SAX 解析XML
在java中,原生解析xml文档的方式有两种,分别是:Dom解析和Sax解析
Dom解析功能强大,可增删改查,操作时会将xml文档以文档对象的方式读取到内存中,因此 适用于小文档
Sax解析是从头到尾逐行逐个元素读取内容,修改较为不便,但 适用于只读的大文档
本文主要讲解Sax解析,其余放在后面
Sax采用事件驱动的方式解析文档。简单点说,如同在电影院看电影一样,从头到尾看一遍就完了,不能回退(Dom可来来回回读取)
在看电影的过程中,每遇到一个情节,一段泪水,一次擦肩,你都会调动大脑和神经去接收或处理这些信息
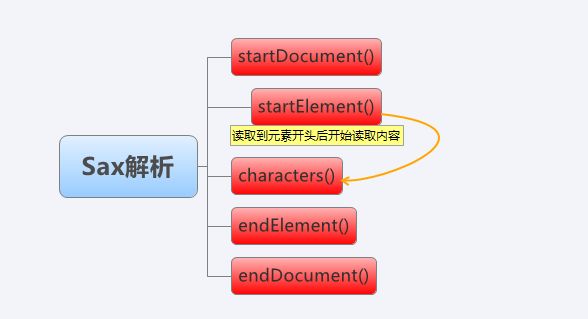
同样,在Sax的解析过程中,读取到文档开头、结尾,元素的开头和结尾都会触发一些回调方法,你可以在这些回调方法中进行相应事件处理
这四个方法是:startDocument() 、 endDocument()、 startElement()、 endElement
此外,光读取到节点处是不够的,我们还需要characters()方法来仔细处理元素内包含的内容
将这些回调方法集合起来,便形成了一个类,这个类也就是我们需要的触发器
一般从Main方法中读取文档,却在触发器中处理文档,这就是所谓的事件驱动解析方法
例子:
参考:http://www.cnblogs.com/nerxious/archive/2013/05/03/3056588.html
Dom解析功能强大,可增删改查,操作时会将xml文档以文档对象的方式读取到内存中,因此 适用于小文档
Sax解析是从头到尾逐行逐个元素读取内容,修改较为不便,但 适用于只读的大文档
本文主要讲解Sax解析,其余放在后面
Sax采用事件驱动的方式解析文档。简单点说,如同在电影院看电影一样,从头到尾看一遍就完了,不能回退(Dom可来来回回读取)
在看电影的过程中,每遇到一个情节,一段泪水,一次擦肩,你都会调动大脑和神经去接收或处理这些信息
同样,在Sax的解析过程中,读取到文档开头、结尾,元素的开头和结尾都会触发一些回调方法,你可以在这些回调方法中进行相应事件处理
这四个方法是:startDocument() 、 endDocument()、 startElement()、 endElement
此外,光读取到节点处是不够的,我们还需要characters()方法来仔细处理元素内包含的内容
将这些回调方法集合起来,便形成了一个类,这个类也就是我们需要的触发器
一般从Main方法中读取文档,却在触发器中处理文档,这就是所谓的事件驱动解析方法
例子:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.junit.Test;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxParseService extends DefaultHandler{
private List<Book> books = null;
private Book book = null;
private String preTag = null;//作用是记录解析时的上一个节点名称
public List<Book> getBooks(InputStream xmlStream) throws Exception{
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
SaxParseService handler = new SaxParseService();
parser.parse(xmlStream, handler);
return handler.getBooks();
}
public List<Book> getBooks(){
return books;
}
@Override
public void startDocument() throws SAXException {
books = new ArrayList<Book>();
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if("book".equals(qName)){
book = new Book();
//得到属性值 book id="15"
book.setId(Integer.parseInt(attributes.getValue(0)));
book.setKey(attributes.getValue(1));
}
preTag = qName;//将正在解析的节点名称赋给preTag
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if("book".equals(qName)){
books.add(book);
book = null;
}
preTag = null;/**当解析结束时置为空。这里很重要,例如,当图中画3的位置结束后,会调用这个方法
,如果这里不把preTag置为null,根据startElement(....)方法,preTag的值还是book,当文档顺序读到图
中标记4的位置时,会执行characters(char[] ch, int start, int length)这个方法,而characters(....)方
法判断preTag!=null,会执行if判断的代码,这样就会把空值赋值给book,这不是我们想要的。*/
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
if(preTag!=null){
String content = new String(ch,start,length);
if("name".equals(preTag)){
book.setName(content);
}else if("price".equals(preTag)){
book.setPrice(Float.parseFloat(content));
}
}
}
@Test
public void test() throws FileNotFoundException
{
SaxParseService sax = new SaxParseService();
InputStream input = new FileInputStream(new File("books.xml"));
List<Book> books = new ArrayList<Book>();
try {
books = sax.getBooks(input);
} catch (Exception e) {
e.printStackTrace();
}
for(Book book : books){
System.out.println(book.toString());
}
}
};
class Book {
private int id;
private String key ;
private String name;
private float price;
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
@Override
public String toString(){
return this.id+" "+this.key+":"+this.name+":"+this.price;
}
}
参考:http://www.cnblogs.com/nerxious/archive/2013/05/03/3056588.html