集合框架 Map篇(1)----HashMap、LinkedHashMap、IdentityHashMap
Map
------
1.HashMap
2.LinkedHashMap
3.IdentityHashMap
4.WeakHashMap
5.TreeMap
6.EnumMap
7.ConcurrentHashMap
8.ConcurrentSkipListMap
-----------------------------------------------------
1.HashMap:
HashMap里面存入的键值对在取出的时候是随机的,是比较常用的Map.它根据key的HashCode值存储数据,根据key可以直接取出它的值(当然也有冲突的情况,不过遍历链表就可了),具有很快的访问速度。在Map中插入、删除和定位元素,HashMap是最好的选择(因为它不必为元素的排序而消耗开销)。
哈希(Hash)相关---Java中的Hash机制(HashMap、HashSet及对其源码解析)
一文中做了详细描述,在这不再重复。
补充一下HashMap的存储结构示意图:
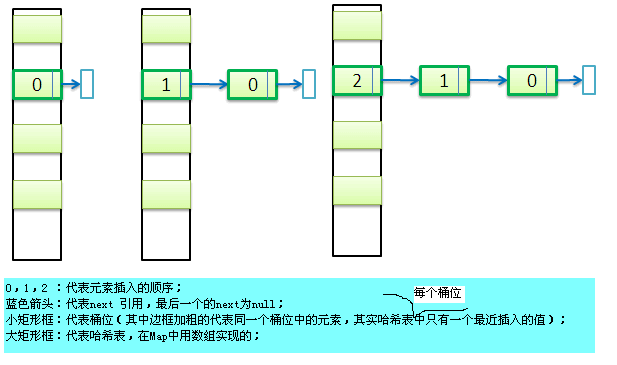
------------------
2.LinkedHashMap
LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。
(1)LinkedHashMap的 Entry[]数组存储结构和HashMap的类似如上图所示:
不同的是,LinkedHashMap多了一个双向链表:
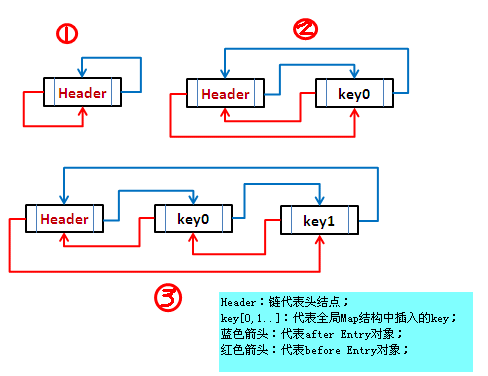
---------------------------------------------------------------------
LinkedHashMap是HashMap的子类,LinkedHashMap是为了解决遍历Hash表的无序问题,它内部维护了一个链表用于记录你插入元素(或你访问元素的顺序)的位置,遍历时直接遍历链表,元素的顺序即为你插入的顺序,同时Entry对象要多加两个成员变量before和after用于记录链表的前驱和后继。所以LinkedHashMap的的存储效率要低于HashMap,但是遍历效率要高于HashMap。
根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用get方法)的链表。
默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。 可以重写removeEldestEntry方法返回true值指定插入元素时移除最老的元素。
-----------------------------------------
3.IdentityHashMap
使用==代替equals()对key进行比较的散列表。专为特殊问题而设计的。
可以参考API的描述:
java.util.IdentityHashMap类利用哈希表实现 Map 接口,比较键(和值)时使用引用相等性代替对象相等性。
换句话说,在 IdentityHashMap 中,当且仅当 (k1==k2) 时,才认为两个键 k1 和 k2 相等(在正常 Map 实现(如 HashMap)中,
当且仅当满足下列条件时才认为两个键 k1 和 k2 相等:(k1==null ? k2==null : e1.equals(e2)))。
此类不是 通用 Map 实现! 此类实现 Map 接口时,它有意违反 Map 的常规协定, 该协定在比较对象时强制使用 equals 方法。
此类设计仅用于其中需要引用相等性语义的罕见情况。 此类的典型用法是拓扑保留对象图形转换,如序列化或深层复制。
要执行这样的转换,程序必须维护用于跟踪所有已处理对象引用的“节点表”。 节点表一定不等于不同对象,即使它们偶然相等也如此。此类的另一种典型用法是维护代理对象。 例如,调试设施可能希望为正在调试程序中的每个对象维护代理对象。
此类提供所有的可选映射操作,并且允许 null 值和 null 键。此类对映射的顺序不提供任何保证;特别是不保证顺序随时间的推移保持不变。
此类提供基本操作(get 和 put)的稳定性能,假定系统标识了将桶间元素正确分开的哈希函数 (System.identityHashCode(Object))。
此类具有一个调整参数(影响性能但不影响语义):expected maximum size。此参数是希望映射保持的键值映射关系最大数。
在内部,此参数用于确定最初组成哈希表的桶数。未指定所期望的最大数量和桶数之间的确切关系。
默认的价值加载因子为2/3,在重新哈希后,加载因子变为1/3.当哈希表中的条目数超出了加载因子与当前容量的乘积时,通过调用 reszie 方法将容量翻倍,重新进行哈希。增加桶数,重新哈希,可能相当昂贵。
因此创建具有足够大的期望最大数量的标识哈希映射更合算。另一方面,对 collection 视图进行迭代所需的时间与哈希表中的桶数成正比,
所以如果特别注重迭代性能或内存使用,则不宜将期望的最大数量设置得过高。 IdentityHashMap 源码分析:
--------------------------------------------
------
1.HashMap
2.LinkedHashMap
3.IdentityHashMap
4.WeakHashMap
5.TreeMap
6.EnumMap
7.ConcurrentHashMap
8.ConcurrentSkipListMap
-----------------------------------------------------
1.HashMap:
HashMap里面存入的键值对在取出的时候是随机的,是比较常用的Map.它根据key的HashCode值存储数据,根据key可以直接取出它的值(当然也有冲突的情况,不过遍历链表就可了),具有很快的访问速度。在Map中插入、删除和定位元素,HashMap是最好的选择(因为它不必为元素的排序而消耗开销)。
