说一说iText(3)
现在来看看怎样通过iText将含有中文字符的html文件转换为pdf文件?问题不在于转换的难度,主要是iText对中文的支持不够好,所以需要修改源代码
首先在com.itextpdf.tool.xml.html.HTMLUtils.java中增加:
然后在com.itextpdf.tool.xml.css.apply.ChunkCssApplier.java的public Chunk apply(final Chunk c, final Tag t)方法中增加如下判断:
最后将修改之后的源代码重新打包使用,我们对如下cnDemo.html文件进行转换,关于重新打包我有话说--> 点击看
转换的代码如下:
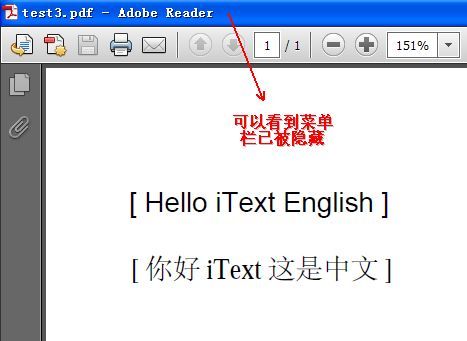
生成的pdf文件截图如下:
首先在com.itextpdf.tool.xml.html.HTMLUtils.java中增加:
public class HTMLUtils {
//定义基础中文字体
public static BaseFont cnBF = null;
static {
try {
cnBF = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H",
BaseFont.NOT_EMBEDDED);
} catch (DocumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//判断单个字符是否是中文字符
public static boolean isCN(char c) {
Character.UnicodeBlock ub = Character.UnicodeBlock.of(c);
if (ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS
|| ub == Character.UnicodeBlock.CJK_COMPATIBILITY_IDEOGRAPHS
|| ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A
|| ub == Character.UnicodeBlock.GENERAL_PUNCTUATION
|| ub == Character.UnicodeBlock.CJK_SYMBOLS_AND_PUNCTUATION
|| ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS) {
return true;
}
return false;
}
//判断字符串是否含有中文字符
public static boolean isCN(String str) {
char[] csOfStr = str.toCharArray();
for (char c : csOfStr) {
if (isCN(c)) {
return true;
}
}
return false;
}
然后在com.itextpdf.tool.xml.css.apply.ChunkCssApplier.java的public Chunk apply(final Chunk c, final Tag t)方法中增加如下判断:
public Chunk apply(final Chunk c, final Tag t) {
Font f = applyFontStyles(t);
//增加对中文字符的判断
if(HTMLUtils.cnBF!=null&&HTMLUtils.isCN(c.getContent())){
f=new Font(HTMLUtils.cnBF,f.getSize(),f.getStyle(),f.getColor());
}
最后将修改之后的源代码重新打包使用,我们对如下cnDemo.html文件进行转换,关于重新打包我有话说--> 点击看
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" dir="ltr" lang="zh-CN"> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <title>iText xmlworker</title> </head> <body> <div> <p>[ Hello iText English ]</p> <p>[ 你好 iText 这是中文 ]</p> </div> </body> </html>
转换的代码如下:
public static void main(String[] args) throws DocumentException,
IOException {
String pdfPath = "d:/test3.pdf";
Document doc = new Document(PageSize.A4);
PdfWriter pdfWriter = PdfWriter.getInstance(doc, new FileOutputStream(
pdfPath));
// 隐藏菜单栏
pdfWriter.setViewerPreferences(PdfWriter.HideMenubar);
doc.open();
InputStreamReader isr = new InputStreamReader(Test3.class
.getClassLoader().getResourceAsStream("cnDemo.html"));
XMLWorkerHelper.getInstance().parseXHtml(pdfWriter, doc, isr);
doc.close();
}
生成的pdf文件截图如下: