ActiveMQ高可靠性解决方案 ,ActiveMQ官方推荐“Shared storage”模式作为首选方案,并提供了多个优秀的存储策略,其中kahadb、levedbDB、JDBC Store等都可以便捷的接入。
activemq 的高可用解决方案, 它是通过Master/Slave(主从备份)和failover协议来支持的。
Master/Slave 有三种解决方案:
Share Nothing Master/Slave
Master 收到消息后保证先转发给slave后再发给客户端,slave有自己独立存储, 在slave
配置文件中需指定Master URI, 这样当Master 宕掉后,客户端会Failover到Slave. 纯Master/Slave只允许一个Slave连接到Master上面,也就是说只能有2台MQ做集群,同时当Master挂了之后需要停止Slave来恢复负载。
2. Share File System Master/Slave
没有物理上的Master, Slave之分, 只有逻辑上的Master 和 Slave, Master与Slave 共
享一个存储文件, 谁最先启动就会持有共享文件锁,成为Master, 后启动的由于获取文件锁时会被阻塞,成为Slave,当Master宕掉时,共享文件锁被释放掉,Slave获取的文件锁后就成为Master, 客户端使用failover 协议后会failover到可用的broker上。
方案2的有点是不需要修改配置文件,易管理, 缺点是需要搭建个分布式共享文件系统, 对于我们在线升级稍显麻烦。方案2在我测试时也发现了些问题,当Master宕掉后,Slave不能立即升级为Master, 导致客户端failover失败。(这个我有点怀疑是我nfs 没搞好,这个我有时间再研究下)
方案1的缺点是需要额外的配置Slave配置文件及对应的存储空间,只能有一个slave因此
只能failover一次, 由于存在主从复制,会带来稍许的性能开销。但对于我们在线升级来说就比较简单,把Master数据存储文件拷贝到Slave下然后启动slave就行。
在我本机环境和66.21服务器上都搭建有方案1 Master/Slave, 经过多次模拟客户端发消息和收消息测试,表现良好,都能成功failover, 没发现漏消息和重复发消息。
以后对ActiveMQ扩展的一些想法
ActiveMQ本身是支持集群的,包括Broker集群和Consumer集群 但它的集群只能实现
负载均衡,不能实现高可靠性, 要实现高可靠性集群必需在集群内的每个节点实行Master / Slave.
目前我们的应用只起了一个ActiveMQ实列,即只有一个broker, 随着业务发展,以后可能一个broker会压力太大而需要进行扩展。 扩展的方向首先应该是进行垂直拆分,即把目前很多queue 和 topic拆分不同的Broker去。这些broker之间是独立的,每个broker都做成Master / Slave. 只有当单个queue或topic 一个broker还顶不住时,这时就需要做ActiveMQ的负载均衡集群了。 不过根据相关测试在局域网中4k的消息可达到4000条/s 的吞吐量,这个对于我们的应用来说够大了
HA(高可用性)几乎在所有的架构中都需要有一定的保证,在生产环境中,我们也需要面对broker失效、网络故障等各种问题,ActiveMQ也不例外。activeMQ作为消费分发和存储系统,它的HA模型只有master-slave,我们通过broker节点“消息互备”来达成设计要求。
Client端与master交互并生产和消息消息,并且有一个或者多个slave与其保持同步,如果master失效,我们希望slave能够自动角色转换并接管服务,并且故障转移的过程不能影响Client对消息服务的使用(failover)。ActiveMQ Broker不仅仅负责消息的分发,还需要存储消息,根据存储机制的不同,master-slave模式分为两种:“Shared nothing”和“Shared storage”。其中“Shared nothing”表明每个broker有各自的存储机制,各个broker之间无任何数据共享,这是最简单的部署方案,当然也是数据可靠性最低的,如果一个broker存储设备故障将会导致此broker中的数据需要重建,master与slave之间的状态感知,是通过TCP通信来实现。“Shared storage”是推荐的架构方案,master与slave之间共享远端存储系统(比如JDBC Storage,SAN分布式文件系统等),master与slave通过获取Storage的排他锁状态来感知状态,获取锁的broker作为master并负责与Client数据交互,当锁失效后slave之间通过锁竞争来产生新的master,在最新的架构中,zookeeper也可以很方便的集成到ActiveMQ中。
master-slave并不是大规模消息系统的扩展方案,它只是解决broker节点的HA问题,稍后我们会介绍“Forward Brige”模式在activeMQ分布式系统中的应用。
一. Share nothing storage master/slave
最简单最典型的master-slave模式,master与slave有各自的存储系统,不共享任何数据。master接收到的所有指令(消息生产,消费,确认,事务,订阅等)都会同步发送给slave。在slave启动之前,首先启动master,在master有效时,salve将不会创建任何transportConnector,即Client不能与slave建立链接;如果master失效,slave是否接管服务是可选择的(参见下文配置)。在master与slave之间将会建立TCP链接用来数据同步,如果链接失效,那么master认为slave离线。
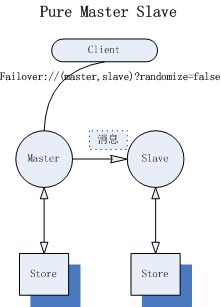
对于持久化消息,将会采用同步的方式(sync)在master与slave之间备份,master接受到消息之后,首先发给slave,slave存储成功后,master才会存储消息并向producer发送ACK。
当master失效后,slave有两种选择:
1) 关闭:如果slave检测到master失效,slave实例关闭自己。此后管理员需要手动依次启动master、slave来恢复服务。
2) 角色转换: slave将自己提升为master,并初始化transportConnector,此后Client可以通过failover协议切换到Slave上,并与slave交互。
- //Client使用failover协议来与有效的master交互
