简单说搜索个过程,Lucene 在搜索的程序简单分成两部分,搜索与排序。高手请忽略下面我的讲解。
搜索:
通过倒排的索引找到对应的 docId 集,拿出来,通过 Collector 类的实现类中的 collect(int docId )
就可以拿到了。
排序:
因为拿出来后,还有一个排序的过程,现在我们只讨论按某一个数字字段进行排序,Collector 的实现类都会从一个叫 FieldCache 类中,加载了需要排序的字段的一个 数组的值,数组下标为docId, 然后通过 FieldValueHitQueue 这一个类进行排序了。
象一般来讲,做搜索应用都会按时间从远到近,一段一段地把数据存入到索引中,完成后,如有新增的数据,只需要把新增那部分存入索引则可,这是很普遍的做法。
完成后似乎一切很顺利,哦,对了,还有一个事情就是其实很多的业务应用中,都是把搜索结果按一个或者多个字段排序了,比如:把搜索出来的结果,按发布时间倒排,或者按评论数倒排,又或者一个比较常用的业务就是,出报表,把最新的前 1000 条记录按发布时间倒排出来,甚至还要按页数一页一页出来结果。这里暂不讨论按匹配度等排序的情况。
问题的来源:
因为我们入索引是从远到近的,可以简单地认为,如:发布时间(time)在索引里面都是一种升序的形式存入索引,而搜索出来后排序则是一种倒序的形式,问题就是这样子,按排序算法来说这就是最差的一种情况了,把一个升序排序成倒序,但通过研究Lucene 的索引发现,一旦达到某个数据量,索引里面的并非完全按 时间正序入索引的,而是把document 分成了几段,我想这样子就是为了避免我刚才说的排序最坏的情况出现吧...但只能是治标不治本的做法,仅是折衷的做法。
解决思路:
现在公司的搜索业务方面的速度不快,估计数据量比较大的原因,整一个集群的速度我个人并不满意。
在 lucene 的排序中,其实仅仅搜索的速度是挺快的,主要的性能瓶颈在排序那里,然后我深入再发现了解到,公司的搜索业务中很多都使用发布时间倒序完成的,这自然让我产生一种想法,为什么不预先让他们排序好?因为既然是按发布时间倒序完成的,那说明只要命中docId ,则它的排序已经固定下来了。
1. 在加载索引的时候,通过 termEum 先把某一个时间段排序后,得到一个已经排序好的数组了。
2. 自己另外再写一个 Collector 的实现类,里面只需要记录命中的 docId,
3. 完成后,再遍历那个已经排序好的数组,拿出 docId ,看是不是已经命中的,拿够了前 20 条再 break 出来就完成整一个搜索与排序的过程了,
从上面看到,都已经没有排序的过程,因为已经第一步实现了排序。代码我不再演示了,思路已经写在那里了,代码估计对于各路大神也不是什么难事。![]()
下面给出测试的条件与结果:
索引的结构给一下,只需要留意红框里面的字段就可以了
