed="true" stored="false"/> <field name="_version_" type="long" indexed="true" stored="true"/> </fields>
4)启动jetty这是collection1就能够出现dataImport面板。勾选commit,execute执行即可。
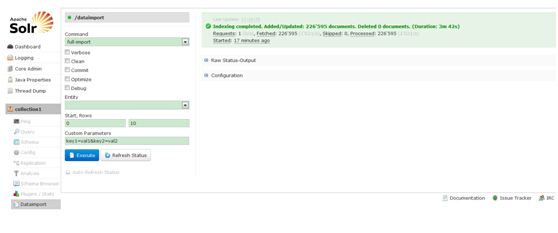
solr配置文件
solr.xml
solr中文wiki地址:http://wiki.chenlb.com/solr/doku.php 不过只翻译了部分文档
主要是配置solr主目录中的索引库即SolrCore
一个solr服务可以配置多个SolrCore,即可以管理多个索引库。
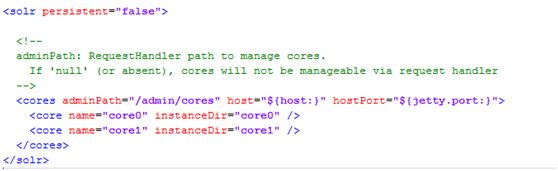
solr MultiCore
个人理解就是多个索引库,索引库的索引数据可以相互切换。
具体参考:http://wiki.apache.org/solr/CoreAdmin
solrconfig.xml
solr系统相关配置
<luceneMatchVersion>声明使用的lucene的版本。
<lib>配置solr用到的jar包,具体语法示例中基本都有了。
<dataDir>如果不用 “Solr home”/data 目录,可以指定其它别的目录来存放所有索引数据。如果使用了 replication,它可以匹配 replication 配置。如果这个目录不是绝对的,那会是当前 servlet 容器工作目录下的相对目录。
<directoryFactory>索引文件的类型,默认solr.NRTCachingDirectoryFactory
这个文件类型包装了solr.StandardDirectoryFactory和小文件内存缓存的类型,来提供NRT搜索性能。NRT--》near-real-time近实时。
<indexConfig>主要索引相关配置
<writeLockTimeout>IndexWriter写锁过时的时间,默认1000
<maxIndexingThreads>最大索引的线程数,默认8
<useCompoundFile>是否使用混合文件,Lucene默认是“true”,solr默认是“false”
<ramBufferSizeMB>使用的内存的大小,默认100,这个实际用的时候应该修改大一点。
<ramBufferdDocs>内存中最大的文档数,默认1000
<mergePolicy>索引合并的策略。默认TiereMergePolicy,合并大小相似的段,与LogByteSizeMergePolicy相似。这个可以合并不相邻的段,能够设置一次合并多少个段,maxMergeAtOnce以及每层能合并多少个段segmentsPerTier。
<mergeFactor>每次合并索引的时候获取多少个段,默认10。等同于同时设置了maxMergeAtOnce和segmentsPerTier两个参数。
<mergeScheduler>段合并器,背后有一个线程负责合并,默认ConcurrentMergeScheduler。
<lockType>文件锁的类型,默认native,使用NativeFSLockFactory。
<unlockOnStartup>默认false
<termIndexInterval>Lucene每次加载到内存的terms数,默认128
<reopenReaders>如果是true时,IndexReaders能够被reopened,而不是先关闭再打开,默认true
<deletionPolicy>删除策略,用户可以自己定制,solr默认的是SolrDeletionPolicy,是solr标准的删除策略,允许在一定时间内保存索引提交点,来支持索引复制,以及快照等特性。可以设置“maxCommitsToKeep”保存提交的数量、“maxOptimizedCommitsToKeep”保存的优化条件的数量、“maxCommitAge”删除所有commit points的时间。
<infoStream>为了调试,Lucene提供了这个参数,如果是true的话,IndexWriter会像设置的文件中写入debug信息。
<jmx>一般不需要设置具体可以查看wiki文档http://wiki.apache.org/solr/SolrJmx
<updateHandler>更新的Handler,默认DirectUpdateHandler2
<updateLog><str name="dir">配置更新日志的存放位置
<autoCommit>硬自动提交,可以配置maxDocs即从上次提交后达到多少文档后会触发自动提交;maxTime时间限制;openSearcher,如果设为false,导致索引变化的最新提交,不需要重新打开searcher就能看到这些变化,默认false。
<autoSoftCommit>如自动提交,与前面的<autuCommit>相似,但是它只是让这些变化能够看到,并不保证这些变化会同步到磁盘上。这种方法比硬提交要快,而且更接近实时更友好。