- //master地址在前,slave在后,randomize为false让Client优先与master通信
- //如果master失效,failover协议将会尝试与slave建立链接,并依此重试
- failover://(tcp://master:61616,tcp://slave:61616)?randomize=false
“Shared nothing”模式下,有很多局限性。master只能有一个slave,而且slave不能继续挂载slave。如果slave较晚的接入master,那么master上已有的消息不会同步给slave,只会同步那些slave接入之后的新消息,那也意味着slave并没有完全持有全局的所有消息;所以如果此时master失效,slave接入之前的消息有丢失的风险。如果一个新的slave接入master,或者一个失效时间较长的旧master接入新master,通常会首先关闭master,然后把master上所有的数据Copy给slave(或旧master),然后依次启动它们。事实上,ActiveMQ没有提供任何有效的手段,能够让master与slave在故障恢复期间,自动进行数据同步。
Master配置:
- <broker brokerName="master" waitForSlave="true" shutdownOnSlaveFailure="false" waitForSlaveTimeout="600000" useJmx="false" >
- ...
- <transportConnectors>
- <transportConnector uri="tcp://localhost:61616"/>
- </transportConnectors>
- </broker>
其中shutdownOnSlaveFailure默认为false,即当slave失效时,master将继续服务,否则master也将关闭。waitForSlave表示当master启动之后,是否等待slave接入,如果为true,那么master将会等待waitForSlaveTimeout毫秒数,直到有slave接入之后master才会初始化transportConnector,此间Client无法与master交互;如果等待超时,则有shutdownOnSlaveFailure决定master是否关闭。
Slave配置:
- <broker brokerName="slave" ="true" shutdownOnMasterFailure="false">
- <services>
- <masterConnector remoteURI= "tcp://master:61616"/>
- </services>
- ....
- <transportConnectors>
- <transportConnector uri="tcp://localhost:61616"/>
- </transportConnectors>
- </broker>
shutdownOnMasterFailure表示当master失效后,slave是否自动关闭,默认为false,表示slave将提升为master。
不过我们需要注意,master与slave之间通过Tcp链接感知对方的状态,基于链接感知状态的“三节点网络”(Client,Master,slave),结果总是不可靠的;如果master与slave实例都有效,只是master与slave之间的网络“阻断”,此时slave也会认为master失效,如果slave提升为master,对于Client而言将会出现2个master的“幻觉”。更坏的情况是,部分Client与旧master之间也处于网络阻断情况,那么就会出现部分Client链接在新master上,其他的Client链接在旧master上,数据的一致性将处于失控状态。(split-brain)
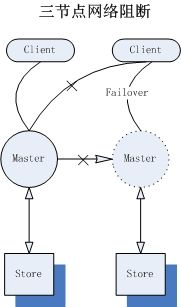
因为这种模式下各种局限性,“Shared nothing”模式已经被active所抛弃,将在5.8+之后版本中移除。不过对于小型应用而言,这种模式带来的便捷性也是显而易见的。
二. Shared storage master/slave
在上文中,我们已经了解了“Shared nothing”模式下的局限性,在企业级架构中它将不能作为一种可靠的方案而实施。ActiveMQ官方推荐“Shared storage”模式作为首选方案,并提供了多个优秀的存储策略,其中kahadb、levedbDB、JDBC Store等都可以便捷的接入。
“Shared storage”允许集群中有多个slave共存,因为存储数据在salve与master之间共享(物理共享),所以当master失效后,slave自动接管服务,而无需手动进行数据的Copy与同步,也无需master与slave之间进行任何额外的数据交互,因为master存储数据之后,它们在任何时候对slave都是可见的。master与slave之间,通过共享文件的“排他锁”或者分布式排他锁(zookeeper)来决定broker的状态与角色,获取锁权限的broker作为master,如果master失效,它必将失去锁权限,那么slaves将通过锁竞争来选举新master,没有获取锁权限的broker作为slave,并等待锁的释放(间歇性尝试获取锁)。当然slaves仍然不能为Client服务, 它只为故障转移做准备。
在此需要明确一个问题,“Shared storage”模式只会共享“持久化”类型的消息;对于非持久化消息将不能从从中收益,它们不会在slaves中备份,这也意味着如果master失效,即使slave接管了服务,此前保存在master上的非持久化消息也将丢失。通常,我们在“Shared storage”模式中,额外的配置一个插件,强制将所有消息转换成持久化类型,这样所有的消息都可以在故障恢复之后不会丢失。
- <broker>
- <plugins>
- <!-- 将所有消息的传输模式,修改为"PERSISTENT" -->
- <forcePersistencyModeBrokerPlugin persistenceFlag="true"/>
- </plugins>
- </broker>

1. Shared File System master/slaves