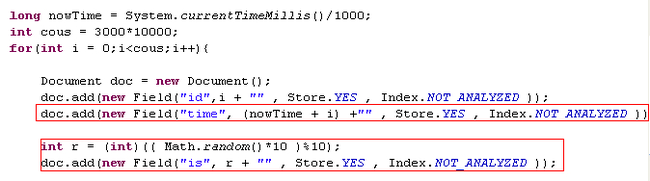
我分了三次测试条件, 1000万,3000万, 总数,其中 is 字段是为了可以均匀地把数据划分成 10 份。都没有使用分词器,只对数字进行索引。
第一次测试
1000W 数据,按 is 字段,搜索 10 平均得出每一次搜索结果约 300W.按 time 字段倒序,同样条件,对比预排序与lucene 自身排序的速度比较
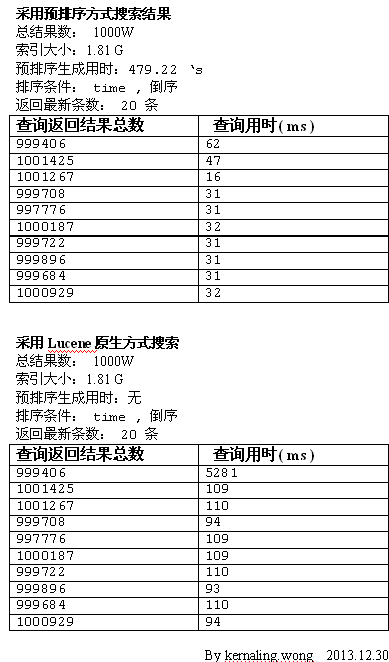
从结果可以看出,使用预排序的方式后只需要用Lucene 自带排序的 30% 的时间 , 平均每一次搜索结果约 100W 数据,(上面的预排序那里是 44.922 's 我是整理时错误了, sorry .... )
第二次测试
3000W 数据,按 is 字段,搜索 10 平均得出每一次搜索结果约 300W.按 time 字段倒序,同样条件,对比预排序与lucene 自身排序的速度比较
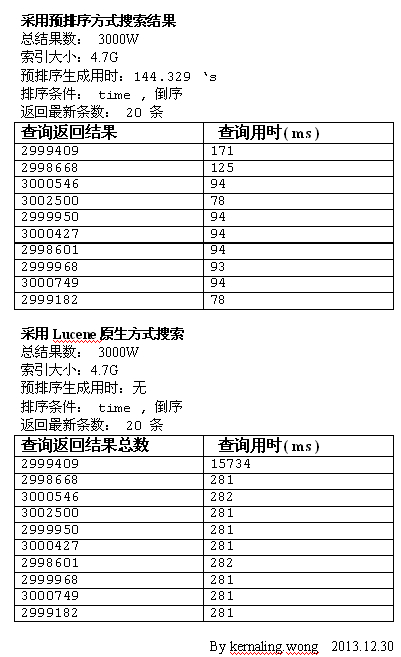
从图上可以看出,同样道理搜索出来的结果,平均每次300W,而且搜索结果数完全一致,排除加载缓存及其他因素,预排序也只需要Lucene 普通排序的 30% 的时间就完成了
第三次测试
这次比较极端,使用MatchAllQuery 进行排序,就是 1000W 结果参与排序,对于Lucene自带的那种排序方式最致命,而对于预先排序这种方式则是最优的方式。

从上面看到, 1000W 的数据参与排序,Lucene自带的排序方式,用了近 1秒的时间去完成排序,而预排序则只用了 0.3 秒就完成了。
总结论:
通过上面的测试,使用预排序的方式,速度提升很明显,为Lucene自带排序的 30 % 时间,对整体的搜索业务性能是一个很大的提升。同时在这里可以扩展一下,通过这样子的预先排序,还可以扩展为,对数字的搜索,或数字区间搜索,而不是使用 NumericQuery ,速度会更快平均在 30ms 的搜索用时,再再再扩展一下,还可以对数字或者数字区间进行统计,比 Solr 的自带的统计速度还要快不少!我稍候还会针对这些做一些扩展开发,请大家稍等。
缺点: 我觉得,可能是每一次加载索引,或者切换新索引的时间,需要用1分钟左右,进行一个预排序的过程,但我认为相对于优点,这一个缺点不大,一般都是通过加载完新的索引并构造好预排序后,再切换到新索引,问题不大。
如果对于那些更新并不频繁而数据量特别大如: 半小时更新一次等,我觉得很适合使用这种方法提升性能,而对于那些几分钟就更新一次的搜索业务,我觉得,这种方式就慎用了,毕竟每次这样子预排序一次,对性能伤害很大。
欢迎转载: http://kernaling-wong.iteye.com/blog/1997365 请注明作者