?what
in a SQL DB Server,in tradictionally,contains Triggers or Procedures,and the privior is used to handle server's internal transactions,most of 'post-do' operations;the laster also is subroutine to processs 'client-server' interactive ops.
?why
just same like with it,HBase has it's internal computation framework named Coprocessor(CP) to play thes e funcs.similar to Scan,this CP is placed in server end,but diffenerce by Reduce the huge data returned to client.
within CP,users can interact with hbase more neatly.
?how
| type | triggered by | customed | executed at | appliations |
| Filter | client | client | server | scan,simple count by client |
| Observer | master/region/wal | server | server | secondary index,access control, complex filter |
| Endpoint | client | client | server | aggregate functions,sum,max... |
common coprocessor flow:
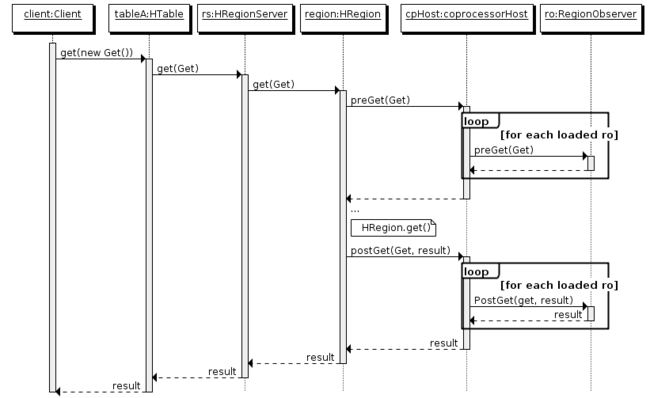
EndPoint coprocessor flow:

可以看到,client是以region 为单位访问的,这意味着一个rs上太多regions的话,在全表统计时将产生很多连接请求.其实类似我们在solr实现一样,可以merge-in-rs即可 TODO
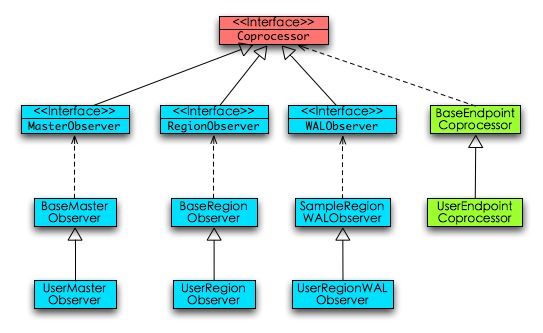
?features
1 advantages
-reduce much data to client to computation
-converient intersactions to hbase
2 disvantages
-just slimilar to common SQL DB,if this CPs are CPU ,MEM or IO intensive,this will slow down the entire cluster performance.so i think if you are run in thise case,let the cluster to in a off-line state is much better.
-CP is different from Bigtable's one,the former is a plugin in hbase,and the later is a individual process out of server,so this may impact server to run normally.
另外在看HRegion#exec()时发现
CoprocessorProtocol handler = protocolHandlers.getInstance(protocol);
这意味着一个protocol只有一个implement,通常这没什么问题,但是需要知道的