基于共享文件系统的master/slaves模式,此处所谓的“共享文件系统”目前只能是基于POSIX接口可以访问的文件系统,比如本地文件系统或者SAN分布式共享文件系统(比如:glusterFS);对于broker而言,启动时将会首先获取存储引擎的文件锁,如果获取成功才能继续初始化transportConnector,否则它将一直尝试获取锁(tryLock),那么对于共享文件系统而言,需要严格确保任何时候只能有一个进程获取排他锁,如果你选择的SAN文件系统不能保证此条件,那么将不能作为master/slavers的共享存储引擎。
“Shared File System”这种方式是最常用的模式,架构简单,可靠实用。我们只需要一个SAN文件系统即可。
在这种模式下,master与slave的配置几乎可以完全一样。如下示例中,我们使用一个master和一个slave,它们部署在一个物理机器上,使用本地文件系统作为“共享文件系统”。
Master/Slave配置:
- <broker xmlns="http://activemq.apache.org/schema/core" brokerName="broker-locahost-0" useJmx="false">
- <persistenceAdapter>
- <levelDB directory="/data/leveldb"/>
- </persistenceAdapter>
- <tempDataStore>
- <levelDB directory="/data/leveldb/tmp"/>
- </tempDataStore>
- <!--
- <persistenceAdapter>
- <kahaDB directory="/data/kahadb"/>
- </persistenceAdapter>
- <tempDataStore>
- <pListStoreImpl directory="/data/kahadb/tmp"/>
- </tempDataStore>
- -->
- <transportConnectors>
- <!-- slave -->
- <!--
- <transportConnector name="openwire" uri="tcp://0.0.0.0:51616?maximumConnections=1000&wireformat.maxFrameSize=104857600"/>
- -->
- <transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireformat.maxFrameSize=104857600"/>
- </transportConnectors>
- </broker>
对于Client端而言,可以使用failover协议来访问broker:
- failover://(tcp://localhost:61616,tcp://localhost:51616)?randomize=false
2. JDBC Store master/slaves
显而易见,数据存储引擎为database,activeMQ通过JDBC的方式与database交互,排他锁使用database的表级排他锁,其他原理基本上和1)一致。JDBC Store相对于日志文件而言,通常认为是低效的,尽管数据的可见性较好,但是database的扩容能力非常的弱,无法良好的适应在高并发、大数据情况下,况且ActiveMQ的消息通常存储时间较短,频繁的写入,频繁的删除,都是性能的影响点。我们通常在研究activeMQ的存储原理时使用JDBC Store,或者在中小型应用中对数据一致性(可靠性,可见性)要求较高的环境中使用:比如订单系统中交易流程支撑系统等。
在使用JDBC Store之前,必须有一个稳定的database,且指定授权给acitvemq中的链接用户具有“创建表”和普通CRUD的权限。master与slave中的配置文件基本一样,开发者需要注意brokerName和brokerId全局不可重复。此外还需要把相应的jdbc-connector的jar包copy到${acitvemq}/lib/optional目录下。
Master/Slave配置:
- <broker brokerId="localhost-0" brokerName="broker-locahost-0" useJmx="false" dataDirectory="${activemq.data}">
- <persistenceAdapter>
- <jdbcPersistenceAdapter dataSource="#mysql-ds"/>
- </persistenceAdapter>
- <transportConnectors>
- <!-- DOS protection, limit concurrent connections to 1000 and frame size to 100MB -->
- <transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireformat.maxFrameSize=104857600"/>
- </transportConnectors>
- </broker>
- <bean id="mysql-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
- <property name="driverClassName" value="com.mysql.jdbc.Driver"/>
- <property name="url" value="jdbc:mysql://localhost:3306/activemq?relaxAutoCommit=true"/>
- <property name="username" value="root"/>
- <property name="password" value="root"/>
- <property name="poolPreparedStatements" value="true"/>
- </bean>
JDBC Store有个小小的问题,就是临时文件无法保存在database中,我们不能在<tmpDataStore>使用JDBC Store;所以临时文件还是只能保存在broker本地。
三. Replicated LevelDB Store
基于复制的LevelDB Store,这是ActiveMQ全力打造的HA存储引擎,也是目前比较符合“Master-slave”架构模型的存储方案,此特性在5.9+版本中支持。我们从1)/2)两个方案中可见,“Shared Storage”模式只是利用了“一些小伎俩”,并不符合广泛意义上的“master-slave”模型(在存储上,和通讯机制上)。不过,“Replicated LevelDB Store”做到了!!
