简介
在前面的文章里我们讨论了commons-pool2的整体结构。在ObjectPool, PooledObject, PooledObjectFactory这三个大的类族里,ObjectPool是直接面向使用者的一个部分,而且相对来说也是最复杂的一个部分。这里,我们就深入它的细节详细分析一下。
详细分析
在深入代码之前,我们先回顾一下ObjectPool相关的结构图:

在前面的分析里我们已经提到,ObjectPool接口定义了Pool的基本操作功能,具体的实现可以由我们来选择。在这里默认提供的几个实现里有GenericObjectPool, GenericKeyedObjectPooled, SoftReferenceObjectPool.我们先从图中左边的那一块看过来。
SoftReferenceObjectPool
SoftReferenceObjectPool继承的是BaseObjectPool,而BaseObjectPool是一个实现ObjectPool的一些基本功能的抽象类。接口里大部分和Pool管理相关的功能这里都没有实现,主要就是增加了一个判断pool是否已经被关闭了的字段和方法。这部分的代码很小,可以截取下来看看:
@Override
public void close() {
closed = true;
}
/**
* Has this pool instance been closed.
*
* @return <code>true</code> when this pool has been closed.
*/
public final boolean isClosed() {
return closed;
}
/**
* Throws an <code>IllegalStateException</code> when this pool has been
* closed.
*
* @throws IllegalStateException when this pool has been closed.
*
* @see #isClosed()
*/
protected final void assertOpen() throws IllegalStateException {
if (isClosed()) {
throw new IllegalStateException("Pool not open");
}
}
private volatile boolean closed = false;
这里将定义的closed变量声明为volatile的类型是为了保证在多线程的环境下能够关闭pool而不至于产生问题。
我们再来看看SoftReferenceObjectPool:
SoftReferenceObjectPool很显然是一个SoftReference Object的Pool。而softreference对象有什么特点呢?如果我们对GC有一定了解的话会知道。我们定义的对象有强引用,弱引用,软引用以及虚引用等这么几种引用类型。而我们通常最常用的比如说Object obj = new Object()这样定义的对象返回的引用是强类型的。对于GC来说,它只有在当前程序访问的范围内不可达的强引用才能被回收。而想softreference则比较特殊一点,当系统内存不足的时候,他们可以被回收,而这个时候不用管是不是当前程序里可以被访问到。这样他们可以避免一些常用的内存泄露的问题。那么这个pool是怎么组成的呢?我们来看看里面基本成员的定义:
/** Factory to source pooled objects */
private final PooledObjectFactory<T> factory;
/**
* Queue of broken references that might be able to be removed from
* <code>_pool</code>. This is used to help {@link #getNumIdle()} be more
* accurate with minimal performance overhead.
*/
private final ReferenceQueue<T> refQueue = new ReferenceQueue<T>();
/** Count of instances that have been checkout out to pool clients */
private int numActive = 0; // @GuardedBy("this")
/** Total number of instances that have been destroyed */
private long destroyCount = 0;
/** Total number of instances that have been created */
private long createCount = 0;
/** Idle references - waiting to be borrowed */
private final LinkedBlockingDeque<PooledSoftReference<T>> idleReferences =
new LinkedBlockingDeque<PooledSoftReference<T>>();
/** All references - checked out or waiting to be borrowed. */
private final ArrayList<PooledSoftReference<T>> allReferences =
new ArrayList<PooledSoftReference<T>>();
这里的PooledObjectFactory用来创建封装的对象。ReferenceQueue用来注册softreference对象。当我们增加一个对象到pool里时会将对应的softreference注册到这个queue里。而idleReferences则是一个LinkedBlockingDequeue类型,它用来保存所有idle状态的对象。用它有一个好处就是以后要取对象的时候,直接从它那里直接拿就行了,而不用专门到pool里面去找,看哪个对象是idle状态。allReferences用来保存所有的对象Reference。
我们来看看几个典型的方法:
borrowObject:
borrowObject方法的主要流程是首先看里面的idleReferences是否为空,如果不为空,则从里面取一个对象出来并返回,否则通过factory来创建一个object。里面典型的代码如下:
public synchronized T borrowObject() throws Exception {
assertOpen();
T obj = null;
boolean newlyCreated = false;
PooledSoftReference<T> ref = null;
while (null == obj) {
if (idleReferences.isEmpty()) {
if (null == factory) {
throw new NoSuchElementException();
} else {
newlyCreated = true;
obj = factory.makeObject().getObject();
createCount++;
// Do not register with the queue
ref = new PooledSoftReference<T>(new SoftReference<T>(obj));
allReferences.add(ref);
}
} else {
ref = idleReferences.pollFirst();
obj = ref.getObject();
