STL系列之九 探索hash_set
Title: STL系列之九 探索hash_set
Author: MoreWindows
Blog: http://blog.csdn.net/MoreWindows
E-mail: [email protected]
KeyWord: C++ STL set hash_set 哈希表 链地址法
本文将着重探索hash_set比set快速高效的原因,阅读本文前,推荐先阅读本文的姊妹篇《STL系列之六 set与hash_set》
一.hash_set之基石——哈希表
hash_set的底层数据结构是哈希表,因此要深入了解hash_set,必须先分析哈希表。哈希表是根据关键码值(Key-Value)而直接进行访问的数据结构,它用哈希函数处理数据得到关键码值,关键码值对应表中一个特定位置再由应该位置来访问记录,这样可以在时间复杂性度为O(1)内访问到数据。但是很有可能出现多个数据经哈希函数处理后得到同一个关键码——这就产生了冲突,解决冲突的方法也有很多,各大数据结构教材及考研辅导书上都会介绍大把方法。这里采用最方便最有效的一种——链地址法,当有冲突发生时将具同一关键码的数据组成一个链表。下图展示了链地址法的使用:
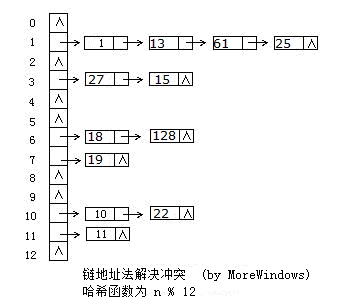
二.简化版的hash_table
按照上面的分析和图示,并参考《编程珠玑》第15章中哈希表的实现,不难写出一个简单的哈希表,我们称之为简化版hash_table。该哈希表由一个指针数组组成,数组中每个元素都是链表的表头指针,程序分为hash_table.h,hash_table.cpp和main.cpp。
1.hash_table.h
2.hash_table.cpp
3.main.cpp
在main.cpp中,对set、hash_set、简化版hash_table作一个性能测试,测试环境为Win7+VS2008的Release设置(下同)。
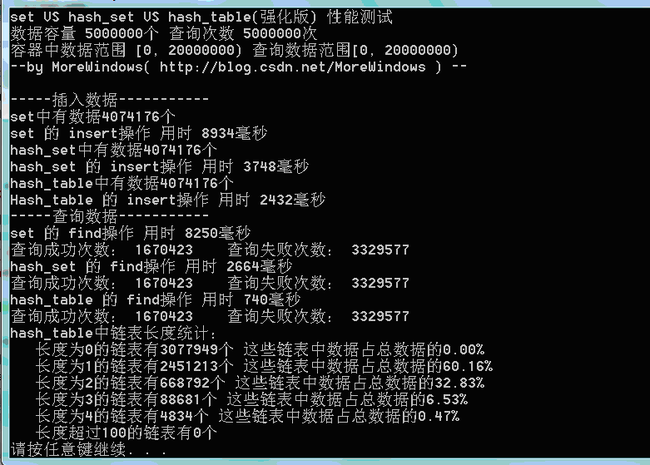
在数据量为500万时测试结果如下:

从程序运行结果可以发现,我们自己实现的hash_table(简化版)在插入和查找的效率要远高于set。为了进一步分析,最好能统计hash_table中的各个链表的长度情况,这样可以有效的了解平均每次查找要访问多少个数据。写出统计hash_table各链表长度的函数如下:
用此段代码得到链表长度的统计结果:

可以发现在hash_table中最长的链表也只有5个元素,长度为1和长度为2的链表中的数据占全部数据的89%以上。因此绝大数查询将仅仅访问哈希表1次到2次。这样的查询效率当然会比set(内部使用红黑树——类似于二叉平衡树)高的多。有了这个图示,无疑已经可以证明hash_set会比set快速高效了。但hash_set还可以动态的增加表的大小,因此我们再实现一个表大小可增加的hash_table。
三.强化版hash_table
