图像识别软件Tesseract-OCR3.0.1在MAC上的安装
春运抢火车票是一场战斗
程序员在这场战斗里的唯一优势是整个程序代替人肉订票过程。
感谢太极公司,虽然他们显然没预估到全国人民抢票的热情,好歹没为我们模拟抢票设置任何障碍。
恩,除了验证码意外的。。。
网上搜索了一圈,图像识别领域有个著名的开源软件Tesseract-OCR3.0.1,在他的官方网站浏览了下,结构还是不错的,支持多种语言包,也包括中文。
项目地址:http://code.google.com/p/tesseract-ocr/
评估开源项目的首要是看是否能帮助我们解决问题,找了个基于Tesseract-OCR3.0.1的在线工具,看效果
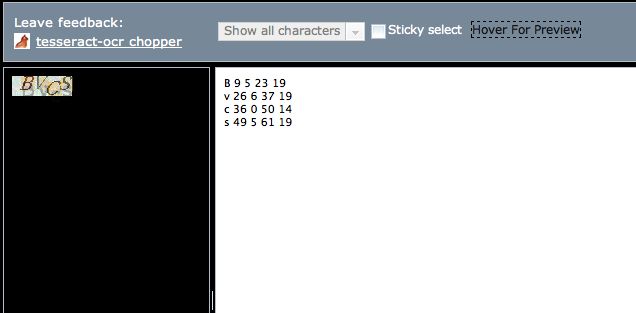
效果还不错哈,准确的识别了验证码,就是他了。
MAC上装东西总是遇到些问题,这里做个流水帐。希望能对别人有点帮助哈
1、先下载需要的软件包
OCR工具: Tesseract-OCR3.0.1 source code tesseract-ocr-3.01.eng.tar.gz 破验证码用英文就够了。
图像处理工具: Leptonica 1.68
png识别工具: libpng
jpeg识别工具 :libjpeg
tif识别工具: libtiff
图像压缩算法包:zlib1g(mac os 已经集成了这个包,不需要安装了)
2、安装步骤
1- 安装libpng,libjpeg,libtiff
./configure make sudo make install
2- 安装Leptionica
./configure make sudo make install
make的时候发现错误,提示
pngio.c:119: error: ‘Z_DEFAULT_COMPRESSION’ undeclared here (not in a function)
去wiki上搜了一把发现是 pngio.c这个文件有个BUG,在MAC下无法找到zlib1g包修改Leptionica/src/pngio.c在 #include "png.h"后插入一下代码即可。
#ifdef HAVE_LIBZ #include "zlib.h" #endif
3- 安装Tesseract-OCR
./autogen.sh ./configure make sudo make install
4- 安装语言包
解压tesseract-ocr-3.01.eng.tar.gz到/usr/local/share/tesseract就可以了。
3、try ocr
MacBook-Pro:work my$ tesseract pin.jpg out -l eng Tesseract Open Source OCR Engine v3.01 with Leptonica MacBook-Pro:work my$ more out.txt Bvcs
至此,已经tesseract已经可以正常工作了。
剩下我们写段代码去通过命令行调用就可以实现图片的识别了。
tesseract自己提供的训练好的语言包不能保证百分百识别出验证码图片,这个可以通过抓取一定量的验证码来进行
训练,以更加精准的识别,官方有文档和工具如何进行
http://code.google.com/p/tesseract-ocr/wiki/TrainingTesseract3
后面我也会整理一个博文加以说明哈!