Hadoop应用系列2--MapReduce原理浅析(下)
上面我们分析气温的那段程序,看起没有问题,用起来也没有问题。
试想一下,如果我们把全球所有气象站的数据拿来分析, 你的程序大约需要多久能计算出结果?或者说能否完成运算?
以前我们会把来自不同气象站的数据在不同时间,或者不同计算机上进行运算,最后把结果拿来,再次执行运算。
有了MapReduce咱就不用这么麻烦了,MapReduce做了这样几件事:
0、分布式并行
1、他把输入和输出分开。Mapper负责读取数据,把需要计算的数据输出给Reducer,
也就是说,我们刚才写的程序addYearAndTemperature和out他们是天然的2个程序。
2、本身就是为分布式而设计的,他会把来自多个输入(map)的结果自动的合并并输出(reduce)
3、总是读取本地数据进行运算(相当于我们让不同的计算机分析来自不同气象站的数据)
不知道我说清楚了没有,如果有不清楚的地方欢迎讨论和拍砖。
下面我们来使用hadoop来编写MapReduce程序,来完成同样的功能,注意Mapper是Reducer的输入哦。
我们先来编写Mapper吧,就是把年份和气温取出的程序。
到此我的mapper编写完成,记住它相当于 addYearAndTemperature 这个哦。
接下来我们写 Reducer , 它想当于out
到此, 我们Reducer程序编写完成。
让MapReduce程序运行, 我们需要些调度器(job)作业。
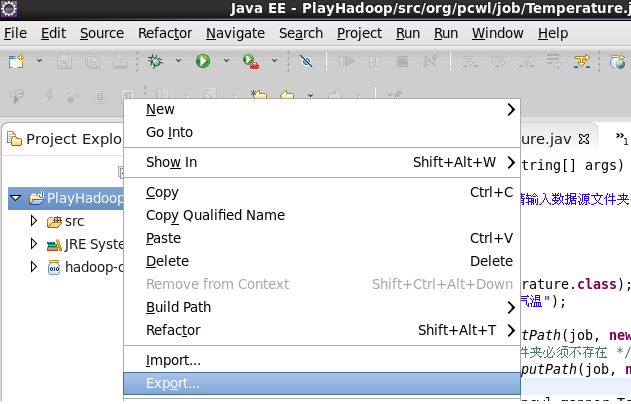
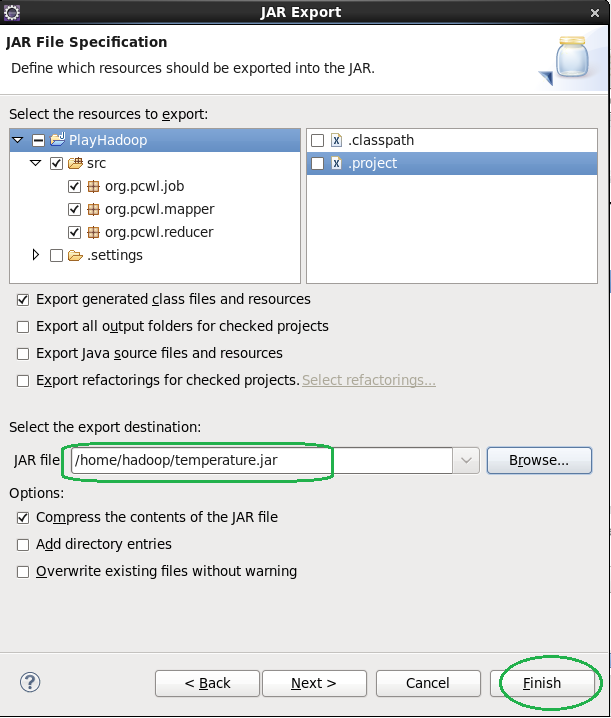
到此我们这个MapReduce就搞定了, 打jar包运行它


下一篇我们将要研究一下Combiner
试想一下,如果我们把全球所有气象站的数据拿来分析, 你的程序大约需要多久能计算出结果?或者说能否完成运算?
