Blog is a kind of art.It describes the progress of your running on this road.
Here comes the words from my god.
It is a capital mistake to theorize before one has data.Insensibly one begins to twist facts to suit theories,instead of theories to suit facts.------Sherlock Holmes
许久不写博客,意味着意识的懈怠,也许也意味着方向的迷茫,补上一篇很早时候做的经典算法,无损编码之哈弗曼编码。
一.哈弗曼编码是什么
哈弗曼编码是一种变长编码,普通编码采用定长编码的方式,比如使用三位二进制来表示八个不同的码值,这样是很耗空间的,哈弗曼编码一是为了使用变长编码来表示更多的编码提高信源编码的有效性,二是针对字符概率的差异所设计的编码能大大提高内存空间的利用率。
二.哈弗曼树生成的方法
哈弗曼编码的生成方式是基于一种贪心法的策略(GA)。
(1)首先统计信源中符号的个数和出现的频率并排序,up or down whatever。
(2)从统计队列中取出两个最小值合成一个节点并添加到原来队列中再排序。(合成节点频率为两小者之和,合成后两小者移出队列)
(3)重复(2)直到只剩下一个节点
三.哈弗曼编码
上一步得到了一个根节点,所有的信源已经在逻辑上关联成树形结构了,而编码就是从根节点出发经过左子树编码为0,经过右子树编码为1。取个范例给大家看看。
符号 概率 码值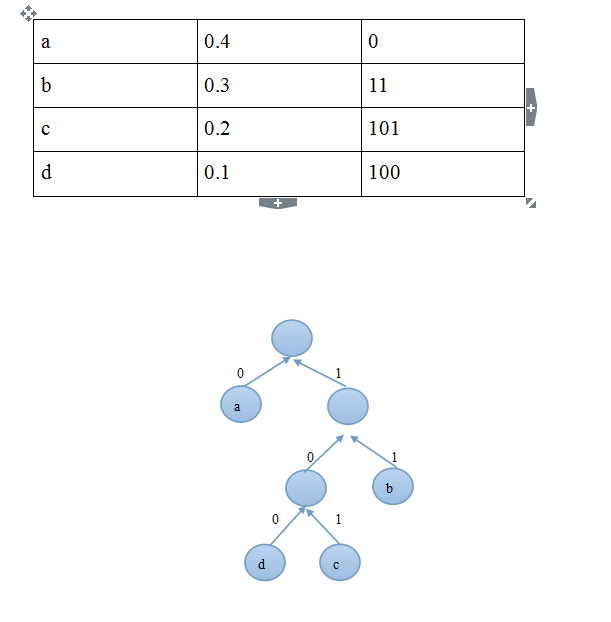
如图所示,所有的有用信息都是存在叶子节点,而从根节点到达叶子节点所走过的路径可为0011所编码,叶子所在的深度越深表明信源出现的频率越低,使用高频短码低频长码编辑的哈弗曼码制具有良好的压缩性。
生成方法有两种,可用队列和链表实现,本质上都是一个PQ,保证实时有序.

CodeList.java
package demo1;
public class CodeList {
int number=1;
HuffmanNode[] node=new HuffmanNode[number];
//添加进入码表
public void add(HuffmanNode end)
{
HuffmanNode newend =new HuffmanNode();
if(number!=1)
{
HuffmanNode[] newNode =new HuffmanNode[number];
for(int i=0;i<newNode.length-1;i++)
{
newNode[i]=new HuffmanNode();
newNode[i]=node[i];
}
newend.setKey(end.getKey());
newend.setValue(end.getValue());
newend.setCode(end.getCode());
newNode[number-1]=newend;
node=newNode;
}
else
{
newend.setKey(end.getKey());
newend.setValue(end.getValue());
newend.setCode(end.getCode());
node[0]=newend;
}
number++;
}
//遍历码表
public void readCode()
{
for(int i=0;i<number-1;i++)
System.out.println(node[i].getKey()+" "+node[i].getValue()+" "+node[i].getCode());
}
//匹配码表字符
public String matchCode(char c)
{
int index=-1;
for(int i=0;i<node.length;i++)
{
if(node[i].getKey()==c)
{
index=i;
break;
}
}
if(index==-1)
return null;
else
return node[index].getCode();
}
}
HuffmanNode.java
package demo1;
/**
* 哈弗曼树的节点累 存储数据 left right 提供关联节点的方法
* HuffmanNode left;
HuffmanNode right;
char key;
int value;
属性的getter和setter
*
* @author me
*
*/
public class HuffmanNode {
HuffmanNode left;
HuffmanNode right;
char key;
int value;
String code;
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public HuffmanNode getLeft() {
return left;
}
public void setLeft(HuffmanNode left) {
this.left = left;
}
public HuffmanNode getRight() {
return right;
}
public void setRight(HuffmanNode right) {
this.right = right;
}
public char getKey() {
return key;
}
public void setKey(char key) {
this.key = key;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
}
MainCode .java
package demo1;
import java.util.HashMap;
import java.util.Iterator;
import java.util.PriorityQueue;
import java.util.Set;
/**哈弗曼压缩程序的入口
*
*
* 哈弗曼树是一个基于频率统计的编码树
* 使用长码对频率小的数据进行编码,使用短码进行频率高的数据进行编码
* 哈树第一步 统计频率并排序
* 哈树第二步 建树---使用优先队列实现:频率低的生成一个父节点并再排序进入一个长度比原先少一个长度的数组中,循环往复直到长度为1
* 哈树第三步 编码 左子树为0右子树为1 直到叶子节点才能拥有自己的编码
* 哈树压缩第一步 文件读写和码表的保存
*
*
*
*/
public class MainCode {
public static void main(String[] args) {
String test="aaabbbbccd";
String s="";
MainCode main =new MainCode();
HashMap map=main.countStr(test);
Set key=map.keySet();
Iterator retu=key.iterator();
char[] freconcy=new char[map.size()];
int[] getValue=new int[map.size()];
//获得键,值的集合