哈希(Hash)相关---Java中的Hash机制(HashMap、HashSet及对其源码解析)
一文中做了详细描述,在这不再重复。
补充一下HashMap的存储结构示意图:
------------------
2.LinkedHashMap
LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。
(1)LinkedHashMap的 Entry[]数组存储结构和HashMap的类似如上图所示:
不同的是,LinkedHashMap多了一个双向链表:
---------------------------------------------------------------------
LinkedHashMap是HashMap的子类,LinkedHashMap是为了解决遍历Hash表的无序问题,它内部维护了一个链表用于记录你插入元素(或你访问元素的顺序)的位置,遍历时直接遍历链表,元素的顺序即为你插入的顺序,同时Entry对象要多加两个成员变量before和after用于记录链表的前驱和后继。所以LinkedHashMap的的存储效率要低于HashMap,但是遍历效率要高于HashMap。
根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用get方法)的链表。
默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。 可以重写removeEldestEntry方法返回true值指定插入元素时移除最老的元素。
public class LinkedHashMap<K, V> extends HashMap<K, V> implements Map<K, V> {
//-------------比父类HashMap多出的两个成员变量----------------------------
//双向链表的头部
private transient Entry<K, V> header;
//true表示按照访问顺序迭代,false时表示按照插入顺序
private final boolean accessOrder;
//-------------5个构造函数---------------------------
/**5个构造函数,都是通过super调用父类的实现,可以参考HashMap
*并在前4个构造中默认该LinkedHashMap对象是按照插入顺序迭代的,
*在最后一个构造中可以设定accessOrder*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
/**
*遍历Map的顺序的boolean变量:
*true为按访问顺序遍历;
*false为按插入顺序遍历
*/
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
//------------------init()方法是在HashMap构造函数初始化的时候调用的,
//HashMap中是空实现,LinkedHashMap重写了init方法。代码中表达的意思也很明确了,这是双向链表的初始化状态。
void init() {
header = new Entry<K, V>(-1, null, null, null);
header.before = header.after = header;
}
/*该transfer()是Hashtable中的实现:遍历整个表的各个桶位,然后对桶进行遍历得到每一个Entry,重新hash到newTable中,
//我放在这里是为了和下面LinkedHashMap重写该法的比较,
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
*/
/**
*transfer()方法是其父类HashMap调用resize()的时候调用的方法,它的作用是表扩容后,把旧表中的key重新hash到新的表中。
*这里从写了父类HashMap中的该方法,是因为考虑到,LinkedHashMap拥有的双链表,在这里Override是为了提高迭代的效率。
*/
void transfer(HashMap.Entry[] newTable) {
int newCapacity = newTable.length;
for (Entry<K, V> e = header.after; e != header; e = e.after) {
int index = indexFor(e.hash, newCapacity);
e.next = newTable[index];
newTable[index] = e;
}
}
/**
*查找Map中是否包含给定的value,还是考虑到,LinkedHashMap拥有的双链表,在这里Override是为了提高迭代的效率。
*/
public boolean containsValue(Object value) {
// Overridden to take advantage of faster iterator
if (value == null) {
for (Entry e = header.after; e != header; e = e.after)
if (e.value == null)
return true;
} else {
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
}
return false;
}
/**
*通过key得到value,
*关键是:e.recordAccess(this);这一句,它的作用可以查看recordAccess()方法,
*如果是accessOrder==true,就是按照访问顺序存储,就是把本次访问的元素移到链表尾部
*(这也使得Header的before指向尾部元素,可以参考上图),表示最新访问的元素。
*/
public V get(Object key) {
Entry<K, V> e = (Entry<K, V>) getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
