用Java操作Office 2007
作者 Ted Neward译者 张立 发布于 2007年9月20日 上午12时41分
从以往看来,这其中经常会出现一些问题,这是由于Office文档(主要是Word,Excel和PowerPoint)是存储在一个二进制格式文件中,在COM中被称为结构化存储格式, 是一个通过COM接口的层次化二进制格式。 对COM开发者(或者其他使用COM相关语言的开发者,如Visual Basic, Delphi 和C++/ATL)而言非常方便,但产生的文件对于那些不能“讲COM”的语言是无法访问的。有许许多多的应用程序都是为了让Java语言可以访问这些文件的内容;比如大家都知道Excel可以读取逗号分隔符文件(CSV),因此,Java应用程序相应将数据导出到Excel友好的格式时一般会选用CSV格式(或是其他丑陋的格式)。Word则是可以读取富文本格式(RTF)文件,而RTF标准是公开和有详细文档的。Office的后来者,Office 2003,引入了一个新的XML格式(WordML),Java开发者可以用它来读写Office文档,但是这些格式并没有很好的文档,Java开发者频繁的发现自己是通过试错法来进行WordML格式的学习。 各种各样的开源项目都参与进来想要解决这个问题,比如Apache的POI框架,可以用来读写Excel文档,还有各种各样的Java-COM解决方案,这些解决方案一般倾向于使用和Office自己使用的结构化存储应用程序接口相同的应用程序接口进行Excel文档的读写,但很难满足需要,直到现在,开发者不得不指出Office文档格式的内部结构是一个非常复杂的结构,另外一点毋庸置疑的是它是一个没有完整文档的结构。
总体上来说,如果温和一点说的话,Java/Office的故事是一个非常讨厌的境况。对于Java的开发人员而言,他们要么一边嘴里说着“Office这种破东西怎么还会有人想去用它”一边用记忆里的伊索寓言来安慰自己,要么干脆告诉那些使用Office的客户由于Microsoft和Sun两家公司之间的诉讼,Java不能操作Office。
对于Office 2007来说,微软毫无疑问的迈出了解决这些问题的一大步。没有比原始的JDK更复杂的东西---也就是说并不要求使用一些第三方的库---Java应用程序现在可以读写任何Office 2007的文档,这是由于Office 2007文档现在使用的是XML文档的ZIP格式文件。 这种格式被称作“OpenMXL”规范并且已经被提交到欧洲计算机制造商协会(ECMA),这个协会同样拥有C#语言和CLI运行时规范,所有的OpenXML规范现在都可以被任何人自由的从ECMA的网站下载。 除了这些,再安装好Office 2007(为了验证和作一些测试)和一个标准的Java6 JDK安装,Java现在可以打开任何的Office 2007文档,找出来文档中间的内容,操作它们,并且再次保存这些数据。
与上篇文章不同,在这篇文章中,除了创建一个简单的应用程序之外,代码将会使用一种首先由Stuart Halloway提出的、被称作探索测试(exploration testing)的技术。在一个探索测试中,开发者编写单元测试用来探索应用程序接口,使用单元测试世界中的断言验证结果的正确性。探索测试带来的好处是当一个新版本的应用程序接口可用时---在这个例子中,可能是一个新版本的Office---运行这些测试可以用来确认新版本的采用不会影响到原本对应用程序接口的使用。
对于初学者来说,让我们首先快速的了解一下Office 2007文档。首先看一个仅仅包含文本的Word 2007文档,就像下面一样:
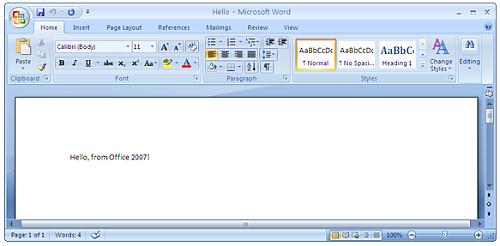
当保存的时候,使用Word 2007将它保存为“Hello.docx”,除非你使用了向后兼容格式,比如说Office 2003的WordML格式,或者是更老的Word 97二进制结构化存储格式。“.docx”文件是OpenXML格式的,微软的文档中声称该格式是XML文档的ZIP压缩格式文件,这些文件中包含了文档中的数据和格式,存储的方式与之前的Office版本中的二进制结构化存储应用程序接口存储数据的方式有些类似。如果这是真的,那么使用Java中提供的用来处理ZIP和TAR格式的“jar”实用工具应该可以展示这些内容,而事实上,它的确可以:

Word 2007文档的基本格式已经非常明显了,仅仅通过控制台的输出就可以看到。(事实上,“jar”实用工具所展示的这激动人心的一切,说明java.util.jar和/或 java.util.zip包同样可以简单的访问这些内容。)几乎没有对规范作任何的破解,很明显,文档中的主要内容应该被存储到了“document.xml”文件中,剩余的其他XML文件则应该是各种各样的辅助部分,比如文档中应用到的字体(fontTable.xml)和使用到的Office主题(theme/theme1.xml),等等。
是时间来编写一些探索测试了。(我们鼓励感兴趣的读者打开一个文本编辑器或者集成开发环境,并将下面的内容填入你的JUnit 4测试类当中,并且扩展这些测试。) 使用JUnit 4,第一个测试是为了简单的确认文件在我们预想的位置(显然这是下面测试可以运行的一个必要的需求)。
@Test public void verifyFileIsThere() {
assertTrue(new File("hello.docx").exists());
assertTrue(new File("hello.docx").canRead());
assertTrue(new File("hello.docx").canWrite());}
下面的测试简单的验证了我们可以使用Java库中的java.util.zip.ZipFile来打开这个文件:
@Test public void openFile() throws IOException, ZipException{
ZipFile docxFile = new ZipFile(new File("hello.docx"));
assertEquals(docxFile.getName(), "hello.docx");}
现在一切看来都非常不错。Java的ZipFile类正确的识别了我们的文件,一个zip文件,如果我们还能继续保持这样的运气,让我们继续我们的测试,来遍历一下,识别文档中的内容并找出其中的数据。让我们编写一个快速的测试来从“document.xml”文件中找出所有的内容。
