hadoop-分布式安装及报错分析
1. 本人在虚拟机中安装了三台centos ,做了一个全分布式的hadoop集群,在网上有很多文章,大多都是一样,如果出错了,也不知道去哪里查,在此我也是试了好几天才试出来,在此把出错的地方记录下来,以便以后来反搭环境时有用。
1.安装SSH并配置无密码login ,这个在此不介绍,见另一blog,或网上有。
在此说明,我的三个centos ip为:
192.168.18.130 master
192.168.18.131 s131
192.168.18.132 s132
.在三台centos 中的 vi /etc/hosts 文件中只配置
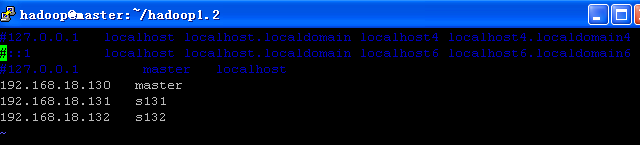
注意:把上面的127.0.0.1的前三行注释掉,如果有的话。这个对以后的启动时,在日志文件中会有报错,奇怪的报错,先去掉。
2. 在/etc/hosts 中的 master名,要与hostname相同,在/etc/sysconfig/network中的名子一样,如果是很一次配置完后,用 source /etc/sysconfig/network 或重login 一下 。
这个如果配不对的话,在后面 hadoop namenode -format 时,会报错, unkonw host,会有一个:
04.STARTUP_MSG: Starting NameNode
05.STARTUP_MSG: host = java.net.UnknownHostException: localhost.localdomain: localhost.localdomain
06.STARTUP_MSG: args = [-format]
07.STARTUP_MSG: version = 0.20.0
3. 在三台centos 中,都做同样的操作。
4. 在三台centos 中,建相同的账号如hadoop ,都归到同一个组hadoop中去。
账号: hadoop 的主目录为:/home/hadoop/ 中。
最好都用同一样账号,这个网上说也可以不用同一个账号,但可能会有问题,要输密码之类的,所以在局域网上,最好在所有的机器上,建相同的账号,配置SSH无密码登陆。
注意,配置ssh 时有个权限要求,网上有的没有讲到,我之前试了,如果权限过高,过低,远程的话,要输入密码,见另一blog .
5. 下载hadoop安装包,放到此账号的主目录下,如/home/hadoop/hadoop1.2下,
这里,网上都直接放在账号的主目录下了,猜想,也是权限的问题,放在另的目录下,因为在格式化hdfs时,会自已建立一些目录,如果放在别的目录下,会报权限不足。所以最好放在账号的主目录下。
6.修改配置文件,conf/core-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://192.168.18.130:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <!--<value>/hadoop/dfs/tmp</value>--> <value>/home/hadoop/tmp</value> </property> </configuration>
以上标红色的,一定在用IP地址,用master(机器名)不行,网上有的说行,我在启动后,导致
http://192.168.18.130:50030/jobtracker.jsp
State: RUNNING /////////// INITIALIZING 开始都是 initializing 装态,但所有的服务都能正常启动,注意去查看 logs/里面的日志 用 ll -tr 对文件的时间排序,用cat 查看日志文件,里面有很一些报错。
2. 对于 <value>/home/hadoop/tmp</value>
目录最好配一个,最好放在账号的主目录下,不用先建好,它会自动新建的。如果放在其它的目录下,还对对账号hadoop 赋权限 改变目录的所属者和所属组。
再配置mapred-site.xml 。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.18.130:9001</value>
</property>
</configuration>
定位jobtracker的主节点,这里最好也要用IP 地址,之前用的是master有问题 。
修改 hdfs-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- <property> <name>dfs.name.dir</name> <value>/hadoop/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/hadoop/hdfs/data</value> </property> --> </configuration>
dfs.replication 这是hdfs 的复杂数,还不清楚,这里的2 表示我这里有两台 slave机器,如果你有100台slave机器,1台master,这里就可以写成100,表示备份的数量。
下面可以单独配置hdfs 格式化的目录,如果不配置的话,它默认的目录在/home/hadoop/tmp/dfs下 ,当然,也可以配一个单独的目录,最好也配置在主目录下,如/home/hadoop/name /home/hadoop/data ,
如果配在其它目录下,要先建好,改变所属者,chown chgrp 等。
6. 再修改 conf/hadoop-env.sh ,这个文件中,只配一下JAVA_HOME,就行了。
7.修改conf/masters 如:
master #192.168.18.130
这里可以用主机名,
conf/slaves :
s131 s132 #192.168.18.131 #192.168.18.132
和上面一样。
8 .修改完后,再把整个文件用 scp 到另两台slave的此相同账号的主目录下如:
scp -R /home/hadoop/hadoop1.2/ hadoop@s131:/home/hadoop/
scp -R /home/hadoop/hadoop1.2/ hadoop@s132:/home/hadoop/
9. copy 完后,再格式化namenode 用:
bin/hadoop namenode -format
如果没有报错成功的话,再用:有报错的话,就报一个UnKnowHost的话,见上面。
bin/start-all.sh 启动。
用这个命令时,它会把主从上的所有节点服务都启动。在master上启动 namenode secondnamenode jobtracker. 在 slave 中有:datanode tasktracker 服务。
猜想:主master是怎么启动从机上的服务呢?
