(14)多线程与并发库之java5同步集合类的应用【包含jdk1.5新特性 ConcurrentHashMap】
第一部分:
常用的集合类ArrayList、Map等在多线程操作同一对象时会发生不同步的线程而造成数据读取和写入错误;通常都是采用synchronized修饰符或Lock将那些方法括起来来确保它们在执行时不会被其他线程打扰;java5线程并发库为我们提供了一些相对于普通集合类的线程安全类,来自动解决线程同步的问题,如ConcurrentHashMap、ConcurrentSkipListMap、CopyOnWriteArrayList等。
下面一个程序演示了CopyOnWriteArrayList相对ArrayList的线程安全性
第二部分:jdk1.5新特性 ConcurrentHashMap【转自:http://blog.csdn.net/liuzhengkang/article/details/2916620】
集合是编程中最常用的数据结构。而谈到并发,几乎总是离不开集合这类高级数据结构的支持。比如两个线程需要同时访问一个中间临界区(Queue),比如常会 用缓存作为外部文件的副本(HashMap)。这篇文章主要分析jdk1.5的3种并发集合类型 (concurrent,copyonright,queue)中的ConcurrentHashMap,让我们从原理上细致的了解它们,能够让我们在深 度项目开发中获益非浅。
在tiger之前,我们使用得最多的数据结构之一就是 HashMap和Hashtable。大家都知道,HashMap中未进行同步考虑,而Hashtable则使用了synchronized,带来的直接 影响就是可选择,我们可以在单线程时使用HashMap提高效率,而多线程时用Hashtable来保证安全。
当 我们享受着jdk带来的便利时同样承受它带来的不幸恶果。通过分析Hashtable就知道,synchronized是针对整张Hash表的,即每次锁 住整张表让线程独占,安全的背后是巨大的浪费,慧眼独具的Doug Lee立马拿出了解决方案----ConcurrentHashMap。
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁。如图
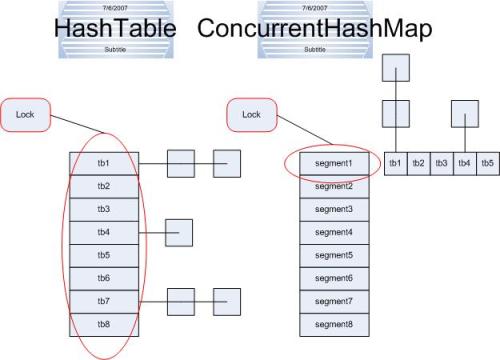
左 边便是Hashtable的实现方式---锁整个hash表;
而右边则是ConcurrentHashMap的实现方式---锁桶(或段)。
ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。
试想,原来 只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见的。
更 令人惊讶的是ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的 粒度又非常细,比起之前又更加快速(这一点在桶更多时表现得更明显些)。只有在求size等操作时才需要锁定整个表。而在迭代 时,ConcurrentHashMap使用了不同于传统集合的快速失败迭代器(见之前的文章《JAVA API备忘---集合》)的另一种迭代方式,我们称为弱一致迭代器。
在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出 ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数 据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变,更重要的,这保证 了多个线程并发执行的连续性和扩展性,是性能提升的关键。
接下来,让我们看看ConcurrentHashMap中的几个重要方法,心里知道了实现机制后,使用起来就更加有底气。
ConcurrentHashMap中主要实体类就是三个:
ConcurrentHashMap(整个Hash表),
Segment(桶),
HashEntry(节点),对应上面的图可以看出之间的关系。
get 方法(请注意,这里分析的方法都是针对桶的,因为ConcurrentHashMap的最大改进就是将粒度细化到了桶上),首先判断了当前桶的数据个数是 否为0,为0自然不可能get到什么,只有返回null,这样做避免了不必要的搜索,也用最小的代价避免出错。然后得到头节点(方法将在下面涉及)之后就 是根据hash和key逐个判断是否是指定的值,如果是并且值非空就说明找到了,直接返回;程序非常简单,但有一个令人困惑的地方,这句return readValueUnderLock(e)到底是用来干什么的呢?研究它的代码,在锁定之后返回一个值。但这里已经有一句V v = e.value得到了节点的值,这句return readValueUnderLock(e)是否多此一举?事实上,这里完全是为了并发考虑的,这里当v为空时,可能是一个线程正在改变节点,而之前的 get操作都未进行锁定,根据bernstein条件,读后写或写后读都会引起数据的不一致,所以这里要对这个e重新上锁再读一遍,以保证得到的是正确 值,这里不得不佩服Doug Lee思维的严密性。整个get操作只有很少的情况会锁定,相对于之前的Hashtable,并发是不可避免的啊!
put 操作 一上来就锁定了整个segment,这当然是为了并发的安全,修改数据是不能并发进行的,必须得有个判断是否超限的语句以确保容量不足时能够 rehash,而比较难懂的是这句int index = hash & (tab.length - 1),原来segment里面才是真正的hashtable,即每个segment是一个传统意义上的hashtable,如上图,从两者的结构就可以看 出区别,这里就是找出需要的entry在table的哪一个位置,之后得到的entry就是这个链的第一个节点,如果e!=null,说明找到了,这是就 要替换节点的值(onlyIfAbsent == false),否则,我们需要new一个entry,它的后继是first,而让tab[index]指向它,什么意思呢?实际上就是将这个新entry 插入到链头,剩下的就非常容易理解了。
remove 操作非常类似put,但要注意一点区别,中间那个for循环是做什么用的呢?(*号标记)从代码来看,就是将定位之后的所有entry克隆并拼回前面去, 但有必要吗?每次删除一个元素就要将那之前的元素克隆一遍?这点其实是由entry的不变性来决定的,仔细观察entry定义,发现除了value,其他 所有属性都是用final来修饰的,这意味着在第一次设置了next域之后便不能再改变它,取而代之的是将它之前的节点全都克隆一次。至于entry为什 么要设置为不变性,这跟不变性的访问不需要同步从而节省时间有关,关于不变性的更多内容,请参阅之前的文章《线程高级---线程的一些编程技巧》
以上,分析了几个最简单的操作,限于篇幅,这里不再对rehash或iterator等实现进行讨论,有兴趣可以参考src。
接下来实际上还有一个疑问,ConcurrentHashMap跟HashMap相比较性能到底如何。这在Brian Goetz的文章中已经有过评测http://www.ibm.com/developerworks/cn/java/j-jtp07233/ 。
另外主题:Java并发编程之ConcurrentHashMap:可以借鉴:
http://www.iteye.com/topic/1103980。分析得也很好。
最后:java.util.concurrent介绍总结:
http://www.cnblogs.com/sarafill/archive/2011/05/18/2049461.html