Hiphop是Facebook开发一款PHP二进制化的一个工具,最开始是由php转为C++,但是后来发现编译为c++的话,许多的时间会花费在编译代码上面,调试不方便,对于代码来说也不是即见即所得。
所以hiphop经历了这么几个阶段:
HPHPC=>HPHPI=>HHVM
HPHPC是静态编译,也就是把php转为c++
HPHPI是一个过渡产品,类似php zend虚拟机,性能还不如zend虚拟机,但是可以运行查看效果;
HHVM是在HPHPI基础上,应用了JIT技术,性能已经接近了HPHPC,目前facebook打算慢慢抛弃HPHPC;
性能上HPHPC和HHVM比zend虚拟机+加速器要节约cpu在50%在300%间(官方提供),我实际应用中,一般节约CPU在100%-300%间左右,流量越大越明显。
目前我们使用的HHVM,但是我先分析HPHPC,HPHPC有助于理解Hiphop的整体原理,HHVM可以进一步分析虚拟机原理,对于理解虚拟机HHVM代码是个不错的项目。
在HPHP2.0以前的HIPHOP,都是通过动态表来进行保存类表、变量常量表、函数表等,HPHP2.0以后动态表已经取消了。
我目前分析如下HPHPC的过程,HHVM以后我会再分享:
原理分析一:编译原理+简单词法语法分析
原理分析二:hiphop词法分析、语法分析和语义分析1
原理分析三:hiphop语法分析和语义分析2
原理分析四:hiphop语法推导和优化代码
原理分析五:hiphop 代码输出和server运行
现在开始分析第一节:编译原理+简单词法语法分析
主要内容
1. 编译原理引入
1.1 编译器结构
1.2 hiphop 编译器结构
1.3 词法分析器
1.4 语法分析器
1.5 语义分析器
1.6 中间代码生成器
1.7 代码优化器
1.8 代码生成器
2.hiphop 编译原理分析
2.1hiphop 编译处理流程
2.2 hiphop 词法分析
2.3 hiphop 语法分析
1. 编译原理引入
要想熟悉HPHP,首先要对编译原理有一定的了解,才可以熟悉hiphop的原理;
1.1. 编译器结构

1.字符流
2.生成Token
3.生成语法树
4.语法制导翻译,生成抽象语法树,分作用域将信息存到符号表中
5.通过抽象语法树或三地址代码生成中间形式代码
6.将中间形式代码进行优化
7.生成目标机器码
8.目标机器码内进行代码优化生成目标机器码
例:a=b+c*60
词法分析:
首先,把这个表达式拆解成不同的词,根据类型拆解,然后标注上ID
<float,1> < equal ,2> <float,3> < add ,4> <float ,5> < mul,6> <int,7>
语法分析:
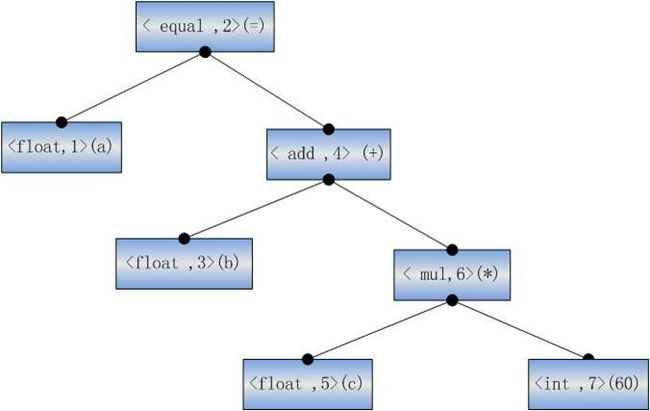
这里将这个表达式拆解为一个语法树,后面的数字是ID,在书的叶子中,标注了具体的拆解的词,生成了一个语法树;
语义分析:

