五分钟Unicode简单入门
对于Unicode,相信每个javaer都不会陌生。不过对于各种各样的UTF8,UTF16,GBK,GB2312等各种名词,你可能会觉得糊里糊涂,希望读完这篇文章对你有所帮助。
首先我们要清楚一点,Unicode包含Unicode编码和Unicode实现(或者叫传输方式),两者是不同的,而通常我们就最容易搞混这两件事。
Unicode编码的英文缩写是UCS;而Unicode传输方式缩写是UTF。从字面上是不是看出一点点东西?
先来说说UCS。
目前,UCS标准有两种:UCS-2和UCS-4。顾名思义,UCS-2就是用两个字节编码,基本上现在用的就是这个标准,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)编码,是为了防止将来2个字节不够用才开发的。UCS-2有2^16=65536个码位,UCS-4有2^31=2147483648个码位。
UCS实际是一种全世界字符编码的“超集”,目标是让全世界所有字符都可以在这套编码里面找到唯一的编码。全世界所有的文字都可以在这些码位上编码,而互不冲突。你可以理解为Unicode组织为各个地区分一些码位范围。按照UCS-2标准,全世界可表示的编码只有65536个码位。可能你会说不够啊,汉字都差不多这个数了。这个我就不清楚了,大概收录的都是常用汉字吧。
再次强调,不管哪一国的字符码均以2个(UCS4是4个)字节表示,在UCS里面的编码都是唯一的,全世界的UCS编码只有一套(当然只有一套,不然怎么叫标准)。
说完UCS,就来说说UTF。为什么有UTF呢?保存UCS不就直接把每个字节都保存下来就OK拉,那需要管那么多。其实我们从“传输方式”字面上就可以看出来,UTF实际上用于传输、保存。
我们可以这样理解,Unicode在内存里,为了快速处理起来,所以定长是可以理解的;但当保存下来的时候,是否定长就是另外一回事了,可能用户更加关注的是文件的大小、传输的快慢等等。
或者说,UCS是你自己系统里面处理Unicode的,不关别人的是,但如果要跟别人交流数据,就要有一定的规范来传输比特流(就是数据啦),这个规范几时UTF。
进一步的,我们甚至可以这样理解,Unicode在内存处理的时候,是定长的,跟UCS对应,但保存成文件的时候(其实就是转化为具体的字节),就用UTF来编码。(可能有误,不过这样会比较好理解。)
目前我们接触比较多的UTF方式有两种UTF-16和UTF-8。UTF-16,顾名思义,就是用16位(两个字节)存储一个UCS-2编码。实际上,这种是最原始的存储方式,把UCS-2直接保存下来,对于少数字符会做一些特殊的处理,不过UTF-16和UCS-2基本上是差不多的。
说到这里,不得不提一下BOM这个东东。例如“汉”字的Unicode编码是6C49,在运算的时候是没什么问题的,直接wchar_t ch = 0x6C49就可以了。但保存成文件就有问题了,究竟是0x6C 0x49(叫Little Endian,低位在前。别搞错,0x6C是低位)还是0x49 0x6C(Big Endian,即高位在前)?于是就有了规定:在UTF-16前面加上两个特殊字符0xFF和0xFE。如果顺序为0xFF 0xFE,那就是就是LE低位在前,否则就是BE高位在前。默认不添加就是指LE。
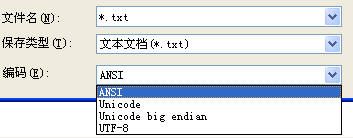
其实读者可以用WinXP的记事本试试。如下图,ANSI对于我们来说就是GBK,Unicode就是UTF-16(LE),Unicode big endian就是UTF-16(BE),UTF-8当然就是下面即将要介绍的UTF-8。可以把文章保存下来,用不同的编码保存,然后用UE看看十六进制。
虽然有UTF-16,不过欧美就不爽了:凭什么我为了你的汉字要多浪费一倍空间。于是,UTF8就出来了。UTF-8是一种不定长的UTF。UCS-2怎么转换到UTF-8我就不细说了,网上google一大把。下图是UTF-8的分布图,可以看出来,对于传统的ASCII,只需要一个字节,大大节省了空间,不过对于另外一些文字就恰恰相反了,最长的占3个字节。

为了跟好地理解UCS和UTF,读者可以回忆一下在Java里面String跟byte[]的转换:
String s = new String(bytes, “utf-8”);
byte[] bytes = s.getBytes(“utf-8”);
实际上,我们可以这样理解,s对象里面存储的数据,就是UCS,而bytes变量,则是UTF。
说完UCS和UTF,相信读者你已经对Unicode有了各大致的理解了吗?(还没有?对不起,我已经没有存货了。)我们再来聊聊另外一个话题:支持Unicode。
我们经常会听到:java支持Unicode,python也支持Unicode。到底什么是支持Unicode?
我觉得,所谓支持Unicode,无非就是三方面:
(1)有专门的数据类型存储UCS。
(2)方法、函数、相关逐渐支持UCS。
(3)能够正确处理各种UTF。
其实,只要原生字符和字符串是UCS(就是说,用wchar_t表示字符,而不是用char),外加一些处理UTF的函数,其实就相当于支持Unicode了。
看看手表,应该就5分钟啦。