Scrapy入门文档,与实例解析(转的资料)
创建一个工程
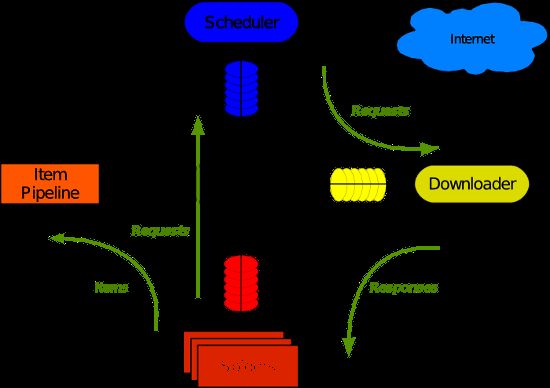
在你开始编写Scrapy的程序钱,你首先应该建立一个新的Scrapy工程.首先,进入你要创建工程的文件夹
scrapy startproject dmoz这样将会在dmoz目录下创建如下结构
dmoz/
scrapy.cfg
dmoz/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...其中的含义为:
» scrapy.cfg:项目的配置文件
» dmoz/: 项目的主模块,待会你将会从这里导入代码
» dmoz/items.py: 项目的item文件
» dmoz/pipelines.py: 项目的管道文件
» dmoz/settings.py: 项目设置文件
» dmoz/spiders/:待会你会将你的爬虫代码放在这里
定义我们的条目条目(Items)是一个我们与抓取的数据中间的一个交互,它的工作方式比较像Python的字典,但是它提供更多附加的特性比如提供默认值.
它通过建立一个scrapy.item.Item的类来生命,定义它的属性为scrpiy.item.Field对象,就像你在一个ORM中.
我们通过将我们需要的条目模型化来控制从dmoz.org获得的数据,比如我们要获得网站的名字,url和网站描述,我们定义这三种属性的范围,为了达到目的,我们编辑在dmoz目录下的items.py文件,我们的Item类将会是这样
# Define here the models for your scraped items
from scrapy.item import Item, Field
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()
开始看起来可能会有些困惑,但是定义这些条目让你用其他Scrapy的组件的时候你能够知道你的 items到底是如何定义。
第一个爬虫爬虫是一个用户用来从一个玩站或者多个网站上获取信息的类。
它定义一个 url列表来下载,如何跟踪链接,如何解析这些网页来获取条目。为了建立一个爬虫,你必须为scrapy.spider.BaseSpider创建一个子类,定义这三个属性:
» name: 爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字.
» start_urls:这是一个URL列表,爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些URLS开始。 下面计算的所有子URL将会从这些URL中开始计算
» parse() 爬虫的方法,调用时候传入从每一个URL传回的Response对象作为参数,response将会是parse方法的唯一的一个参数,这个方法负责解析返回的response数据匹配抓取的数据(解析为item)和其他的URL
The parse() method is in charge of processing the response and returning scraped data (as Item objects) and more URLs to follow (as Request objects).
这是我们的第一个爬虫, 将它保存名为 dmoz_spider.py 在dmoz/spiders 文件夹下
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz.org"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, 'wb').write(response.body)
抓取为了抓取网站,我们返回项目主目录执行以下命令
scrapy crawl dmoz.org这个 crawl dmoz.org 命令负责启动给 dmoz.org 的爬虫代码. 你将会获得如下输出
2008-08-20 03:51:13-0300 [scrapy] INFO: Started project: dmoz
2008-08-20 03:51:13-0300 [dmoz] INFO: Enabled extensions: ...
2008-08-20 03:51:13-0300 [dmoz] INFO: Enabled scheduler middlewares: ...
2008-08-20 03:51:13-0300 [dmoz] INFO: Enabled downloader middlewares: ...
2008-08-20 03:51:13-0300 [dmoz] INFO: Enabled spider middlewares: ...
2008-08-20 03:51:13-0300 [dmoz] INFO: Enabled item pipelines: ...