@Test public void listContents() throws IOException, ZipException{
boolean documentFound = false;
ZipFile docxFile = new ZipFile(new File("hello.docx")); Enumeration entriesIter = docxFile.entries();
while (entriesIter.hasMoreElements())
{
ZipEntry entry = entriesIter.nextElement();
if (entry.getName().equals("document.xml"))
documentFound = true;
}
assertTrue(documentFound);}
令人诧异的是,当我们运行测试的时候,测试过程产生了一个失败;并没有找到“document.xml”文件,这是由于ZipFile/ZipEntry 应用程序接口需要压缩文件中完整的路径名称。将测试中的路径改为“word/document.xml”,测试就通过了。
很好,我们已经找到文件了,下面让我们打开这个文件看看XML里面是什么。这非常简单,因为ZipFile有一个返回ZipEntry的应用程序接口。
@Test public void getDocument() throws IOException, ZipException
{
ZipFile docxFile = new ZipFile(new File("hello.docx"));
ZipEntry documentXML = docxFile.getEntry("word/document.xml");
assertNotNull(documentXML);}
ZipFile代码可以返回它包含的实体内容,通过调用getInputStream()方法即可,不要对InputStream产生任何怀疑。将InputStream发送到一个DOM节点中就可以创建一个关于该文档的DOM。
@Test public void fromDocumentIntoDOM() throws IOException, ZipException, SAXException,
ParserConfigurationException
{
ZipFile docxFile = new ZipFile(new File("hello.docx"));
ZipEntry documentXML = docxFile.getEntry("word/document.xml");
InputStream documentXMLIS = docxFile.getInputStream(documentXML);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
Document doc = dbf.newDocumentBuilder().parse(documentXMLIS);
assertEquals("[w:document: null]", doc.getDocumentElement().toString());
}
事实上,与其他支持各种Word所需格式的XML文档相比,document.xml文件的内容(为了明显起见,将命名空间声明等内容去除)看起来也相当乏味:
<w:document ...> <w:body> <w:p w:rsidR="00DE36E5" w:rsidRDefault="00DE36E5"> <w:r> <w:t>Hello, from Office 2007!</w:t> </w:r> </w:p> <w:sectPr w:rsidR="00DE36E5"> <w:pgSz w:w="12240" w:h="15840"/> <w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="720" w:gutter="0"/> <w:cols w:space="720"/> <w:docGrid w:linePitch="360"/> </w:sectPr> </w:body> </w:document>
关于文档中各个元素具体代表什么内容的细节已经超出了这篇文章的讨论范围,读者可以查阅OpenXML文档的具体内容来获得参考,但是文档中的主要内容是十分明显的。比如说文档中包括“p”元素(段落),包括“r”元素(文本区),包括“t”元素(文本),在本例的hello.docx文档中,单句“Hello from Office 2007”就是由这些元素构成的。
读过文件的内容后,现在可以来修改这些内容了,将其写到文件中,并用Word 2007打开它。快速的查看ZipFile和ZipEntry的应用程序接口可以发现这样一个问题:尽管这些类可以用来读取一个zip文件,但它们并不能写入或创建它们。
有很多可用的方法可以用于解决这个问题。一个简单的方法是将XML文件的内容文本写到一个字符串中,并将这个字符串存储到document.xml文件中,然后重新使用ZipOutStream类压缩所有的内容。另一个方法是使用一些可以编辑zip文件内容的第三方工具(或创建一个),但这些已经脱离了JDK的基本内容,所以在这篇文章中我们将使用ZipOutStream方法。
为了达到我们的目的,我们需要做很多事情。首先,Java应用程序必须定位到DOM的层次结构中,找到“t”节点,然后将它的文本内容替换为我们要写入到Word文档中的内容。(“Hello,Office 2007,from Java6!”是个不错的选择)产生的新DOM实例必须要保存到磁盘中,使用Java XML 应用程序接口时这并不是一个简单的任务。(简单的说来,开发者需要从javax.xml.transform包中创建一个Transformer,然后将XML转换为一个StreamResult,再交由ByteArrayOutputStream处理。)
一旦上面这些事情都处理完毕后,代码必须要产生一个ZIP格式的文件,是时候使用ZipOutputStream了,但由于只需要改变文档的内容,而不需要改变它的样式、字体以及格式,其他的部分可以从原始的文件中拷贝过来。使用一个简单的循环,遍历原始文件中的ZipEntries中所有的内容(除了word/document.xml,该文件中的内容需要被改变)并将其导出到一个新的ZipEntry中并写入该实体就足够了。当所有的工作都完成后,代码将会是以下的样子:
@Test public void modifyDocumentAndSave()