<listerner event>update时间监听器配置,postCommit每一次提交或优化命令后触发,poatOptimize每次优化命令后触发。RunExecutableListener每次调用后执行一些其他操作。配置项:

<indexReaderFactory>这个配置项用户可以自己扩展IndexReaderFactory,可以自己实现自己的IndexReader。如果要明确声明使用的Factory则可以如下配置:

<query>配置检索词相关参数以及缓存配置参数。
<maxBooleanClauses>每个BooleanQuery中最大Boolean Clauses的数目,默认1024。
<filterCache>为IndexSearcher使用,当一个IndexSearcher Open时,可以被重新赋于原来的值,或者使用旧的IndexSearcher的值,例如使用LRUCache时,最近被访问的Items将被赋予IndexSearcher。solr默认是FastLRUCache 。
cache介绍:http://blog.csdn.net/phinecos/article/details/7876385
filterCache
filterCache存储了无序的lucene documentid集合,该cache有3种用途:
1)filterCache存储了filterqueries(“fq”参数)得到的document id集合结果。Solr中的query参数有两种,即q和fq。如果fq存在,Solr是先查询fq(因为fq可以多个,所以多个fq查询是个取结果交集的过程),之后将fq结果和q结果取并。在这一过程中,filterCache就是key为单个fq(类型为Query),value为document id集合(类型为DocSet)的cache。对于fq为range query来说,filterCache表现出其有价值的一面。
2)filterCache还可用于facet查询(http://wiki.apache.org/solr/SolrFacetingOverview),facet查询中各facet的计数是通过对满足query条件的documentid集合(可涉及到filterCache)的处理得到的。因为统计各facet计数可能会涉及到所有的doc id,所以filterCache的大小需要能容下索引的文档数。
3)如果solfconfig.xml中配置了<useFilterForSortedQuery/>,那么如果查询有filter(此filter是一需要过滤的DocSet,而不是fq,我未见得它有什么用),则使用filterCache。
<queryResultCache> 缓存查询的结果集的docs的id。
<documentCache> 缓存document对象,因为document中的内部id是transient,所以autowarmed为0,不能被autowarmed。
<fieldValueCache>字段缓存
<cache name="">用户自定义一个cache,用来缓存指定的内容,可以用来缓存常用的数据,或者系统级的数据,可以通过SolrIndexSearcher.getCache(),cacheLookup(), and cacheInsert().等方法来操作。
<enableLazyFieldLoading>保存的字段,如果不需要的话就懒加载,默认true。
<useFilterForSortedQuery>一般来讲用不到,只有当你频繁的重复同一个搜索,并且使用不同的排序,而且它们都不用“score”
<queryResultWindowSize>queryResultCache的一个参数。
<queryResultMaxDocsCached> queryResultCache的一个参数。
<listener event"newSearcher" class="solr.QuerySenderListener">query的事件监听器。
<useColdSearcher>当一个检索请求到达时,如果现在没有注册的searcher,那么直接注册正在预热的searcher并使用它。如果设为false则所有请求都要block,直到有searcher完成预热。
<maxWarmingSearchers>后台同步预热的searchers数量。
<requestDispatcher handleSelect="false">solr接受请求后如何处理,推荐新手使用false
<requestParsers enableRemoteStreaming="true" multipartUploadLimitInKB="2048000" formdataUploadLimitInKB="2048" />使系统能够接收远程流
<httpCaching never304="true">http cache参数,solr不输出任何HTTP Caching相关的头信息。
<requestHandler>接收请求,根据名称分发到不同的handler。
"/select"检索SearchHandler
"/query"检索SearchHandler
"/get" RealTimeGetHandler
"/browse" SearcherHandler