“Replicated LevelDB”也同样允许有多个Slaves,而且Slaves的个数有了约束性的限制,这归结于其使用zookeeper作为Broker master选举。每个Broker实例将消息数据保存本地(类似于“Shared nothing”),它们之间并不共享任何数据,所以把“Replicated LevelDB”归类为“Shared storage”并不妥当。
当Broker启动时,它首先向zookeeper注册自己的信息(brokerName,消息日志的版本戳等),如果此时group中没有其他broker实例,并阻塞初始化过程,等到足够多的broker加入group;当brokers的数量达到“replicas的多数派"时,开始选举,选举将会根据“消息日志的版本戳”、“权重"的大小决定,即“版本戳”越大(数据最新)、权重越高的broker优先成为master,其他broker作为slave并跟随master。当一个broker成为master时,它会向zookeer注册自己的sync地址信息;此后slaves首先根据sync地址与master建立链接,并同步消息文件(download)。当足够多的slave数据同步结束后,master将初始化transportConnector,此后Client将可以与master进行数据交互。
- <broker xmlns="http://activemq.apache.org/schema/core" brokerName="mq-group" brokerId="mq-group-0" dataDirectory="${activemq.data}">
- <persistenceAdapter>
- <replicatedLevelDB directory="${activemq.data}"
- replicas="2"
- bind="tcp://127.0.0.1:0"
- zkAddress="127.0.0.1:2181"
- zkSessionTmeout="30s"
- zkPath="/activemq/leveldb-stores"
- hostname="broker0" />
- </persistenceAdapter>
- </broker>
Master-slaves集群中,所有的broker必须具有相同的brokerName,它作为group域来限定集群的成员,brokerId可以不同,它仅作为描述信息。“replicas”参数非常重要,默认为3,表示消息最多可以备份在几个broker实例上,同是只有当“replicas/2 + 1”个broker存活时(包含master),集群才有效,才会选举master和备份消息,此值必须>=2。Client发送给Master的持久化消息(包括ACK和事务),master首先在本地保存,然后立即同步(sync)给选定的(replicas/2)个slaves,只有当这些节点也同步成功后,此消息的交互才算结束;对于剩下的replicas个节点,master采用异步的方式(async)转发。这种设计要求,可以保证集群中消息的可靠性,只有当(replicas/2 + 1)个节点物理故障,才会有丢失消息的风险。通常replicas为3,这要求开发者需要至少部署3个broker实例。如果replicas过大,会严重影响master的吞吐能力,因为它在sync消息的过程中会消耗太多的时间。

如果集群故障,在重启broker实例时,建议首先查看每个broker中查看LevelDB日志文件的版本戳(文件名为16进制数字),并优先启动版本戳较大的实例。(因为replicas多数派的约束,随机重启也不会有太大的问题)。但是不得随意调小replicas的值,如果你确实需要修改,那就首先关闭集群,一定优先启动版本戳最大的broker。
尽管集群对zookeeper的操作并不是很多,但是我们还是希望不要接入负载过高的zookeeper集群,以免给消息服务引入不稳定因素。通常zookeeper集群至少需要3个实例,才能保证zookeeper本身的高可用性。
其中bind属性表示当此broker实例成为master时,开启一个socket地址,此后slave可以通过此地址与其同步数据。
我们还需要为Replicated LevelDB配置zookeeper的地址和path,其中path下用来存储group中所有broker的注册信息,此值在group中所有的broker上都要一样。“hostname”用来描述当前机器的核心信息,通常为机器IP。如果你在本机构建伪分布式,那么需要在系统hosts文件中使用转义。
- 127.0.0.1 broker0
- 127.0.0.1 broker1
- 127.0.0.1 broker2
对于Client端而言,仍然需要使用failover协议,而且协议中需要包含group中所有broker的链接地址。
- failover://(tcp://localhost:61616,tcp://localhost:51616,tcp://localhost:41616)?randomize=false
和其他模式一样,对于非持久化消息仍然只会保存在master上,当master失效后,消息将会丢失。