这是一个简单的语义分析,hphp中会复杂的多,如c是一个float而60是一个int,所以这里将60转换为float,但是语义不仅仅这么简单
中间代码生成:
中间代码生成,是解析语法树,然后生成个中间代码,如HPHPC,就是用C++ 做了中间代码,下面的一个小例子,由树根向上解析,最终形成一个中间代码段:
t1=intfloat(60)
t2=float3*t1
t3=float2+t2
float1=t3
代码优化器:
形成中间代码后,然后可以将一些可以合并和优化的代码进行最大化的优化,可提高性能,如HPHP就分为preoptimizer和postoptimizer,在代码推倒前后分别进行一次优化,其实静态编译只是做了编译器的前一部分而已;
t1=float3*60.0
float1=float2+t1
代码生成器:
生成机器码
如果是HPHPC编译的话,那么最终生成机器嘛,而HHVM则是生成机器码,自身还是一个容器,内部有自己的一套类似汇编的一个虚拟机;
1.2. hiphop 编译器结构
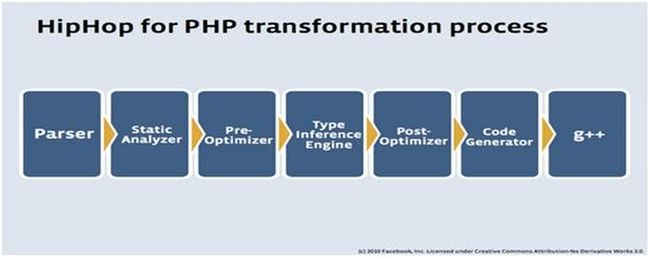
前端:
Parser :词法、语法分析
Static Analyzer: 语法制导翻译,生成抽象语法树(语义分析)
Type Inference Engine: 语义分析
Pre-optimizer,Post-optimizer:代码优化分析
Code generate:中间代码生成部分
后端:
G++
1.3. 词法分析器
词法分析主要是进行划分词法元素单元(token),词法单元格式:<token-name,attribute-value>
一般词法分析阶段都是通过正则分析来进行划分词法单元
一般词法分析都使用lex工具进行分析
例: a=b+c*60
划分词法单元:
a :<float,1>
= : < equal ,2>
b : <float ,3>
+ : < add ,4>
c : <float ,5>
* : < mul,6>
60 : <int,7>
1.4. 语法分析器
语法分析器的作用是从词法分析获取一个由词法单元组成的串,并能够分析和恢复其中的错误继续处理其他部分,然后构造出一颗语法分析树,并把它提供给编译器其他部分进行下一步处理。
1.4.1 设计文法
1.4.2 自顶向下的语法分析
1.4.3 自底向上的语法分析
1.4.1. 设计文法
1. 词法分析和语法分析的区别
(1)词法为何使用正则表达式:
语法结构分为词法和非词法方便讲编译器前端模块化
词法比较简单,需要语法那样的强大功能进行描述规则
和语法相比,正则表达式提供了更加简洁且易于理解的表示词法单元的方法
正则表达式自动构造得到的词法分析器效率要高于根据任意文法自动构造得到的分析器
(2)词法分析
正则表达式适合描述诸如标示符、常量、关键字、空白这样的语言结构
(3)语法分析
文法适合描述嵌套结构、比如对称括号对,配对的beigin-end,互相对应的if-then-else,这些嵌套结构不能使用正则表达式描述。
2. 消除二义性
文法Stmtif expr then stmt
| if expr then stmt else stmt
| other
复合条件语句:if E1 then S1else if E2 then S2 else S3
注:
竖线后是展开的statement,最小的是expression
此处的else存在两种解释:
① if E1 ② if E1
then S1 thenS1
else
if E2 else
if E2
then S2 thenS2
else else
then S3 then S3
由于上面的语法是if 和else的 没有else if,所以造成第二个else不知道是和第一个if匹配还是和第二个if匹配了
3. 左递归消除
exprexpr+term
这样的话,expr就会进入无限的循环:
expr expr+term+term
exprexpr+term+term+term
exprexpr+term+term+……+term
这样就没有终结了,所以一般改写为:
exprexpr+term|term