2008-08-20 03:51:14-0300 [dmoz.org] INFO: Spider opened
2008-08-20 03:51:14-0300 [dmoz.org] DEBUG: Crawled <http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/> (referer: <None>)
2008-08-20 03:51:14-0300 [dmoz.org] DEBUG: Crawled <http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: <None>)
2008-08-20 03:51:14-0300 [dmoz.org] INFO: Spider closed (finished)注意有 [dmoz.org]的输出 ,对我们的爬虫做出的结果(identified by the domain "dmoz.org"). 你可以看见在start_urls中定义的一些URL的一些输出。因为这些URL是起始页面,所以他们没有引用(referrers),所以在每行的末尾你会看到 (referer: <None>).
有趣的是,在我们的 parse 方法的作用下,两个文件被创建 Books 和 Resources, 这两个文件中有着URL的页面内容。
发生了什么事情?Scrapy为爬虫属性中的 start_urls中的每个URL创建了一个 scrapy.http.Request 对象 , 为他们指定爬虫的 parse 方法作为回调。
这些 Request首先被计划,然后被执行, 之后 scrapy.http.Response 对象通过parse() 方法返回给爬虫.
提取 Items Selectors入门为了从网站中提取数据,我们有很多方法. Scrapy 使用基于 XPath 的名字叫做 XPath selectors的机制。如果你想了解更多selectors和其他机制你可以查阅资料http://doc.scrapy.org/topics/selectors.html#topics-selectors
这是一些XPath表达式的例子和他们分别的含义
» /html/head/title: 选择HTML文档<head>下面的<title> 标签。
» /html/head/title/text(): 选择在 <title> 元素下面的标签内容.
» //td: 选择所有 <td> 标签
» //div[@class="mine"]: 选择所有 class="mine" 属性的div 标签元素
这些只是你可以通过XPath可以做的简单例子,但是XPath实际上非常强大,如果你想了解更多XPATH的内容,我们给你推荐这个教程http://www.w3schools.com/XPath/default.asp
为了方便使用XPaths, Scrapy提供XPathSelector 类, 一共有两种, HtmlXPathSelector (HTML数据解析) 和XmlXPathSelector (XML数据解析). 为了使用他们你必须通过一个 Response 对象对他们进行实例化操作.
你会发现Selector对象展示了文档的节点结构.所以,首先被实例化的selector与跟节点或者是整个目录有关 。
Selectors 有三种方法
» select(): 返回selectors列表, 每一个战士了通过xpath参数表达式而
选择的节点.http://doc.scrapy.org/topics/selectors.html#scrapy.selector.XPathSelector.select
»
extract(): 返回通过XPath选择器选择返回的数据的unicode字符串
» re(): 返回根据正则表达式匹配的一个unicode编码字符串列表
尝试在交互环境中使用Selectors为了举例说明Selectors的用法我们将用到 Scrapy shell, 需要使用ipython (一个扩展python交互环境) 。
为了使用交互环境,你首先应该进入你的项目目录,然后输入
scrapy shell http://www.dmoz.org/Computers/Programming/Languages/Python/Books/输出结果就像这样:
[ ... Scrapy log here ... ]
[s] Available Scrapy objects:
[s] 2010-08-19 21:45:59-0300 [default] INFO: Spider closed (finished)
[s] hxs <HtmlXPathSelector (http://www.dmoz.org/Computers/Programming/Languages/Python/Books/) xpath=None>
[s] item Item()
[s] request <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>
[s] response <200 http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>
[s] spider <BaseSpider 'default' at 0x1b6c2d0>
[s] xxs <XmlXPathSelector (http://www.dmoz.org/Computers/Programming/Languages/Python/Books/) xpath=None>
[s] Useful shortcuts:
[s] shelp() Print this help
[s] fetch(req_or_url) Fetch a new request or URL and update shell objects
[s] view(response) View response in a browser
In [1]:交互环境载入后,你将会有一个在本地变量 response 中提取的response , 所以如果你输入 response.body 你将会看到response的body部分,或者你可以输入 response.headers 来查看它的 headers.