"/update" UpdateRequestHandler
"/update/json" JsonUpdateRequestHandler
"/update/csv" CSVRequestHandler
"/update/extract" ExtractingRequestHandler
"/analysis/field" FieldAnalysisRequestHandler
"/analysis/document" DocumentAnalysisRequestHandler
"/admin/" AdminHandlers
"/replication" 复制,要有主,有从
<searchComponent>注册searchComponent。
spellcheck 拼写检查
<queryResponseWriter>返回数据
<admin><defaultQuery>默认的搜索词
schema.xml
solr索引相关配置
<fields>块
声明一系列的<field>字段
<field name="" type="" indexde="" stored="" required="" multiValued="" omitNorms="" termVectors="" termPositions="" termOffsets="">
name:名称
type:类型从<types> 的fieldType中取
indexed:是否索引
stored:是否保存
required:是否必须
multiValuer:在同一篇文档中可以有多个值
omitNorms:true的话忽略norms
termVectors:默认false,如果是true的话,要保存字段的term vector
termPositions:保存term vector的位置信息
termOffects:保存term vector的偏移信息
default:字段的默认值
<dynamicField>动态字段,当不确定字段名称时采用这种配置
<types>块
<types> 块内,声明一系列的 <fieldtype>,以 Solr fieldtype类为基础,如同默认选项一样来配置自己的类型。
任何 FieldType 的子类都可以作为 field type 来使用,使用时可以用完整的包名,如果field type 类在 solr 里,那可以用 “solr”代替包名。提供多种不同实现的普通数据类型(integer, float等)。想知道怎么样被 Solr 正确地加载自定义的数据类型,请看:SolrPlugins
通用的选项有:
name:类型名称
class:对应于solr fieldtype类
sortMissingLast=true|false 如果设置为true,那么对这个字段排序的时候,包含该字段的文档就排到不包含该字段的文档前面。
sortMissingFirst=true|false 如果设置为true,那么对这个字段排序的时候,没有该字段的文档排在包含该字段的文档前面
precisionStep 如何理解precisionStep呢?需要一步一步来: 参考文档:http://blog.csdn.net/fancyerii/article/details/7256379
1, precisionStep是在做range search的起作用的,默认值是4
2, 数值类型(int float double)在Lucene里都是以string形式存储的,当然这个string是经过编码的
3,经过编码后的string保证是顺序的,也就是说num1>num2,那么strNum1>strNum2
4,precisionStep用来分解编码后的string,例如有一个precisionStep,默认是4,也就是隔4位索引一个前缀,比如0100,0011,0001,1010会被分成下列的二进制位“0100,0011,0001,1010“,”0100,0011,0001“,0100,0011“,”0100“。这个值越大,那么索引就越小,那么范围查询的性能(尤其是细粒度的范围查询)也越差;这个值越小,索引就越大,那么性能越差。
positionIncrementGap和multiValued一起使用,设置多个值之间的虚拟空白的数量。字段有多个值时使用,如果一篇文档有两个title
> title1: ab cd
> title2: xy zz
如果positionIncrementGap=0,那么这四个term的位置为0,1,2,3。如果检索"cd xy"那么能够找到,如果你不想让它找到,那么就需要调整positionIncrementGap值。如100,那么这是位置为0,1,100,101。这样就不能匹配了。
<fieldType name="random" class="solr.RandomSortField" indexed="true" />这个字段类型可以实现伪随机排序。
analyzer配置 
包括tokenizer和filter,可以配置多个filter
其他配置
<uniqueKey>唯一字段,除非这个字段标记了“required=false”,否则默认为required字段
