Map-side join is also known as replicated join, and gets is name from the fact that the smallest of the datasets is replicated to all the map hosts. You can find a implementation in Hadoop in Action. Another implementation is using CompositeInputFormat, which is shown in this blog post. The goal of this blog post is to create a generic replicated join framework that work with any datasets, you can find the source code shown in this blog post from the awesome book Hadoop in Practice.
The class disgram for this framework is shown below: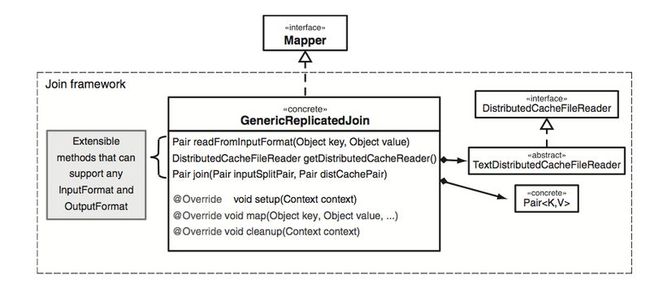
This replicated join framework will provide an implementation of the join (class GenericReplicatedJoin), which out of the box works with KeyValueTextInputFormat and TextOutputFormat, and assumes that the first token in each file is the join key. But the join class can be extended to support any input and output format.
The basic behavior of this map-side join is described as follows:
The mapper setup method determines if the map's input split is larger than the distributed cache, in which case it loads the distributed cache into memory. The map function either performs a join or caches the key/value pairs, based on whether the setup method loaded the cache. If the input split is smaller than the distributed cache, the map cleanup method will read the records in the distrbuted cache and join them with the cache created in the map function.
Source code of the join framework shown below:
package com.manning.hip.ch4.joins.replicated;
public class Pair<K, V> {
private K key;
private V data;
public Pair() {
}
public Pair(K key, V data) {
this.key = key;
this.data = data;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getData() {
return data;
}
public void setData(V data) {
this.data = data;
}
}
You can customize the DistributedCacheFileReader shown as below to read data files in any format.
package com.manning.hip.ch4.joins.replicated;
import java.io.File;
import java.io.IOException;
public interface DistributedCacheFileReader<K, V> extends Iterable<Pair<K, V>> {
public void init(File f) throws IOException;
public void close();
}
Below is the default implementation of the DistributedCacheFileReader to read tab splitted text files.
package com.manning.hip.ch4.joins.replicated;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.LineIterator;
import org.apache.commons.lang.StringUtils;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
public class TextDistributedCacheFileReader
implements DistributedCacheFileReader<String, String>,
Iterator<Pair<String, String>> {
LineIterator iter;
@Override
public void init(File f) throws IOException {
iter = FileUtils.lineIterator(f);
}
@Override
public void close() {
iter.close();
}
@Override
public Iterator<Pair<String, String>> iterator() {
return this;
}
@Override
public boolean hasNext() {
return iter.hasNext();
}
@Override
public Pair<String, String> next() {
String line = iter.next();
Pair<String, String> pair = new Pair<String, String>();
String[] parts = StringUtils.split(line, "\t", 2);
pair.setKey(parts[0]);
if (parts.length > 1) {
pair.setData(parts[1]);
}
return pair;
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
The core of the framework, note that the joined data will happen in map method or in cleanup method based on the total files size in distributed cache.
package com.manning.hip.ch4.joins.replicated;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class GenericReplicatedJoin
extends Mapper<Object, Object, Object, Object> {
private Map<Object, List<Pair>> cachedRecords =
new HashMap<Object, List<Pair>>();
private boolean distributedCacheIsSmaller;
private Path[] distributedCacheFiles;
/**
* Transforms a record from the input split to a Pair object. The
* input splits are ostensibly larger than the Distributed Cache file.
* <p/>
* This implementation works with keys and values produced with the
* KeyValueTextInputFormat, or any InputFormat which yeilds keys and
* values with meaningful toString methods. For other input formats, this method
* should be overridden to convert the key/value into a Pair where
* the key is text.
*
* @param key the key emitted by the {@link org.apache.hadoop.mapreduce.InputFormat}
* @param value the key emitted by the {@link org.apache.hadoop.mapreduce.InputFormat}
* @return a Pair object, where the key is a Text object containing
* the key for joining purposes, and the value contains data which
* will be used when creating the composite output key
*/
public Pair readFromInputFormat(Object key, Object value) {
return new Pair<String, String>(key.toString(), value.toString());
}
/**
* Get the object which will be used to read data from the
* Distributed Cache file. The Distrubuted Cache files are referred
* to as "R" files. They are ostensibly the smaller files compared
* to "L" files.
* <p/>
* The default implementation provides an implementation that works
* with line-based text files, where keys and values are separated
* with whitespace.