交互环境也实例化了两种selectors, 一个是解析HTML的 hxs 变量 一个是解析 XML 的 xxs 变量 :
In [1]: hxs.select('/html/head/title')
Out[1]: [<HtmlXPathSelector (title) xpath=/html/head/title>]
In [2]: hxs.select('/html/head/title').extract()
Out[2]: [u'<title>Open Directory - Computers: Programming: Languages: Python: Books</title>']
In [3]: hxs.select('/html/head/title/text()')
Out[3]: [<HtmlXPathSelector (text) xpath=/html/head/title/text()>]
In [4]: hxs.select('/html/head/title/text()').extract()
Out[4]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [5]: hxs.select('/html/head/title/text()').re('(\w+):')
Out[5]: [u'Computers', u'Programming', u'Languages', u'Python']提取数据现在我们尝试从网页中提取数据.
你可以尝试在控制台输入 response.body , 检查这些 XPaths 来查找你需要的内容.然而,去检查这些节点是一件很枯燥的事情,为了使事情变得简单,你可以使用一些浏览器的扩展工具(比如Firefox中的firebug).
参考如下文档:http://doc.scrapy.org/topics/firefox.html#topics-firefox
http://doc.scrapy.org/topics/firebug.html#topics-firebug
检查源代码后,你会发现我们需要的数据在一个 <ul>元素中 事实是第二个<ul>元素。
我们可以通过如下命令选择每个在网站中的 <li> 元素:
hxs.select('//ul/li')
然后是网页描述:
hxs.select('//ul/li/text()').extract()
网站标题:
hxs.select('//ul/li/a/text()').extract()
网站超级链接:
hxs.select('//ul/li/a/@href').extract()
每个 select() 调用返回一个selectors列表, 所以我们可以结合 select() 调用去查找更深的节点. 我们将会用到这些特性,所以:
sites = hxs.select('//ul/li')
for site in sites:
title = site.select('a/text()').extract()
link = site.select('a/@href').extract()
desc = site.select('text()').extract()
print title, link, desc
Note
了解更多关于选择器的内容参考 Nesting selectors and Working with relative XPathsin the XPath Selectors documentation
让我们在spider爬虫中加入:
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
class DmozSpider(BaseSpider):
name = "dmoz.org"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
for site in sites:
title = site.select('a/text()').extract()
link = site.select('a/@href').extract()
desc = site.select('text()').extract()
print title, link, desc
现在我们再次尝试抓去dmoz.org
scrapy crawl dmoz.org使用条目(Item)Item 实质是python中的字典; 你可以查看某个字典的特定值,通过像下面这样的简单的语法:
>>> item = DmozItem()
>>> item['title'] = 'Example title'
>>> item['title']
'Example title'
Spiders将会返回在 Item 中抓取的信息 ,所以为了返回我们抓取的信息,spider的内容应该是这样:
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from dmoz.items import DmozItem
class DmozSpider(BaseSpider):
name = "dmoz.org"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.select('a/text()').extract()
item['link'] = site.select('a/@href').extract()
item['desc'] = site.select('text()').extract()
items.append(item)
return items
现在我们再次抓取 :
[dmoz.org] DEBUG: Scraped DmozItem(desc=[u' - By David Mertz; Addison Wesley. Book in progress, full text, ASCII format. Asks for feedback. [author website, Gnosis Software, Inc.]\n'], link=[u'http://gnosis.cx/TPiP/'], title=[u'Text Processing in Python']) in <http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>
[dmoz.org] DEBUG: Scraped DmozItem(desc=[u' - By Sean McGrath; Prentice Hall PTR, 2000, ISBN 0130211192, has CD-ROM. Methods to build XML applications fast, Python tutorial, DOM and SAX, new Pyxie open source XML processing library. [Prentice Hall PTR]\n'], link=[u'http://www.informit.com/store/product.aspx?isbn=0130211192'], title=[u'XML Processing with Python']) in <http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>保存抓取的信息最简单的保存信息的方法是通过 Feed exports, 命令如下:
scrapy crawl dmoz.org --set FEED_URI=items.json --set FEED_FORMAT=json将会计算出一个包含所有抓取items的 items.json 文件, 已经被JSON化.