<copyField>一个源字段一个目的字段,将源字段的内容拷贝到目的字段,可以将多个字段合并,也可以对同一个字段,不同索引方式。
<defaultSearchField>默认的搜索字段
<solrQueryParser defaultOperator="OR"/>默认的检索词间的关系
solr源码
SolrDispatchFilter--过滤器
系统启动时首先运行SolrDispatchFilter.init()方法,该方法要加载CoreContainer的Initializer类,配置文件默认solr.xml
所有的请求都要经过的Filter
SolrResourceLoader--加载配置文件
CoreContainer--管理SolrCore
SolrCore--可以理解为索引库
SolrConfig--解析solrconfig.xml
IndexSchema--解析schema.xml文件
检索参数
CommonParams.java通用检索参数
qt:指定那个类型来处理查询请求,一般不用指定,默认是standard
q:是检索短语
fq:过滤条件如果设置bookState:0的话,检索结果中就会将bookState不是0的结果过滤掉。
wt:返回类型,有json、xml等
sort:分类,publishDate desc,如果多个字段用逗号分隔
start:开始位置
rows:返回条数
fl:返回字段列表,可以返回score查看分数
df:默认检索字段 default field
indent:返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
Raw Query Parameters:直接输入检索语句如:facet=true&facet.query=price:[0 TO 10]&facet.query=price:[10 TO *] 它自动识别这里面的参数,做一个分组统计。
debugQuery:这个勾选之后可以看到文档的分的explain信息。

solr debug
<lst name="prepare">准备时间
<lst name="process">执行时间
HighlightParams高亮检索参数
hl=true:高亮显示
hl.fl:需要高亮的字段
hl.simple.pre/hl.simple.post设置高亮的格式 默认<em></em>
下面文档中详细介绍了高亮的参数:
http://ronxin999.blog.163.com/blog/static/42217920201292951457295/?suggestedreading
FacetParams分组统计检索参数
facet=true:表示需要分组统计
facet.field:分组的字段如果有多个字段facet.field=cat& facet.field=type
facet.quert:范围统计如facet.query=price:[0 TO 10]&facet.query=price:[10 TO *]
facet.range:我们系统中可以使用publishDate的按时间段统计:facet.range=publishDate&facet.range.start=NOW/YEAR-10YEARS&facet.range.end=NOW&facet.range.gap=+1YEAR没成功
dismax与edismax参数
参考:
http://wiki.apache.org/solr/DisMaxRequestHandler?highlight=%28dismax%29
http://wiki.apache.org/solr/DisMaxQParserPlugin
http://wiki.apache.org/solr/ExtendedDisMax?highlight=%28edismax%29
solr 的edismax与dismax比较与分析:
http://blog.csdn.net/duck_genuine/article/details/8060026
dismax是solr的一个比较受欢迎的检索模型 edismax是对dismax的扩展
q.alt:当字段q为空时使用这个作为默认检索
qf:设置字段的权重 creator^15 title^5空格隔开
mm:Minimum 'Should' Match q.op=AND => mm=100%; q.op=OR => mm=0%
qs:Query Phrase Slop 步长
pf:Phrase Fields To specify both a slop and a boost, usefield~slop^boost
如:title~2^10.0 will use the title field with a phrase slop of 2 and a boost of 10.0。 A phrase slop specified here overrides the default specified in "ps"
pf:Default amount of slop on phrase queries built with "pf", "pf2" and/or "pf3" fields (affects boosting).