for(int i=0;retu.hasNext();i++)
{
Object keyget=retu.next();
freconcy[i]=(Character)keyget;
getValue[i]=(Integer)map.get(freconcy[i]);
}
main.sort(freconcy,getValue);
//优先队列
HuffmanNode[] Nodes =new HuffmanNode[freconcy.length];
for(int i=0;i<freconcy.length;i++)
{
Nodes[i]=new HuffmanNode();
Nodes[i].setValue(getValue[i]);
Nodes[i].setKey(freconcy[i]);
}
//新建一个优先队列
PQueue queue=new PQueue(Nodes);
//建树的主要部分
while(queue.getLen()>=2)
{
HuffmanNode parent=new HuffmanNode();
//设置左右孩子
parent.setLeft(queue.getNodes()[queue.getLen()-1]);
parent.setRight(queue.getNodes()[queue.getLen()-2]);
//合并成父节点
parent.setValue(queue.getNodes()[queue.getLen()-1].getValue()+
queue.getNodes()[queue.getLen()-2].getValue());
//加入父节点并排序
queue.DeleteNode(parent);
queue.sortNode();
}
//遍历出树
HuffmanNode root=new HuffmanNode();
root=queue.getNodes()[0];
CodeList list=new CodeList();
main.read(root,s,list);
list.readCode();
System.out.println(test);
char[] getMsg=test.toCharArray();
for(int i=0;i<getMsg.length;i++)
System.out.print(list.matchCode(getMsg[i]));
}
//统计字符串中字符出现的频率
//使用HashMap作为工具
public HashMap countStr(String str)
{
HashMap<Character,Integer> map=new HashMap<Character,Integer>();
char[] arr=str.toCharArray();
for(int i=0;i<arr.length;i++)
{
char key=arr[i];
if(!map.containsKey(key))
map.put(key, 1);
else
{
Integer value=map.get(key);
value++;
map.put(key, value);
}
}
return map;
}
//排序
public void sort(char[] array,int getValue[])
{
char temp;
int temp1;
for(int i=0;i<array.length;i++)
for(int j=i;j<array.length;j++)
{
if(getValue[i]<getValue[j])
{
temp=array[i];
array[i]=array[j];
array[j]=temp;
temp1=getValue[i];
getValue[i]=getValue[j];
getValue[j]=temp1;
}
}
}
//遍历算法
//编码
public void read(HuffmanNode root,String s,CodeList list)
{
if(root.getLeft()!=null)
{
read(root.getLeft(),s+"0",list);
}
if(root.getRight()!=null)
{
read(root.getRight(),s+"1",list);
}
if(root.getLeft()==null && root.getRight()==null)
{
HuffmanNode temp=new HuffmanNode();
temp.setKey(root.getKey());
temp.setValue(root.getValue());
temp.setCode(s);
list.add(temp);
System.out.println(root.getKey()+" running in the read "+root.getValue()+" code="+s);
}
}
}
PQueue.java
package demo1;
/**
* 自实现一个优先队列
* @author me
*
*/
public class PQueue {
int length;
HuffmanNode[] nodes;
public PQueue(HuffmanNode[] G)
{
length=G.length;
nodes=new HuffmanNode[length];
for(int i=0;i<length;i++)
{
nodes[i]=new HuffmanNode();
nodes[i].setValue(G[i].getValue());
nodes[i].setKey(G[i].getKey());
}
sortNode();
}
//节点排序
public void sortNode()
{
HuffmanNode temp;
for(int i=0;i<length;i++)
for(int j=i;j<length;j++)
{
if(nodes[i].getValue()<nodes[j].getValue())
{
temp=nodes[i];
nodes[i]=nodes[j];
nodes[j]=temp;
}
}
for(int i=0;i<nodes.length;i++)
{
System.out.println(nodes[i].getKey()+" run in the queue "+nodes[i].getValue());
}
System.out.println();
}
//删除一个节点
public void DeleteNode(HuffmanNode combine)
{
HuffmanNode[] newNode =new HuffmanNode[length-1];
//拷贝数据
for(int i=0;i<newNode.length-1;i++)
{
newNode[i]=new HuffmanNode();
newNode[i]=nodes[i];
}
newNode[newNode.length-1]=combine;
length=newNode.length;
nodes=newNode;
}
//返回长度
public int getLen()
{
return length;
}
//返回节点
public HuffmanNode[] getNodes()
{
return nodes;
}
}