// Clear the reference so it will not be queued, but replace with a
// a new, non-registered reference so we can still track this object
// in allReferences
ref.getReference().clear();
ref.setReference(new SoftReference<T>(obj));
}
if (null != factory && null != obj) {
try {
factory.activateObject(ref);
if (!factory.validateObject(ref)) {
throw new Exception("ValidateObject failed");
}
} catch (Throwable t) {
PoolUtils.checkRethrow(t);
try {
destroy(ref);
} catch (Throwable t2) {
PoolUtils.checkRethrow(t2);
// Swallowed
} finally {
obj = null;
}
if (newlyCreated) {
throw new NoSuchElementException(
"Could not create a validated object, cause: " +
t.getMessage());
}
}
}
}
numActive++;
ref.allocate();
return obj;
}
这里主要的程序逻辑在这个while循环部分。在这个循环里我们要尽量保证能够成功创建一个对象,并激活和验证它。这种方式相当于一种尽量获取数据的方式,如果一次获取对象失败了就会一直尝试到整个pool为空或者出错了。while里面的判断逻辑比较好理解,首先是判断idleReferences是否为空,因为这个列表里就是放着所有空闲的对象。所以最简单的办法就是如果有就调用pollFirst取出来。如果没有的话则调用factory的makeObject方法来创建一个。后面的判断factory和obj是否为null的地方则是激活和验证对象的。如果发现创建的对象并不是valid的,则调用destroy方法将该对象销毁掉。
这里的流程比较讲究,就是我们虽然获取到这个object了,还需要通过factory的activateObject和validateObject来保证创建的对象正确性。有点像是工厂生产的产品还要做一个质检,发现次品就销毁。所以这样看来也就基本上明白了。
returnObject:
returnObject的逻辑是将使用过的对象返回到pool里面来。所以这里首先找到对象对应的reference,然后通过validateObject验证一下对象的状态,再将对象钝化,相当于封存起来。如果对象封存成功之后将它加入到idleReferences列表中。当然,对于验证失败的对象也会通过destroy方法销毁。这个方法的代码如下:
public synchronized void returnObject(T obj) throws Exception {
boolean success = !isClosed();
final PooledSoftReference<T> ref = findReference(obj);
if (ref == null) {
throw new IllegalStateException(
"Returned object not currently part of this pool");
}
if (factory != null) {
if (!factory.validateObject(ref)) {
success = false;
} else {
try {
factory.passivateObject(ref);
} catch (Exception e) {
success = false;
}
}
}
boolean shouldDestroy = !success;
numActive--;
if (success) {
// Deallocate and add to the idle instance pool
ref.deallocate();
idleReferences.add(ref);
}
notifyAll(); // numActive has changed
if (shouldDestroy && factory != null) {
try {
destroy(ref);
} catch (Exception e) {
// ignored
}
}
}
有了前面的说明,这部分的代码理解起来就很容易了。
addObject:
除了前面的borrowObject和returnObject,还有一个比较重要的方法就是addObject。它的主要作用就是在使用pool之前可以预先往里面放置一些对象。这样以后使用的时候可以减少创建对象的次数。我们来看看这部分的代码:
public synchronized void addObject() throws Exception {
assertOpen();
if (factory == null) {
throw new IllegalStateException(
"Cannot add objects without a factory.");
}
T obj = factory.makeObject().getObject();
createCount++;
// Create and register with the queue
PooledSoftReference<T> ref = new PooledSoftReference<T>(
new SoftReference<T>(obj, refQueue));
allReferences.add(ref);
boolean success = true;
if (!factory.validateObject(ref)) {
success = false;
} else {
factory.passivateObject(ref);
}
boolean shouldDestroy = !success;
if (success) {
idleReferences.add(ref);
notifyAll(); // numActive has changed
}
if (shouldDestroy) {
try {
destroy(ref);
} catch (Exception e) {
// ignored
}
}
}
这部分的代码看起来也比较长,其实它的过程很简单。我们首先通过factory.makeObject来创建对象,然后通过validateObject验证对象,验证通过之后再passivateObject,将它加入到idleReferences里面。这里凡是创建的对象不管是不是合法的都会加入到allReferences。这个allReferences相当于一个记录本一样,所有打过交道的对象都会在他这边有备案。所以我们在查找一些对象引用的时候会用到它。
其他方法
前面列举的3个方法是pool里最主要的功能。除了他们这几个还有一些辅助性质的方法。比如clear和close等方法。其中clear方法主要就是清除idleReferences列表里面的所有对象。这里清除对象用到了factory的destroyObject()方法。另外,我们提到过pool里用到ArrayList来保存所有的对象,而idleReferences保存所有idle的对象。所以也需要将这两个集合里所有的元素都remove掉。所以都调用了remove方法。
而close方法则更简单,就是设置一个closed变量为true.