在像本文一样的小型project中,这些已经足够. 然而,如果你想用抓取的items做更复杂的事情, 你可以写一个 Item Pipeline(条目管道). 因为在建立一个条目的时候,一个专门为项目的一个管道文件已经为这些items建立,目录在 dmoz/pipelines.py. 这样,如果你只是打算将这些抓取后的items博啊村的话你就不需要去检查任何的条目pipeline.
结束语教程简要介绍了Scrapy的使用,但是远远不够. 我们建议你继续查阅 Scrapy 0.12 documentation.
在你开始编写Scrapy的程序钱,你首先应该建立一个新的Scrapy工程.首先,进入你要创建工程的文件夹
scrapy startproject dmoz这样将会在dmoz目录下创建如下结构
dmoz/
scrapy.cfg
dmoz/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...其中的含义为:
» scrapy.cfg:项目的配置文件
» dmoz/: 项目的主模块,待会你将会从这里导入代码
» dmoz/items.py: 项目的item文件
» dmoz/pipelines.py: 项目的管道文件
» dmoz/settings.py: 项目设置文件
» dmoz/spiders/:待会你会将你的爬虫代码放在这里
定义我们的条目条目(Items)是一个我们与抓取的数据中间的一个交互,它的工作方式比较像Python的字典,但是它提供更多附加的特性比如提供默认值.
它通过建立一个scrapy.item.Item的类来生命,定义它的属性为scrpiy.item.Field对象,就像你在一个ORM中.
我们通过将我们需要的条目模型化来控制从dmoz.org获得的数据,比如我们要获得网站的名字,url和网站描述,我们定义这三种属性的范围,为了达到目的,我们编辑在dmoz目录下的items.py文件,我们的Item类将会是这样
# Define here the models for your scraped items
from scrapy.item import Item, Field
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()
开始看起来可能会有些困惑,但是定义这些条目让你用其他Scrapy的组件的时候你能够知道你的 items到底是如何定义。
第一个爬虫爬虫是一个用户用来从一个玩站或者多个网站上获取信息的类。
它定义一个 url列表来下载,如何跟踪链接,如何解析这些网页来获取条目。为了建立一个爬虫,你必须为scrapy.spider.BaseSpider创建一个子类,定义这三个属性:
» name: 爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字.
» start_urls:这是一个URL列表,爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些URLS开始。 下面计算的所有子URL将会从这些URL中开始计算
» parse() 爬虫的方法,调用时候传入从每一个URL传回的Response对象作为参数,response将会是parse方法的唯一的一个参数,这个方法负责解析返回的response数据匹配抓取的数据(解析为item)和其他的URL
The parse() method is in charge of processing the response and returning scraped data (as Item objects) and more URLs to follow (as Request objects).
这是我们的第一个爬虫, 将它保存名为 dmoz_spider.py 在dmoz/spiders 文件夹下
from scrapy.spider import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz.org"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
open(filename, 'wb').write(response.body)
抓取为了抓取网站,我们返回项目主目录执行以下命令
scrapy crawl dmoz.org这个 crawl dmoz.org 命令负责启动给 dmoz.org 的爬虫代码. 你将会获得如下输出
2008-08-20 03:51:13-0300 [scrapy] INFO: Started project: dmoz
2008-08-20 03:51:13-0300 [dmoz] INFO: Enabled extensions: ...
2008-08-20 03:51:13-0300 [dmoz] INFO: Enabled scheduler middlewares: ...
2008-08-20 03:51:13-0300 [dmoz] INFO: Enabled downloader middlewares: ...
2008-08-20 03:51:13-0300 [dmoz] INFO: Enabled spider middlewares: ...
2008-08-20 03:51:13-0300 [dmoz] INFO: Enabled item pipelines: ...
2008-08-20 03:51:14-0300 [dmoz.org] INFO: Spider opened
2008-08-20 03:51:14-0300 [dmoz.org] DEBUG: Crawled <http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/> (referer: <None>)
2008-08-20 03:51:14-0300 [dmoz.org] DEBUG: Crawled <http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: <None>)
2008-08-20 03:51:14-0300 [dmoz.org] INFO: Spider closed (finished)注意有 [dmoz.org]的输出 ,对我们的爬虫做出的结果(identified by the domain "dmoz.org"). 你可以看见在start_urls中定义的一些URL的一些输出。因为这些URL是起始页面,所以他们没有引用(referrers),所以在每行的末尾你会看到 (referer: <None>).