首先来看看VS2008中hash_set是如何实现动态的增加表的大小,hash_set是在hash_set.h中声明的,在hash_set.h中可以发现hash_set是继承_Hash类的,hash_set本身并没有太多的代码,只是对_Hash作了进一步的封装,这种做法在STL中非常常见,如stack栈和queue单向队列都是以deque双向队列作底层数据结构再加一层封装。
_Hash类的定义和实现都在xhash.h类中,微软对_Hash类的第一句注释如下——
hash table -- list with vector of iterators for quick access。
哈哈,这句话说的非常明白。这说明_Hash实际上就是由vector和list组成哈希表。再阅读下代码可以发现_Hash类增加空间由_Grow()函数完成,当空间不足时就倍增,并且表中原有数据都要重新计算hash值以确定新的位置。
知道了_Hash类是如何运作的,下面就来考虑如何实现强化版的hash_table。当然有二个地方还可以改进:
1._Hash类使用的list为双向链表,但在在哈希表中使用普通的单链表就可以了。因此使用STL中的vector再加入《STL系列之八 slist单链表》一文中的slist来实现强化版的hash_table。
2.在空间分配上使用了一个近似于倍增的素数表,最开始取第一个素数,当空间不足时就使用下一个素数。经过实际测试这种效果要比倍增法高效一些。
在这二个改进之上的强化版的hash_table代码如下:
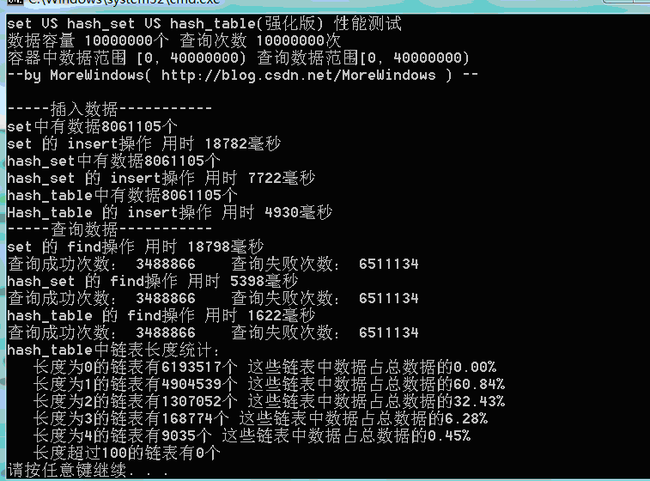
下面再对set、hash_set、强化版hash_table的性能测试:
测试结果一(数据量500万):
测试结果二(数据量1千万):
测试结果三(数据量1千万):
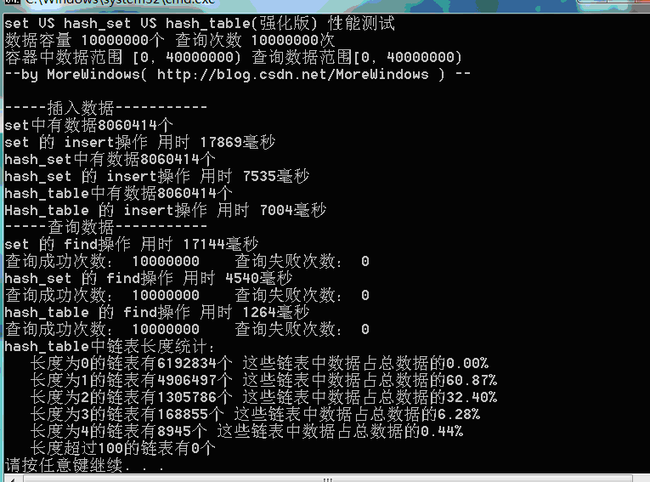
可以看出,由于强化版hash_table的哈希表在增加表空间大小时会花费额外的一些时间,所以插入数据的用时与STL提供的hash_set用时相差不多了。但查找还是比hash_set要快的一些。
四.结语
从简化版到强化版的hash_table,我们不仅知道了hash_set底层数据结构——哈希表的运作机制,还知道了如何实现大小动态变化的哈希表。达到了本文让读者了解hash_set快速高效的原因。当然本文所给hash_table距真正的hash_set还有不小的距离,有兴趣的读者可以进一步改进。
此外,本文所示范的哈希表也与最近流行的NoSql数据库颇有渊源, NoSql数据库也是通过Key-Value方式来访问数据的(访问数据的方式上非常类似哈希表),其查找效率与传统的数据库相比也正如本文中hast_set与set的比较。正因为NoSql数据库在基础数据结构上的天然优势,所以它完全可以支持海量数据的查询修改且对操作性能要求很高场合如微博等。
转载请标明出处,原文地址:http://blog.csdn.net/morewindows/article/details/7330323