在此,我们已经讨论完毕了一个典型的ObjectPool的实现。在这里其实还有几个实现,比如GenericObjectPool。我们在后面会参照这部分继续讨论。在说这部分之前,我们再分析一个东西。如果我们仔细看代码的话,会发现前面的这个pool里有一个定义的类型,为LinkedBlockingDeque。我们知道,在java的集合框架里,有LinkedBlockingQueue类,也有Dequeue接口定义,但是系统的默认实现里没有LinkedBlockingDeque。从字面上我们就可以理解,前面的LinkedBlockingQueue是一个单向操作的队列,这里肯定就是一个双向队列了。我们来看看它的细节吧。
LinkedBlockingDeque
在前面专门讨论Queue的文章里,我专门列举了几个典型的实现,如LinkedList和ArrayDeque。按照原来文章里描述的队列结构,我们也很容易找到LinkedBlockingDeque的结构层次和大致实现的思想。下面是LinkedBlockingDeque的相关类结构图。
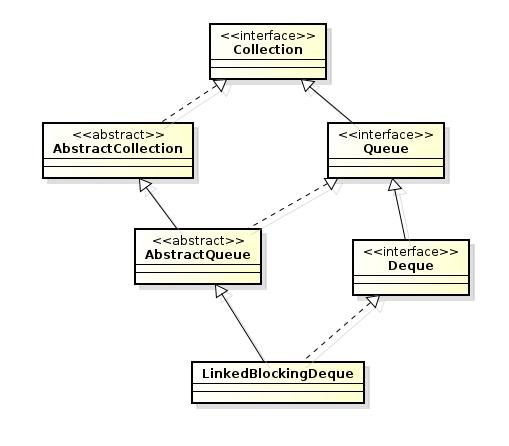
LinkedBlockingDeque主要继承了AbstractQueue和Deque接口。如果结合我们前面学习过的数据结构基础只是就可以知道。我们定义的Deque既然是双向队列,就需要至少有两个标识,一个表示列表的头一个表示列表的尾。对于列表里面的元素,我们也需要有一个专门的定义。至少是双向的,肯定有一个指向前面的引用和指向后面的引用。所以这部分的元素代码不用多想,就是这么个样子:
private static final class Node<E> {
/**
* The item, or null if this node has been removed.
*/
E item;
/**
* One of:
* - the real predecessor Node
* - this Node, meaning the predecessor is tail
* - null, meaning there is no predecessor
*/
Node<E> prev;
/**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head
* - null, meaning there is no successor
*/
Node<E> next;
/**
* Create a new list node.