*
* @return a reader which can unmarshall data from the Distributed
* Cache
*/
public DistributedCacheFileReader getDistributedCacheReader() {
return new TextDistributedCacheFileReader();
}
/**
* Join together a record from the input split and Distributed Cache
* and return a new pair which will be emitted by the Map.
* <p/>
* If a null is returned, no output will be produced.
* <p/>
* The default implementation assumes that the Pair keys and values
* are Strings and concatenates them together delimited by the
* tab character.
* <p/>
* This should be overridden in cases where the values aren't Strings,
* or to change how the output value is created.
*
* @param inputSplitPair a record from the input split
* @param distCachePair a record from the Distributed Cache
* @return a composite output value which is compatible with the
* expected value type for the {@link org.apache.hadoop.mapreduce.OutputFormat}
* used for this job
*/
public Pair join(Pair inputSplitPair, Pair distCachePair) {
StringBuilder sb = new StringBuilder();
if (inputSplitPair.getData() != null) {
sb.append(inputSplitPair.getData());
}
sb.append("\t");
if (distCachePair.getData() != null) {
sb.append(distCachePair.getData());
}
return new Pair<Text, Text>(
new Text(inputSplitPair.getKey().toString()),
new Text(sb.toString()));
}
@Override
protected void setup(
Context context)
throws IOException, InterruptedException {
distributedCacheFiles = DistributedCache.getLocalCacheFiles(
context.getConfiguration());
int distCacheSizes = 0;
for (Path distFile : distributedCacheFiles) {
File distributedCacheFile = new File(distFile.toString());
distCacheSizes += distributedCacheFile.length();
}
if (context.getInputSplit() instanceof FileSplit) {
FileSplit split = (FileSplit) context.getInputSplit();
long inputSplitSize = split.getLength();
distributedCacheIsSmaller = (distCacheSizes < inputSplitSize);
} else {
// if the input split isn't a FileSplit, then assume the
// distributed cache is smaller than the input split
//
distributedCacheIsSmaller = true;
}
System.out.println(
"distributedCacheIsSmaller = " + distributedCacheIsSmaller);
if (distributedCacheIsSmaller) {
for (Path distFile : distributedCacheFiles) {
File distributedCacheFile = new File(distFile.toString());
DistributedCacheFileReader reader =
getDistributedCacheReader();
reader.init(distributedCacheFile);
for (Pair p : (Iterable<Pair>) reader) {
addToCache(p);
}
reader.close();
}
}
}
private void addToCache(Pair pair) {
List<Pair> values = cachedRecords.get(pair.getKey());
if (values == null) {
values = new ArrayList<Pair>();
cachedRecords.put(pair.getKey(), values);
}
values.add(pair);
}
@Override
protected void map(Object key, Object value, Context context)
throws IOException, InterruptedException {
System.out.println("K[" + key + "]");
Pair pair = readFromInputFormat(key, value);
if (distributedCacheIsSmaller) {
joinAndCollect(pair, context);
} else {
addToCache(pair);
}
}
public void joinAndCollect(Pair p, Context context)
throws IOException, InterruptedException {
List<Pair> cached = cachedRecords.get(p.getKey());
if (cached != null) {
for (Pair cp : cached) {
Pair result;
if (distributedCacheIsSmaller) {
result = join(p, cp);
} else {
result = join(cp, p);
}
if (result != null) {
context.write(result.getKey(), result.getData());
}
}
}
}
@Override
protected void cleanup(
Context context)
throws IOException, InterruptedException {
if (!distributedCacheIsSmaller) {
System.out.println("Outputting in cleanup");
for (Path distFile : distributedCacheFiles) {
File distributedCacheFile = new File(distFile.toString());
DistributedCacheFileReader reader =
getDistributedCacheReader();
reader.init(distributedCacheFile);
for (Pair p : (Iterable<Pair>) reader) {
joinAndCollect(p, context);
}
reader.close();
}
}
}
}
Finally the driver class:
package com.manning.hip.ch4.joins.replicated;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Main {
public static void main(String... args) throws Exception {
runJob(new Path(args[0]), new Path(args[1]), new Path(args[2]));
}
public static void runJob(Path inputPath,
Path smallFilePath,
Path outputPath)
throws Exception {
Configuration conf = new Configuration();
FileSystem fs = smallFilePath.getFileSystem(conf);
FileStatus smallFilePathStatus = fs.getFileStatus(smallFilePath);
if (smallFilePathStatus.isDir()) {
for (FileStatus f : fs.listStatus(smallFilePath)) {
if (f.getPath().getName().startsWith("part")) {
DistributedCache.addCacheFile(f.getPath().toUri(), conf);
}
}
} else {
DistributedCache.addCacheFile(smallFilePath.toUri(), conf);
}
Job job = new Job(conf);
job.setJarByClass(Main.class);
job.setMapperClass(GenericReplicatedJoin.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setNumReduceTasks(0);
outputPath.getFileSystem(conf).delete(outputPath, true);
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
job.waitForCompletion(true);
}
}