/**clear链表,设置header为初始状态*/
public void clear() {
super.clear();
header.before = header.after = header;
}
/**
*LinkedHashMap为了实现额外的双链表结构,实现了自己特有的Entry结构:主要是为了实现迭代多了两个向前向后的两个引用befor和after
*/
private static class Entry<K, V> extends HashMap.Entry<K, V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K, V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K, V> next) {
super(hash, key, value, next);
}
/**
* remove
*/
private void remove() {
before.after = after;
after.before = before;
}
/**
* 插入到Header的前面,在父类中是调用addBefore(header)实现加入元素的,具体可以参考上面的双链表结构的图示
*/
private void addBefore(Entry<K, V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
/**
* 当调用父类的put或putAll方法,发现要插入的键已经存在时会调用此方法,
* 当调用LinkedHashMap的get方法时会调用此方法。
* 如果LinkedHashMap是按访问顺序遍历的,就移动此Entry到链表的最后位置。
*/
void recordAccess(HashMap<K, V> m) {
LinkedHashMap<K, V> lm = (LinkedHashMap<K, V>) m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K, V> m) {
remove();
}
}
private abstract class LinkedHashIterator<T> implements Iterator<T> {
Entry<K, V> nextEntry = header.after;
Entry<K, V> lastReturned = null;
/**
* 通过和modCount比较,用于判断并发不同步的情况,不同步时会抛出ConcurrentModificationException异常
*/
int expectedModCount = modCount;
public boolean hasNext() {
return nextEntry != header;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
Entry<K, V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K, V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
private class KeyIterator extends LinkedHashIterator<K> {
public K next() {
return nextEntry().getKey();
}
}
private class ValueIterator extends LinkedHashIterator<V> {
public V next() {
return nextEntry().value;
}
}
private class EntryIterator extends LinkedHashIterator<Map.Entry<K, V>> {
public Map.Entry<K, V> next() {
return nextEntry();
}
}
// These Overrides alter the behavior of superclass view iterator() methods
Iterator<K> newKeyIterator() {
return new KeyIterator();
}
Iterator<V> newValueIterator() {
return new ValueIterator();
}
Iterator<Map.Entry<K, V>> newEntryIterator() {
return new EntryIterator();
}
/**
* 重写父类addEntry方法(该方法是在put操作时调用的),判断是否去掉header。after所对应的Entry
* 如果是则删掉,否则判断键值对的个数是否超过了临界值,如果超过了就进行扩容
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed, else grow capacity if appropriate
Entry<K, V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
}
/**
* 重写了父类中的方法,多了e.addBefore(header);将元素插入到了链表尾 也就是赋值给header.before
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K, V> old = table[bucketIndex];
Entry<K, V> e = new Entry<K, V>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
//是否在添加一个元素后移除最老的元素header.after