bq:A raw query string,直接给出权重公式
根据我们的需求定义的检索条件:
http://localhost:8983/solr/collection1/select/?facet=true&indent=true&q=%E4%B8%89%E5%9B%BD&qf=title^15&hl.simple.pre=%3Cem%3E&hl.simple.post=%3C/em%3E&facet.field=bookState&wt=xml&hl=true&fq=type:ZZ&defType=edismax
bf:可以通过函数设置文档权重。例子:
q=foo&bf="ord(popularity)^0.5 recip(rord(price),1,1000,1000)^0.3"
参考:
http://wiki.apache.org/solr/FunctionQuery
自动补齐
使用SpellCheckComponent
http://wiki.apache.org/solr/Suggester
http://www.colorfuldays.org/category/program/solr/
solrconfig.xml中增加如下配置:
<searchComponent class="solr.SpellCheckComponent" name="suggest">
<str name="queryAnalyzerFieldType">text_ik</str>
<lst name="spellchecker">
<str name="name">suggest</str>
<str name="classname">org.apache.solr.spelling.suggest.Suggester</str>
<str name="lookupImpl">org.apache.solr.spelling.suggest.tst.TSTLookupFactory</str>
<!-- Alternatives to lookupImpl:
org.apache.solr.spelling.suggest.fst.FSTLookup [finite state automaton]
org.apache.solr.spelling.suggest.fst.WFSTLookupFactory [weighted finite state automaton]
org.apache.solr.spelling.suggest.jaspell.JaspellLookup [default, jaspell-based]
org.apache.solr.spelling.suggest.tst.TSTLookup [ternary trees]
-->
<str name="field">text_sug</str> <!-- the indexed field to derive suggestions from -->
<float name="threshold">0.005</float>
<str name="buildOnCommit">true</str>
<str name="spellcheckIndexDir">spellchecker</str>
</lst>
</searchComponent>
<requestHandler class="org.apache.solr.handler.component.SearchHandler" name="/suggest">
<lst name="defaults">
<str name="spellcheck">true</str>
<str name="spellcheck.dictionary">suggest</str>
<str name="spellcheck.onlyMorePopular">true</str>
<str name="spellcheck.count">10</str>
<str name="spellcheck.collate">false</str>
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler>
在sechma.xml中增加字段
<field name="text_sug" type="text_ik" indexed="true" stored="true" multiValued="true" />
将title,creator,publishName字段拷贝到text_sug
<copyField source="title" dest="text_sug" /> <copyField source="creator" dest="text_sug" /> <copyField source="publishName" dest="text_sug"/>
http://localhost:8983/solr/suggest?q=中&spellcheck.build=true
就可以看到效果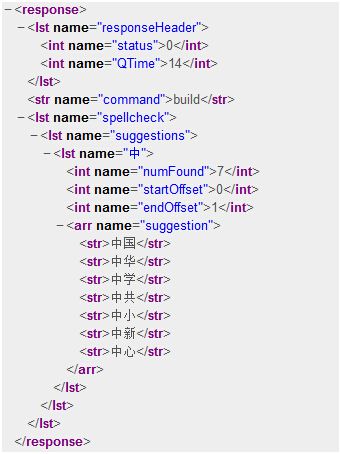
在solrj中拼接请求
// http://localhost:8983/solr/suggest?q=中&spellcheck.build=true
ModifiableSolrParams params = new ModifiableSolrParams();
params.set("qt", "/suggest");
params.set("q", prefix);
params.set("spellcheck.build", "true");
QueryResponse response;
try {
response = server.query(params);
System.out.println("response = " + response);
} catch (SolrServerException e) {
e.printStackTrace();
}
第二种方式使用Facet
//prefix为前缀
public static void autoComplete(SolrServer server, String prefix) {
StringBuffer sb = new StringBuffer("");
SolrQuery query = new SolrQuery("*.*");
QueryResponse rsp= new QueryResponse();
//Facet为solr中的层次分类查询
try {
query.setFacet(true);
query.setFacetMinCount(1);
query.setQuery("*:*");
query.setFacetPrefix(prefix);
query.addFacetField("title_auto");
query.add("fl", "title");
rsp = server.query(query);
System.out.println(query.toString());
System.out.println(rsp.toString());
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
结果为:![]()
Solrj使用
需要使用的jar包
//新建SolrServer
String url = "http://localhost:8983/solr";
SolrServer server = new HttpSolrServer(url);
//定义Document,添加到Server中
SolrInputDocument doc1 = new SolrInputDocument();
doc1.addField( "code", "id1 this", 1.0f );