以前我们会把来自不同气象站的数据在不同时间,或者不同计算机上进行运算,最后把结果拿来,再次执行运算。
有了MapReduce咱就不用这么麻烦了,MapReduce做了这样几件事:
0、分布式并行
1、他把输入和输出分开。Mapper负责读取数据,把需要计算的数据输出给Reducer,
也就是说,我们刚才写的程序addYearAndTemperature和out他们是天然的2个程序。
2、本身就是为分布式而设计的,他会把来自多个输入(map)的结果自动的合并并输出(reduce)
3、总是读取本地数据进行运算(相当于我们让不同的计算机分析来自不同气象站的数据)
不知道我说清楚了没有,如果有不清楚的地方欢迎讨论和拍砖。
下面我们来使用hadoop来编写MapReduce程序,来完成同样的功能,注意Mapper是Reducer的输入哦。
我们先来编写Mapper吧,就是把年份和气温取出的程序。
package org.pcwl.mapper; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * <p><b>用于读取气象信息,从气象信息中分解出年份和气温的程序。</b></p> * <p> * MapReduce的mapper需要继承Mapper<T1,T2,T3,T4>类 * 重写map(T1,T2,T3,T4)方法 * </p> * <p> * T1表示mapper的输入key类型,T2表示mapper输入的value类型,我们可以把他理解为 * <em>hadoop的文件读取其,把数据读进来之后装入到一个java.util.Map<K,V>中, * 我们从这个java.util.Map<K,V>中读取数据, 这里T1就是这个K的类型.T2就是V的类型</em> * <i> * 注意:输入到mapper中的数据是以行为单位的(\n) 你懂的。 * value是当前行,key可以看作是行号 * </i> * </p> * <p> * T3,T4表示mapper的输出类型,也是Reducer的输入类型,我们可以理解为<em> * mapper程序把需要reducer计算的数据写入一个java.util.Map<K,V>中, * T3,表示这个K的类型,T4表示这个V的类型。 * </em> * </p> * <p> * <strong> * 注意:这里类型不能使用java自身的类型, * 我们使用<i>org.apache.hadoop.io</i>这个包下的类型 * ,他们是为分布式并行而设计的类型 * LongWritable---视为java.lang.Long的替代类型 * Text---视为java.lang.String的替代类型 * IntWritable---视为java.lang.Integer的替代类型 * </strong> * </p> * @author [email protected];eastzhang.iteye.com * */ public class Temperature extends Mapper<LongWritable, Text, Text, IntWritable> { /* 已知的错误数据值 */ private static final int MISSING = 9999; @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { /* 从value取出值,得到String */ String line = value.toString(); /* 从字符串中提出年份信息 */ String year = line.substring(15, 19); int temperature; if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs temperature = Integer.parseInt(line.substring(88, 92)); } else { temperature = Integer.parseInt(line.substring(87, 92)); } if (temperature != MISSING) { /* 把合法数据送入到reducer */ context.write(new Text(year), new IntWritable(temperature)); } } }
到此我的mapper编写完成,记住它相当于 addYearAndTemperature 这个哦。
接下来我们写 Reducer , 它想当于out
package org.pcwl.reducer; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * <p>Reducer 程序需要继承<code>org.apache.hadoop.mapreduce.Reducer<T1,T2,T3,T4></code> * 重写reduce<T1,Iterable<T2>,T3,T4>方法。 * <p> * <p> * 这里T1,T2 是 Reducer的输入类型,也是Mapper的输出类型, * <b>注意map的输出和reduce的输入必须一致哟.<b> * T3,T4是Reducer的输出类型,也就是写入文件中数据类型。 * 根据你程序要写入文件的结果确定类型吧。 * </p> * @author [email protected];eastzhang.iteye.com * */ public class Temperature extends Reducer<Text, IntWritable, Text, IntWritable> { @Override /** * <strong>注意这里values是个迭代器</strong>也就是说,Reducer是对一个集合进行处理, * 这一点在@see http://eastzhang.iteye.com/blog/1775734有体现 */ public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { /* 要计算最高气温,我们来个无穷小,作为比较量 */ int maxValue = Integer.MIN_VALUE; for (IntWritable value : values) { maxValue = Math.max(maxValue, value.get()); } /* key 是 年份, 我们把结果写入到文件中 */ context.write(key, new IntWritable(maxValue)); } }
到此, 我们Reducer程序编写完成。
让MapReduce程序运行, 我们需要些调度器(job)作业。
package org.pcwl.job; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 运行MapReduce的程序(job)作业 * @Author [email protected]; [email protected] */ public class Temperature { public static void main(String[] args) throws Exception { if (args.length != 2) { System.err.println("请输入数据源文件夹<以存在>和目标文件夹<不存在>"); System.exit(-1); } Job job = new Job(); job.setJarByClass(Temperature.class); job.setJobName("计算最高气温"); /* 指定从何出读取数据 */ FileInputFormat.addInputPath(job, new Path(args[0])); /* 指定结果写入何处,注意文件夹必须不存在 */ FileOutputFormat.setOutputPath(job, new Path(args[1])); /* 设置Mapper程序 */ job.setMapperClass(org.pcwl.mapper.Temperature.class); /* 设置Reducer程序 */ job.setReducerClass(org.pcwl.reducer.Temperature.class); /* 指定输出结果类型 */ job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
到此我们这个MapReduce就搞定了, 打jar包运行它
下一篇我们将要研究一下Combiner