throws IOException, ZipException, SAXException, ParserConfigurationException, TransformerException, TransformerConfigurationException
{
ZipFile docxFile = new ZipFile(new File("hello.docx"));
ZipEntry documentXML = docxFile.getEntry("word/document.xml");
InputStream documentXMLIS = docxFile.getInputStream(documentXML);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
Document doc = dbf.newDocumentBuilder().parse(documentXMLIS);
Element docElement = doc.getDocumentElement();
assertEquals("w:document", docElement.getTagName()); Element bodyElement = (Element) docElement.getElementsByTagName("w:body").item(0); assertEquals("w:body", bodyElement.getTagName());
Element pElement = (Element) bodyElement.getElementsByTagName("w:p").item(0); assertEquals("w:p", pElement.getTagName());
Element rElement = (Element) pElement.getElementsByTagName("w:r").item(0);
assertEquals("w:r", rElement.getTagName());
Element tElement = (Element) rElement.getElementsByTagName("w:t").item(0);
assertEquals("w:t", tElement.getTagName());
assertEquals("Hello, from Office 2007!", tElement.getTextContent());
tElement.setTextContent( "Hello, Office 2007, from Java6!"); Transformer t = TransformerFactory.newInstance().newTransformer();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
t.transform(new DOMSource(doc), new StreamResult(baos)); ZipOutputStream docxOutFile = new ZipOutputStream( new FileOutputStream("response.docx"));
Enumeration entriesIter = docxFile.entries();
while (entriesIter.hasMoreElements())
{
ZipEntry entry = entriesIter.nextElement();
if (entry.getName().equals("word/document.xml"))
{
byte[] data = baos.toByteArray();
docxOutFile.putNextEntry( new ZipEntry(entry.getName()));
docxOutFile.write(data, 0, data.length); docxOutFile.closeEntry();
} else
{
InputStream incoming = docxFile.getInputStream(entry); byte[] data = new byte[1024 * 16];
int readCount = incoming.read(data, 0, data.length); docxOutFile.putNextEntry(
new ZipEntry(entry.getName()));
docxOutFile.write(data, 0, readCount); docxOutFile.closeEntry();
}
}
docxOutFile.close();
}
很抱歉这里展示了这么多代码,但是说实在的,这也是Java相比其他语言或者库的一个弱点。幸运的是我们的努力得到了以下的回报:
显然我们可以作很多事情来改善上面的场景。
首先,一个更好的XML操作库,可以更好的支持XPath技术,能够原生的序列化XML DOM结构到磁盘的库会对减少大量的代码有所帮助。JDOM,一个开源的Java/XML库(可以在jdom.org中找到),是一个可用的选择。Apache的XMLBeans也不错。一个必然的结果是我们可以获得更好的描述OpenXML格式的模式文档,并使用它们来产生一系列的Java类来更好的反映OpenXML文档的格式。开发者则可以更好的使用原生的Java类工作,而不是通过“Document”类和“Element”类。
其次,这些方法可以被绑定到一个更加针对Office的应用程序接口当中,可以改善针对实际存储的Word(或是Excel,PowerPoint)文档的XML文件操作的抽象层,关注那些拥有段落,字体等等其他的文档。实质上,像POI那样的库应该可以通过更新类反映Office XML格式的改动,理想的话,可以同时支持写入二进制结构化存储格式和新的OpenXML格式。
再次,Java可以对其ZIP文件格式的支持进行一些改动,同样,这样的目的也可以由使用一些第三方的库来完成。
尽管使用了一些笨重的应用程序接口调用,但是当想到Office平台对Java开发人员有多开放时还是非常的令人激动和振奋。在Java和Office应用程序的互操作性上,在Java应用程序中使用Office,还有在Java中创建和读写Office文件格式上,Office平台对Java社区的开发人员比以往任何时候都更加开放了。
本文附带的示例代码可以在