垂直爬虫 webmagic
新版文档地址
http://webmagic.io/docs/zh/,
http://webmagic.io/docs/zh/posts/ch1-overview/README.html
webmagic的使用文档: https://github.com/code4craft/webmagic/blob/master/user-manual.md
webmagic的设计文档:webmagic的设计机制及原理-如何开发一个Java爬虫 http://my.oschina.net/flashsword/blog/145796
XPath 语法 http://www.w3school.com.cn/xpath/xpath_syntax.asp
Xsoup: 抽取工具简介 http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/xsoup.html
如何用爬虫webmagic采集图片(demo附源代码) http://www.oschina.net/code/snippet_1397325_35514
一些错误解决办法:
code error 403 http://www.oschina.net/question/989118_154456
使用Maven
WebMagic基于Maven进行构建,推荐使用Maven来安装WebMagic。在项目中添加以下坐标即可:
WebMagic使用slf4j-log4j12作为slf4j的实现.如果你自己定制了slf4j的实现,请在项目中去掉此依赖。
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
以下是爬取oschina博客的一段代码:
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
webmagic包含强大的页面抽取功能,开发者可以便捷的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。例如:
webmagic也可以很方便的作为一个模块,嵌入Java项目中运行。webmagic的使用可以参考:oschina openapi 应用:博客搬家 http://my.oschina.net/oscfox/blog/194507
第一个项目
在你的项目中添加了WebMagic的依赖之后,即可开始第一个爬虫的开发了!我们这里拿一个抓取Github信息的例子:
webmagic的使用文档: https://github.com/code4craft/webmagic/blob/master/user-manual.md
webmagic的设计文档:webmagic的设计机制及原理-如何开发一个Java爬虫 http://my.oschina.net/flashsword/blog/145796
XPath 语法 http://www.w3school.com.cn/xpath/xpath_syntax.asp
Xsoup: 抽取工具简介 http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/xsoup.html
如何用爬虫webmagic采集图片(demo附源代码) http://www.oschina.net/code/snippet_1397325_35514
一些错误解决办法:
code error 403 http://www.oschina.net/question/989118_154456
使用Maven
WebMagic基于Maven进行构建,推荐使用Maven来安装WebMagic。在项目中添加以下坐标即可:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.4.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.4.3</version>
</dependency>
WebMagic使用slf4j-log4j12作为slf4j的实现.如果你自己定制了slf4j的实现,请在项目中去掉此依赖。
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.4.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
以下是爬取oschina博客的一段代码:
Spider.create(new SimplePageProcessor("http://my.oschina.net/",
"http://my.oschina.net/*/blog/*")).thread(5).run();
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
webmagic包含强大的页面抽取功能,开发者可以便捷的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。例如:
String extractResult = Html.create(html).$("div.body")
.xpath("//a/@href").regex(".*blog.*").toString();
webmagic也可以很方便的作为一个模块,嵌入Java项目中运行。webmagic的使用可以参考:oschina openapi 应用:博客搬家 http://my.oschina.net/oscfox/blog/194507
第一个项目
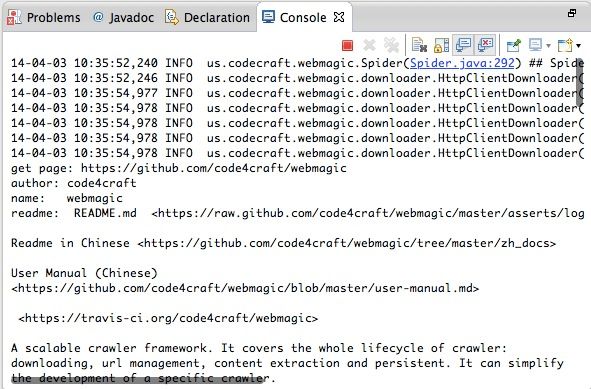
在你的项目中添加了WebMagic的依赖之后,即可开始第一个爬虫的开发了!我们这里拿一个抓取Github信息的例子:
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class GithubRepoPageProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
@Override
public void process(Page page) {
page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all());
page.putField("author", page.getUrl().regex("https://github\\.com/(\\w+)/.*").toString());
page.putField("name", page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()").toString());
if (page.getResultItems().get("name")==null){
//skip this page
page.setSkip(true);
}
page.putField("readme", page.getHtml().xpath("//div[@id='readme']/tidyText()"));
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor()).addUrl("https://github.com/code4craft").thread(5).run();
}
}