1.可能是和账号有关,都是同一个账号,主目录一样,
2. 整个hadoop1.2放的位置一样。都在 主目录下如: /home/hadoop/hadoop1.2/下,
3. 启动master后,再启动slaves 上的服务,就是找到和主master上相同的位置下去启动从slaves 上的服务。
只是猜想,目前还不清楚。
启动好后,在主master 可以用:
bin/hadoop dfs -ls
[hadoop@master hadoop1.2]$ bin/hadoop dfs -ls
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2014-01-08 15:12 /user/hadoop/in
drwxr-xr-x - hadoop supergroup 0 2014-01-08 15:11 /user/hadoop/out
drwxr-xr-x - hadoop supergroup 0 2014-01-08 15:13 /user/hadoop/out1
bin/hadoop fs -mkdir out2 新建,它还有很多命令。
用:[hadoop@master hadoop1.2]$ bin/hadoop dfsadmin -report 查看启动是否正确,如果都为0表示启动有问题,查看日志。
Configured Capacity: 8553406464 (7.97 GB)
Present Capacity: 6522089472 (6.07 GB)
DFS Remaining: 6521745408 (6.07 GB)
DFS Used: 344064 (336 KB)
DFS Used%: 0.01%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 2 (2 total, 0 dead)
Name: 192.168.18.131:50010
Decommission Status : Normal
Configured Capacity: 812650496 (775 MB)
DFS Used: 65536 (64 KB)
Non DFS Used: 722128896 (688.68 MB)
DFS Remaining: 90456064(86.27 MB)
DFS Used%: 0.01%
DFS Remaining%: 11.13%
Last contact: Wed Jan 08 16:44:06 CST 2014
Name: 192.168.18.132:50010
Decommission Status : Normal
Configured Capacity: 7740755968 (7.21 GB)
DFS Used: 278528 (272 KB)
Non DFS Used: 1309188096 (1.22 GB)
DFS Remaining: 6431289344(5.99 GB)
DFS Used%: 0%
DFS Remaining%: 83.08%
Last contact: Wed Jan 08 16:44:06 CST 2014
[hadoop@master hadoop1.2]$
或用:
http://192.168.18.130:50030/jobtracker.jsp
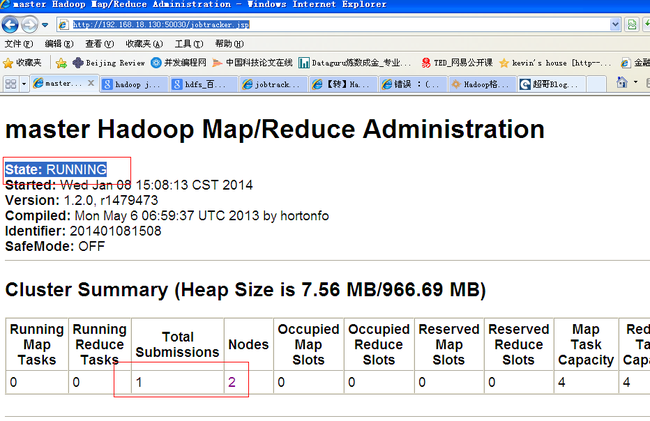
查看,如果状态不是RUNNING ,就有问题,查看日志。
用 bin/hadoop dfs -ls . 或不加. 查看dfs
这样,整个分布式的hadoop 就启动好了。
测试示例,bin/hadoop jar hadoop-example-1.2.0.jar wordcount in out3
这个 in 目录要先建一个,out3 不用新建,它会自已建,建了反而会报错。
bin/hadoop dfs -mkdir in 建立 dfs 目录。
再用 bin/hadoop dfs -ls out3/ 查看里面的文件,有一个:
-rw-r--r-- 2 hadoop supergroup 1306 2014-01-08 15:13 /user/hadoop/out1/part-r-00000
查看此文件即可:
[hadoop@master hadoop1.2]$ bin/hadoop dfs -cat out1/part-r-00000
就可以查看里面的内容。
注意:
要把三台机器的防火墙 都关闭,否则也会有问题。
用chkconfig iptables --list 查看:
[hadoop@master hadoop1.2]$ chkconfig iptables --list
iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off
如果有 on 的用
chkconfig --level 2345 iptables off
这个命令,要用root 用户去操作。
用此命令
bin/hadoop dfsadmin -report
启动好后,多试几次,在后台可以还在运行,状态由INITIALIZING -------------- RUNNING 需要几十秒的时间。