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return false;
}
}
-----------------------------------------
3.IdentityHashMap
使用==代替equals()对key进行比较的散列表。专为特殊问题而设计的。
可以参考API的描述:
public class IdentityHashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Serializable, Cloneable
java.util.IdentityHashMap类利用哈希表实现 Map 接口,比较键(和值)时使用引用相等性代替对象相等性。
换句话说,在 IdentityHashMap 中,当且仅当 (k1==k2) 时,才认为两个键 k1 和 k2 相等(在正常 Map 实现(如 HashMap)中,
当且仅当满足下列条件时才认为两个键 k1 和 k2 相等:(k1==null ? k2==null : e1.equals(e2)))。
此类不是 通用 Map 实现! 此类实现 Map 接口时,它有意违反 Map 的常规协定, 该协定在比较对象时强制使用 equals 方法。
此类设计仅用于其中需要引用相等性语义的罕见情况。 此类的典型用法是拓扑保留对象图形转换,如序列化或深层复制。
要执行这样的转换,程序必须维护用于跟踪所有已处理对象引用的“节点表”。 节点表一定不等于不同对象,即使它们偶然相等也如此。此类的另一种典型用法是维护代理对象。 例如,调试设施可能希望为正在调试程序中的每个对象维护代理对象。
此类提供所有的可选映射操作,并且允许 null 值和 null 键。此类对映射的顺序不提供任何保证;特别是不保证顺序随时间的推移保持不变。
此类提供基本操作(get 和 put)的稳定性能,假定系统标识了将桶间元素正确分开的哈希函数 (System.identityHashCode(Object))。
此类具有一个调整参数(影响性能但不影响语义):expected maximum size。此参数是希望映射保持的键值映射关系最大数。
在内部,此参数用于确定最初组成哈希表的桶数。未指定所期望的最大数量和桶数之间的确切关系。
默认的价值加载因子为2/3,在重新哈希后,加载因子变为1/3.当哈希表中的条目数超出了加载因子与当前容量的乘积时,通过调用 reszie 方法将容量翻倍,重新进行哈希。增加桶数,重新哈希,可能相当昂贵。
因此创建具有足够大的期望最大数量的标识哈希映射更合算。另一方面,对 collection 视图进行迭代所需的时间与哈希表中的桶数成正比,
所以如果特别注重迭代性能或内存使用,则不宜将期望的最大数量设置得过高。 IdentityHashMap 源码分析:
public V put(K key, V value) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
Object item;
while ( (item = tab[i]) != null) {
if (item == k) {
V oldValue = (V) tab[i + 1];
tab[i + 1] = value;
return oldValue;
}
i = nextKeyIndex(i, len);
}
modCount++;
tab[i] = k;//这和HashMap中的Entry的区别之处,IdentityHashMap保存key 在i,value就这i+1处,
tab[i + 1] = value;
if (++size >= threshold)
resize(len); // len == 2 * current capacity.
return null;
}
private static int nextKeyIndex(int i, int len) {//IdentityHashMap特有的键值存储方式决定了i+2的步长,寻找下一个key
return (i + 2 < len ? i + 2 : 0);
}
public V get(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
while (true) {
Object item = tab[i];//i为键的位置是,值的位置就是i+1
if (item == k)
return (V) tab[i + 1];
if (item == null)
return null;
i = nextKeyIndex(i, len);
}
}
public boolean equals(Object o) {
if (o == this) {//这是其equals的实现要点,比较的是关键字key对象引用,而不是像HashMap中的那样用equals比较
return true;
} else if (o instanceof IdentityHashMap) {
IdentityHashMap m = (IdentityHashMap) o;
if (m.size() != size)
return false;
Object[] tab = m.table;
for (int i = 0; i < tab.length;i+=2) {//步长为2
Object k = tab[i];
if (k != null && !containsMapping(k, tab[i + 1]))
return false;
}
return true;
} else if (o instanceof Map) {
Map m = (Map)o;
return entrySet().equals(m.entrySet());
} else {
return false; // o is not a Map
}
} 所以虽然称为IdentityHashMap,它和java.util.HashMap的实现有很大的区别。(当然,有hash操作的map 就可以称为hashmap)
--------------------------------------------