*
* @param x The list item
* @param p Previous item
* @param n Next item
*/
Node(E x, Node<E> p, Node<E> n) {
item = x;
prev = p;
next = n;
}
}
private transient Node<E> first;
private transient Node<E> last;
这是LinkedBlockingDeque里面成员定义的一部分。没什么特殊的地方,一想就可以想到。我们再想想它更多详细的实现。其实作为一个双向队列,无非就是可以在两头添加和移除元素。也可以在两头获取元素。从他们的核心操作行为来说,无非就是这么6个方法。所以在这里就有addFirst, addLast, offerFirst, offerLast, putFirst, putLast, removeFirst, removeLast这么几个方法。他们的实现其实没有什么特殊的。主要是作为一个LinkedBlockingDeque,我们既然要强调它的blocking特性,这就说明他们一些对集合元素的操作是线程安全的。所以在实现里用了lock来实现互斥。另外,为了保证线程之间的同步等行为,这里利用了Lock的condition机制。这些声明的代码如下:
private final InterruptibleReentrantLock lock =
new InterruptibleReentrantLock();
/** Condition for waiting takes */
private final Condition notEmpty = lock.newCondition();
/** Condition for waiting puts */
private final Condition notFull = lock.newCondition();
我们知道,lock它本身也能实现synchronized同样的效果。所以这里所有的方法就没有使用synchronized关键字来修饰。这里很多实现的方法其实本身并不复杂,只是我们需要特别注意一些极端情况的判断,比如当时队列为空等情况。更多的细节可以通过源代码了解。
BaseGenericObjectPool
BaseGenericObjectPool是一个比较有意思的类。它本身是一个抽象类,只是作为一个GenericObjectPool和GenericKeyedObjectPool的公共抽象部分。后面的两个子类都要继承和使用它。这里主要定义了一些配置项和辅助的功能支持项。我们先看里面和dbcp关系很紧密的一部分看看。我们很多用过dbcp的人都知道,dbcp的配置项里很多特定的配置信息,比如说最大线程数,线程活跃时间以及是否每次取线程的时候都要测试它是否合法。在这里就可以找到对应配置项的声明了:
// Configuration attributes
private volatile int maxTotal =
GenericKeyedObjectPoolConfig.DEFAULT_MAX_TOTAL;
private volatile boolean blockWhenExhausted =
BaseObjectPoolConfig.DEFAULT_BLOCK_WHEN_EXHAUSTED;
private volatile long maxWaitMillis =
BaseObjectPoolConfig.DEFAULT_MAX_WAIT_MILLIS;
private volatile boolean lifo = BaseObjectPoolConfig.DEFAULT_LIFO;
private volatile boolean testOnBorrow =
BaseObjectPoolConfig.DEFAULT_TEST_ON_BORROW;
private volatile boolean testOnReturn =
BaseObjectPoolConfig.DEFAULT_TEST_ON_RETURN;
private volatile boolean testWhileIdle =
BaseObjectPoolConfig.DEFAULT_TEST_WHILE_IDLE;
private volatile long timeBetweenEvictionRunsMillis =
BaseObjectPoolConfig.DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS;
private volatile int numTestsPerEvictionRun =
BaseObjectPoolConfig.DEFAULT_NUM_TESTS_PER_EVICTION_RUN;
private volatile long minEvictableIdleTimeMillis =
BaseObjectPoolConfig.DEFAULT_MIN_EVICTABLE_IDLE_TIME_MILLIS;
private volatile long softMinEvictableIdleTimeMillis =
BaseObjectPoolConfig.DEFAULT_SOFT_MIN_EVICTABLE_IDLE_TIME_MILLIS;
private volatile EvictionPolicy<T> evictionPolicy;
在dbcp里,那是定义成一个配置文件的属性,实际上它是需要映射到这里来的。在后面对dbcp相关联的代码分析时,我们会详细讨论。这里算是埋下一个伏笔。
除了前面的这些配置项以外,我们还有一些比如统计创建过对象的数量,销毁过的对象数量以及因为活跃时间超时而被销毁的对象数量。这些定义为了保证多线程安全,定义为AtomicLong类型。所以这个类很大一部分的工作就是get和set这些属性。个人认为还有一个最重要的地方就是定义的一个Evictor,它继承了TimerTask,定期的会去扫描pool里面超时的对象,将他们做超时处理。Evictor的定义如下:
class Evictor extends TimerTask {
@Override
public void run() {
ClassLoader savedClassLoader =
Thread.currentThread().getContextClassLoader();
try {
// Set the class loader for the factory
Thread.currentThread().setContextClassLoader(
factoryClassLoader);
// Evict from the pool
try {
evict();
} catch(Exception e) {
swallowException(e);
} catch(OutOfMemoryError oome) {
// Log problem but give evictor thread a chance to continue
// in case error is recoverable
oome.printStackTrace(System.err);
}
// Re-create idle instances.