doc1.addField( "title", "你好", 1.0f );
doc1.addField( "price", 10 );
SolrInputDocument doc2 = new SolrInputDocument();
doc2.addField( "code", "id1 this2", 1.0f );
doc2.addField( "title", "你", 1.0f );
doc2.addField( "price", 20 );
Collection<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
docs.add( doc1 );
docs.add( doc2 );
//更新索引
try {
server.add( docs );
server.commit();
} catch (SolrServerException e) {
log.error(e.getMessage());
} catch (IOException e) {
e.printStackTrace();
}
//或者
UpdateRequest req = new UpdateRequest();
req.setAction( UpdateRequest.ACTION.COMMIT, false, false );
req.add( docs );
try {
UpdateResponse rsp = req.process( server );
} catch (SolrServerException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
//也可以定义Bean,来更新索引
import org.apache.solr.client.solrj.beans.Field;
public class Books {
@Field
String code;
@Field
String title;
@Field
String publishName;
}
Books books = new Books();
books.code = "45678";
books.title = "nihaoaaaa";
books.publishName = "出版社";
try {
server.addBean(books);
server.commit();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SolrServerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//查询数据
SolrQuery query = new SolrQuery();
query.setQuery( "code:45678" );
query.addSortField( "price", SolrQuery.ORDER.asc );
QueryResponse rsp;
try {
rsp = server.query( query );
// SolrDocumentList docs = rsp.getResults();
// System.out.println(docs.get(0).getFieldValue("title"));
List<Books> books = rsp.getBeans(Books.class);
System.out.println(books.get(0).publishName);
} catch (SolrServerException e) {
e.printStackTrace();
}
//删除数据
try {
server.deleteByQuery("code:45678");
server.optimize();
server.commit();
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
具体参考 http://wiki.apache.org/solr/Solrj
solr 的客户端调用solrj 建索引+分页查询:
http://www.blogjava.net/conans/articles/379556.html
solr更新文件格式
索引更新
http://wiki.apache.org/solr/UpdateXmlMessages
http://wiki.apache.org/solr/UpdateJSON
更新可以支持原子更新
update = "add" | "set" | "inc" — for atomic updating and adding of fields
注意:为了实现原子更新,需要在solrconfig.xml中增加updateLog的配置如下:
<updateHandler class="solr.DirectUpdateHandler2">
<!-- ... -->
<updateLog>
<str name="dir">${solr.data.dir:}</str>
</updateLog>
</updateHandler>
查看索引文件luke
http://wiki.apache.org/solr/LukeRequestHandler
在solrconfig.xml中增加如下配置:
<requestHandler name="/admin/luke" class="org.apache.solr.handler.admin.LukeRequestHandler" />
solr性能参数
http://wiki.apache.org/solr/SolrPerformanceFactors
1. mergeFactor Tradeoffs
高的值(如25)
好处:建索引速度快 缺点:少了合并,会导致比较多的索引文件,降低检索速度。
低的值(如2)
好处:索引文件数量少,检索速度快 缺点:建索引速度慢
2. Cache autoWarm Count 考虑
增加filterCache、 queryResultCache和DocumentCache的大小
3. 提交和更新频率的考虑
solr扩展
扩展自己的SearchComponent
实现自己的SearchComponent类
在solrconfig.xml中增加相应配置
<searchComponent name="query" class="my.app.MyQueryComponent" />
扩展自己的updateRequestProcessor
实现自己的类UpdateProcessorFactory然后在solrconfig.xml中如下配置:
<updateRequestProcessorChain name="mychain" >
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="my.app.MyPocessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>
<requestHandler name="/update" class="solr.UpdateRequestHandler">
<!-- See below for information on defining
updateRequestProcessorChains that can be used by name
on each Update Request
-->
<lst name="defaults">
<str name="update.chain">tyreadchain</str>
</lst>
</requestHandler>
s
转载请注明:
http://lucien-zzy.iteye.com/blog/2089674