这样当找到终结符term时,他就不会再进行递归了,这样就消除了左递归
4. 提取左公因子
一种文法转换方法,可产生适用于自顶向下分析的文法。
如 stmtàif exprthen stmt else stmt
| if expr then stmt
当看到if时不知道选择哪个产生式展开stmt。
Aa |aβ2是A的两个产生式,α是非空串。此时我们将A展开为αA‘ 从而将决定后延。在读入α的推导后在决定将A’展开为1还是2,最后提取左公因子原来产生式变为
AàαA‘
A‘àβ1|β2
举个例子来说:
比如
If a==1 then b=1
那么这时候,要选择表达式是选择ifexpr then stmt 还是if expr then stmt else stmt
那么就这么推导
α是if expr then stmt
A =>if expr then stmt A‘
A‘=>| else stmt
1.4.2. 自顶向下分析
Number
Expr :Number|
Expr+Expr|
Expr – Expr|
Expr * Expr|
Expr / Expr;
简单来说就是从树根到树叶
1.4.3. 自底向上分析(移进归约)
如:我们将“1+2/3+4*6-3-2”逐个字符移进堆栈,如下所示:
.1+2/3+4*6-3
E= num 规约a 0
E = E / E 规约b 1
E = E * E 规约c 1
E = E + E 规约d 2
E = E - E 规约e 2
=================================================
1 1.+2/3+4*6-3 移进
2 E.+2/3+4*6-3 规约a
3 E+.2/3+4*6-3 移进
4 E+2./3+4*6-3 移进
5 E+E./3+4*6-3 规约a
6 E+E/.3+4*6-3 移进
7 E+E/3.+4*6-3 移进
8 E+E/E.+4*6-3 规约a
9 E+E/E+.4*6-3 移进
10 E+E/E+4.*6-3 移进
11 E+E/E+E.*6-3 规约a
12 E+E/E+E*.6-3 移进
13 E+E/E+E*6.-3 移进
14 E+E/E+E*E.-3 规约a
15 E+E/E+E*E-.3 移进
16 E+E/E+E*E-3. 移进
17 E+E/E+E*E-E. 规约a
18 E+E+E*E-E. 规约b
19 E+E+E-E. 规约c
20 E+E-E. 规约d
21 E-E. 规约d
22 E. 规约e
1.5. 语义分析器
语义分析器使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。同时也收集类型信息,并把这些信息放到语法树或符号表中。
语义分析重要部分:类型检查和抽象语法树。
类型检查包括:①类型检查规则。
②类型转换。
③函数及运算符重载。
④类型推导和多态函数。
抽象语法树:
如:表达式: 9-5+2
抽象语法树:
9-5+2

实线是抽象语法树
虚线代表输出的内容
1.6. 中间代码生成器
中间代码可用多种方式表示包括抽象语法树和三地址代码,其中抽象语法树方式能够对结构体进行遍历,而三地址方式则能进行控制流并方便的进行重组。
抽象语法树:

¢ 三地址代码:基于两个概念(x=y op z)
如:x+y*z翻译成三地址指令序列t1= y*z t2=x+t1 (t1,t2为临时名字)
a=b*-c+b*-c的三地址代码如下
t1=-c
t2=b*t1
t3=-c
t4=b*t3
t5=t2+t4
a=t5
If x goto y

1.7. 代码优化器和代码生产器
1.7代码优化器
代码优化器是对中间代码进行优化使它生成更少的指令。有两种方法:①减少拷贝指令的数目。②充分考虑上下文的情况,在最初生成指令时就减少生成的指令
1.8 代码生成器
生成目标机器码
参考:
草木瓜的yacc和lex教程:
http://blog.csdn.net/liwei_cmg/article/details/1530492
编译原理(第2版) (美),阿霍等著
下一节:hiphop原理分析1(2)(hiphop 编译原理分析)