有趣的是,在我们的 parse 方法的作用下,两个文件被创建 Books 和 Resources, 这两个文件中有着URL的页面内容。
发生了什么事情?Scrapy为爬虫属性中的 start_urls中的每个URL创建了一个 scrapy.http.Request 对象 , 为他们指定爬虫的 parse 方法作为回调。
这些 Request首先被计划,然后被执行, 之后 scrapy.http.Response 对象通过parse() 方法返回给爬虫.
提取 Items Selectors入门为了从网站中提取数据,我们有很多方法. Scrapy 使用基于 XPath 的名字叫做 XPath selectors的机制。如果你想了解更多selectors和其他机制你可以查阅资料http://doc.scrapy.org/topics/selectors.html#topics-selectors
这是一些XPath表达式的例子和他们分别的含义
» /html/head/title: 选择HTML文档<head>下面的<title> 标签。
» /html/head/title/text(): 选择在 <title> 元素下面的标签内容.
» //td: 选择所有 <td> 标签
» //div[@class="mine"]: 选择所有 class="mine" 属性的div 标签元素
这些只是你可以通过XPath可以做的简单例子,但是XPath实际上非常强大,如果你想了解更多XPATH的内容,我们给你推荐这个教程http://www.w3schools.com/XPath/default.asp
为了方便使用XPaths, Scrapy提供XPathSelector 类, 一共有两种, HtmlXPathSelector (HTML数据解析) 和XmlXPathSelector (XML数据解析). 为了使用他们你必须通过一个 Response 对象对他们进行实例化操作.
你会发现Selector对象展示了文档的节点结构.所以,首先被实例化的selector与跟节点或者是整个目录有关 。
Selectors 有三种方法
» select(): 返回selectors列表, 每一个战士了通过xpath参数表达式而
选择的节点.http://doc.scrapy.org/topics/selectors.html#scrapy.selector.XPathSelector.select
»
extract(): 返回通过XPath选择器选择返回的数据的unicode字符串
» re(): 返回根据正则表达式匹配的一个unicode编码字符串列表
尝试在交互环境中使用Selectors为了举例说明Selectors的用法我们将用到 Scrapy shell, 需要使用ipython (一个扩展python交互环境) 。
为了使用交互环境,你首先应该进入你的项目目录,然后输入
scrapy shell http://www.dmoz.org/Computers/Programming/Languages/Python/Books/输出结果就像这样:
[ ... Scrapy log here ... ]
[s] Available Scrapy objects:
[s] 2010-08-19 21:45:59-0300 [default] INFO: Spider closed (finished)
[s] hxs <HtmlXPathSelector (http://www.dmoz.org/Computers/Programming/Languages/Python/Books/) xpath=None>
[s] item Item()
[s] request <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>
[s] response <200 http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>
[s] spider <BaseSpider 'default' at 0x1b6c2d0>
[s] xxs <XmlXPathSelector (http://www.dmoz.org/Computers/Programming/Languages/Python/Books/) xpath=None>
[s] Useful shortcuts:
[s] shelp() Print this help
[s] fetch(req_or_url) Fetch a new request or URL and update shell objects
[s] view(response) View response in a browser
In [1]:交互环境载入后,你将会有一个在本地变量 response 中提取的response , 所以如果你输入 response.body 你将会看到response的body部分,或者你可以输入 response.headers 来查看它的 headers.
交互环境也实例化了两种selectors, 一个是解析HTML的 hxs 变量 一个是解析 XML 的 xxs 变量 :
In [1]: hxs.select('/html/head/title')
Out[1]: [<HtmlXPathSelector (title) xpath=/html/head/title>]
In [2]: hxs.select('/html/head/title').extract()
Out[2]: [u'<title>Open Directory - Computers: Programming: Languages: Python: Books</title>']
In [3]: hxs.select('/html/head/title/text()')
Out[3]: [<HtmlXPathSelector (text) xpath=/html/head/title/text()>]
In [4]: hxs.select('/html/head/title/text()').extract()
Out[4]: [u'Open Directory - Computers: Programming: Languages: Python: Books']
In [5]: hxs.select('/html/head/title/text()').re('(\w+):')
Out[5]: [u'Computers', u'Programming', u'Languages', u'Python']提取数据现在我们尝试从网页中提取数据.
你可以尝试在控制台输入 response.body , 检查这些 XPaths 来查找你需要的内容.然而,去检查这些节点是一件很枯燥的事情,为了使事情变得简单,你可以使用一些浏览器的扩展工具(比如Firefox中的firebug).
参考如下文档:http://doc.scrapy.org/topics/firefox.html#topics-firefox
http://doc.scrapy.org/topics/firebug.html#topics-firebug
检查源代码后,你会发现我们需要的数据在一个 <ul>元素中 事实是第二个<ul>元素。
我们可以通过如下命令选择每个在网站中的 <li> 元素:
hxs.select('//ul/li')
然后是网页描述:
hxs.select('//ul/li/text()').extract()
网站标题:
hxs.select('//ul/li/a/text()').extract()
网站超级链接:
hxs.select('//ul/li/a/@href').extract()
每个 select() 调用返回一个selectors列表, 所以我们可以结合 select() 调用去查找更深的节点. 我们将会用到这些特性,所以:
sites = hxs.select('//ul/li')
for site in sites:
title = site.select('a/text()').extract()
link = site.select('a/@href').extract()
desc = site.select('text()').extract()
print title, link, desc
Note
了解更多关于选择器的内容参考 Nesting selectors and Working with relative XPathsin the XPath Selectors documentation
让我们在spider爬虫中加入:
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
class DmozSpider(BaseSpider):
name = "dmoz.org"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
for site in sites:
title = site.select('a/text()').extract()
link = site.select('a/@href').extract()
desc = site.select('text()').extract()
print title, link, desc
现在我们再次尝试抓去dmoz.org
scrapy crawl dmoz.org使用条目(Item)Item 实质是python中的字典; 你可以查看某个字典的特定值,通过像下面这样的简单的语法:
>>> item = DmozItem()
>>> item['title'] = 'Example title'
>>> item['title']
'Example title'
Spiders将会返回在 Item 中抓取的信息 ,所以为了返回我们抓取的信息,spider的内容应该是这样:
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from dmoz.items import DmozItem
class DmozSpider(BaseSpider):
name = "dmoz.org"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.select('a/text()').extract()
item['link'] = site.select('a/@href').extract()
item['desc'] = site.select('text()').extract()
items.append(item)
return items
现在我们再次抓取 :
[dmoz.org] DEBUG: Scraped DmozItem(desc=[u' - By David Mertz; Addison Wesley. Book in progress, full text, ASCII format. Asks for feedback. [author website, Gnosis Software, Inc.]\n'], link=[u'http://gnosis.cx/TPiP/'], title=[u'Text Processing in Python']) in <http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>
[dmoz.org] DEBUG: Scraped DmozItem(desc=[u' - By Sean McGrath; Prentice Hall PTR, 2000, ISBN 0130211192, has CD-ROM. Methods to build XML applications fast, Python tutorial, DOM and SAX, new Pyxie open source XML processing library. [Prentice Hall PTR]\n'], link=[u'http://www.informit.com/store/product.aspx?isbn=0130211192'], title=[u'XML Processing with Python']) in <http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>保存抓取的信息最简单的保存信息的方法是通过 Feed exports, 命令如下:
scrapy crawl dmoz.org --set FEED_URI=items.json --set FEED_FORMAT=json将会计算出一个包含所有抓取items的 items.json 文件, 已经被JSON化.
在像本文一样的小型project中,这些已经足够. 然而,如果你想用抓取的items做更复杂的事情, 你可以写一个 Item Pipeline(条目管道). 因为在建立一个条目的时候,一个专门为项目的一个管道文件已经为这些items建立,目录在 dmoz/pipelines.py. 这样,如果你只是打算将这些抓取后的items博啊村的话你就不需要去检查任何的条目pipeline.
结束语教程简要介绍了Scrapy的使用,但是远远不够. 我们建议你继续查阅 Scrapy 0.12 documentation.