Jstorm是参考storm的实时流式计算框架,在网络IO、线程模型、资源调度、可用性及稳定性上做了持续改进,已被越来越多企业使用
作为commiter和user,我还是非常看好它的应用前景,下面是在团队内的分享介绍,更多请参考https://github.com/alibaba/jstorm
一、jstorm是什么
jstorm可以看作是storm的java增强版本,除了内核用纯java实现外,还包括了thrift、python、facet ui。从架构上看,其本质是一个基于zk的分布式调度系统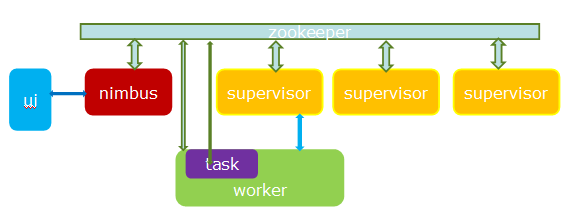
Jstorm主要应用场景有:
1.信息流处理,如聚合、分析等
2.持续计算,如实时数据统计、监控
3.分布式rpc调用
Jstorm在内核上对storm的改进有:
(1)模型简化
(2)多维度资源调度
(3)网络通信层改造
(4)采样重构
(5)worker/task内部异步化处理
(6)classload、HA
模型简化将storm的三层管理模型简化为两层
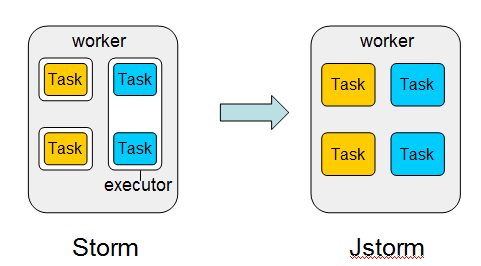
jstorm中task直接对应了线程概念,而在storm中是task只是线程executor的一个执行逻辑单元
多维度资源调度 分为cpu、memory、net、disk四个维度,默认情况下:
cpu slots = 机器核数 * 2 -1
memory slots = 机器物理内存 / 1024M
net slots = min(cpu slots, memory slots)
网络通信层 采用了netty + disruptor 替换 zmq + blockingQueue
采样重构
a.定义了滚动时间窗口
b.优化缓存map性能
c.增量采样时间以及减少无谓数据
Worker/Task内部异步化
异步化和回调是流式框架最基本的两大特征,Jstorm在task的计算中将nextTuple和ack/fail的逻辑分离开来,并在worker中采用单独线程负责流入、流出数据的反序列化及序列化工作
有关jstorm实现的几个关键流程,有兴趣的可以参考源码
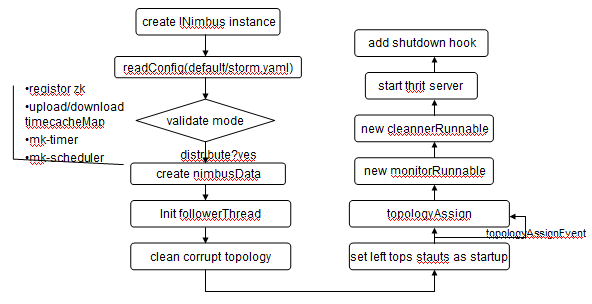
1.Nimbus的启动
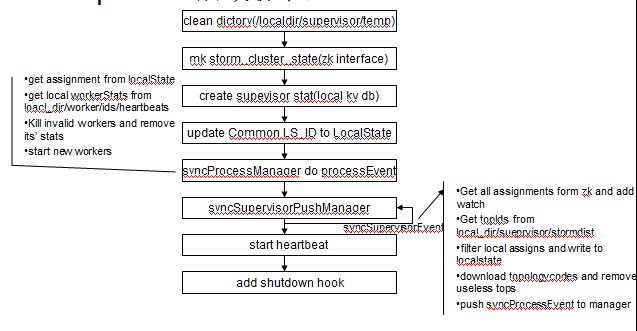
2.supervisor的启动
3. worker内部结构
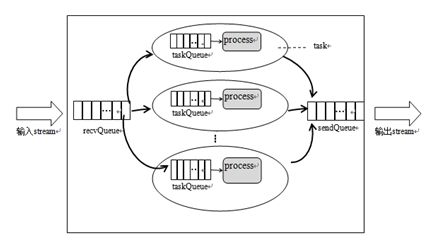
worker的启动需要完成以下几件事:
a.读取配置文件,启动进程
b.初始化tuple接收队列和发送队列
c.打开端口,启动rpc服务
d.创建context结构,<component, <stream, output_field>>
e.触发各种timer,refresh/reconnection/heartbeat...
task的工作包括:
a.创建内部队列,bind connection
b.反射component拿到taskObj,创建具体的spout/bolt executor
c.反序列化tuple数据,执行处理逻辑
d.做stats,heartbeat等
jstorm在数据的完整性和准确性上分别依赖了acker和事务机制
acker本质是独立的bolt,input是fieldGrouping,output是directGrouping;
每个bolt有两个output stream(ACKER_ACK_STREAM_ID/ACKER_ACK_FAIL_STREAM_ID)
每个spout有一个output stream(ACKER_INIT_STREAM_ID),以及两个input stream(ACKER_ACK_STREAM_ID/ACKER_ACK_FAIL_STREAM_ID)
Spout
发送给acker 的value <rootid, xor(target_task_list)>
发送下一级bolt 的value <rootid, 目标taskid>
Bolt
下一级bolt需要ack发送给下一级bolt 为<rootid, 新uuid)>发送给acker的value为<rootid, xor(新uuid, $(接收值))>
下一级bolt不需要ack发送给下一级bolt 为空发送给acker为<rootid, $(接收值)>
事务:批处理+全局唯一递增id+两阶段提交
在发送tuple的时候带上tid来保证“只有一次”的原语,下游逻辑根据tid是否next tid来判断是否需要处理。为了提高效率,会将多个tuple组装成一批赋予一个tid,并用pipeline方式执行processing和commit阶段,其中processing可以并发执行,而commit具有严格的强顺序性。接口coordinator,commitor中做了状态管理、事务协调、错误检查等工作
另外一个用得最多的高级特性就是trident,它对bolt进行了封装,提供了如joins、aggregations、grouping、filters、function等多种高级数据处理能力
最后,谈谈有关jstorm的运维开发
(1)配置优先级:代码 > jstorm.yaml > default.yaml
(2)stream流对比:
a.fieldsGrouping
b.globalGrouping - target componet的第一个task
c.shuffleGrouping - 自定义random,更平均
d.noneGrouping - 调用random
e.allGrouping - target component所有task
f.directGrouping - 指定目标task
g.customGrouping - 接口customStreamGrouping
(3)jvm调优,优先考虑新生代,开启碎片整理
(4)同一worker内的task,开启定向调度避免网络开销
(5)优雅关闭,reblance或kill前先deactive,等待msg_timeout进行数据清理
(6)其它,hooks、queue-size、topology.max.spout.pending等