try {
ensureMinIdle();
} catch (Exception e) {
swallowException(e);
}
} finally {
// Restore the previous CCL
Thread.currentThread().setContextClassLoader(savedClassLoader);
}
}
}
具体的evict方法由下面的子类来定义。
GenericObjectPool
现在,我们再来看看GenericObjectPool的实现。有了前面SoftReferenceObjectPool的分析基础,我们再来看这部分就容易很多了。主要我们可以针对它的一些特定实现细节看看,整体的流程基本上是一样的。
和前面的实现比,它有什么特别的地方呢?首先它内部不是用ArrayList来保存所有的对象,而是用的ConcurrentHashMap。另外,为了支持JMX,它还添加了一些特定的属性。比如ONAME_BASE。我们列举一下这些属性:
// --- configuration attributes --------------------------------------------
private volatile int maxIdle = GenericObjectPoolConfig.DEFAULT_MAX_IDLE;
private volatile int minIdle = GenericObjectPoolConfig.DEFAULT_MIN_IDLE;
private final PooledObjectFactory<T> factory;
// --- internal attributes -------------------------------------------------
private final Map<T, PooledObject<T>> allObjects =
new ConcurrentHashMap<T, PooledObject<T>>();
private final AtomicLong createCount = new AtomicLong(0);
private final LinkedBlockingDeque<PooledObject<T>> idleObjects =
new LinkedBlockingDeque<PooledObject<T>>();
// JMX specific attributes
private static final String ONAME_BASE =
"org.apache.commons.pool2:type=GenericObjectPool,name=";
// Additional configuration properties for abandoned object tracking
private volatile AbandonedConfig abandonedConfig = null;
这里定义的ConcurrentHashMap比较特别,它采用的是我们创建的对象作为Key,而被封装成PooledObject作为Value。我们可以想象得到,borrowObject和returnObject的操作基本上还是这么些个固定的套路,首先判断idle列表里有没有对象,有就取一个,没有就用factory创建一个,并且还要用activateObject对象激活它并验证。对于验证失败的则销毁它。里面具体实现的代码确实就是这么一个过程,我们就不赘述。这里只是看一下典型的create和destroy方法:
private PooledObject<T> create() throws Exception {
int localMaxTotal = getMaxTotal();
long newCreateCount = createCount.incrementAndGet();
if (localMaxTotal > -1 && newCreateCount > localMaxTotal ||
newCreateCount > Integer.MAX_VALUE) {
createCount.decrementAndGet();
return null;
}
final PooledObject<T> p;
try {
p = factory.makeObject();
} catch (Exception e) {
createCount.decrementAndGet();
throw e;
}
AbandonedConfig ac = this.abandonedConfig;
if (ac != null && ac.getLogAbandoned()) {
p.setLogAbandoned(true);
}
createdCount.incrementAndGet();
allObjects.put(p.getObject(), p);
return p;
}
create方法会判断可以允许的最大对象数量,然后通过factory.makeObject来创建。同时需要调整里面创建对象的数量,并将它加入到ConcurrentHashMap allObjects里面。
destroy方法更简单:
private void destroy(PooledObject<T> toDestory) throws Exception {
toDestory.invalidate();
idleObjects.remove(toDestory);
allObjects.remove(toDestory.getObject());
try {
factory.destroyObject(toDestory);
} finally {
destroyedCount.incrementAndGet();
createCount.decrementAndGet();
}
}
就是将对象从idleObjects和allObjects里面移除,然后通过facoty.destroyObject来清理它。最后调整统计数量。
GenericObjectPool实现比较长,里面还有一些其他的方法。有了前面的分析之后可以很容易弄明白,这里也就不一一列举了。同样对于GenericKeyedObjectPool我们也可以类似的分析出它的实现细节来。
总结
看源代码是一个比较磨人的事情,有的时候经常会看到一部分然后很难理解人家这么做的意图。通过里面对一些特性的运用也可以加深我们的理解。Commons-pool2和dbcp有很密切的联系。dbcp里使用到的pool就是用的pool2的实现。不过目前从官方网站看到的是dbcp还不支持最新的dbcp。这并不妨碍我们在后续的文章里分析dbcp的实现细节,也可以顺带思考一下如果我们要升级dbcp使用commons-pool2我们该怎么去改进他们。