搜索排序结果的控制
Lucnen作为搜索引擎中,应用最为广泛和成功的开源框架,它对搜索结果的排序,有一套十分完整的机制来控制;但我们控制搜索结果排序的目的永远只有一个,那就是信息过滤,让用户快速,准确的找到其想要的结果,丰富用户体验。
以前看过一个牛人的博客,总结了4个地方,可对Lucene检索结果的排序进行控制,现在已经记不住。我自己简单整理了下面几个,若有疏漏,欢迎补充:
1. 通过Lucene自有的查询表达式:Lucene提供相当丰富的表达式解析,要细讲就多了去了;这里只强调下,我在项目中用的比较多的是通过对指定域的加权,来影响检索结果(例如:field1:(XXX)^10 or field2:(XXX)^5;其中XXX是用户提交的检索)
2. 权重的控制:这是在建索引的时候就写入索引的,查询时只是读取出来,用乘的方式来对一些检索结果加分。据我自己看Lucene代码,Similarity中也能在建索引时,对权重的写入进行控制;后面会细讲。
3. Controller 模块:Lucene的排序流程控制模块,里面提供的一些接口能让你对打分后的搜索结果进行一些筛选和调整。
4. Similarity 模块:Lucene的搜索结果打分控制模块,也是这里要详细分析的模块。他能让你对一个检索结果的打分进行优化,或面目全非,哈哈。
Lucene的打分公式
要理解Similarity模块对打分结果控制,首先要了解Lucene自己评分原理:相似度评分公式;此公式是目前公认的用户体验较好的一个,原理是根据余弦定理。下面是在摘自《Lucene实战》(第二版)的公式表达式:
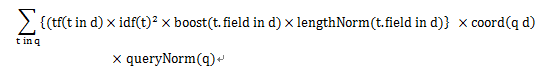
其中q 为查询语句,t 是q 分词后的每一项, d为去匹配的文档。
接下来对公式中的每一个函数,进行详解,他们都能在 Similarity 模块中进行控制。
Lucene打分流程
首先,我简单说明下,Lucene对一次查询是如何封装;这涉及到对打分公式是如何调用的,如此一来更能全面的了解打分流程:
第一步的处理肯定是分词,查询语句 => term_1, term_2 … term_n(n∈[1,∞]),紧接着是将这些term 封装成Query对象,总的Query对象是BooleanQuery,它里面包含和分词数相同TermQuery,和分词后的词项一一对应;这是对一个域的查询,若你多个域联合查询,那就会有多个这样的BooleanQuery,被一个更大的BooleanQuery包裹着。
而打分公式,贯穿所有Query,其中一部分在TermQuery中计算,一部分在BooleanQuery计算,最后按此计算出的得分进行排序,就得到了我们的搜索结果。
下面是我通过explain(Query query, int doc) 导出的打分解释:

对照Lucene的打分解释,我们一层一层往里拨(上述每个缩进为一层),每一个函数都能在Similarity中进行控制。
1. 首先第一层:3.3936599 = (MATCH) product of:,是此条记录的总得分。
2. 第二层:8.48414992 = (MATCH) sum of: 它对应一个BooleanQuery,它把它包含的TermQuery的得分累加起来,由于TermQuery总共有5个,此条结果中只匹配了2个,所以最后一行将得分乘以了0.4得到最后的打分,coord()在Similarity中的默认实现如下:
/** Implemented as <code>overlap / maxOverlap</code>. */
@Override
public float coord(int overlap, int maxOverlap) {
return overlap / (float)maxOverlap;
}
你也可以继承Similarity对此方法重写。
3. 第三层:(MATCH) weight(field:XXX in m), product of: 有2个,它们分别是“三国”、“无双”对应的词项查询TermQuery的得分。
再往里,就是TermQuery的打分规则了,里面的函数已经和公式有所对应了,下面就详细介绍TermQuery中每一项计算的作用。
Similarity 函数详解
TermQuery中有4个函数,都是Similarity里可以控制的函数,他们分别是queryNorm、tf、idf、fieldNorm;
queryNorm:
对于某一次搜索中结果的排序没有影响,在一次搜索中queryNorm的值是固定的。这里就不介绍了
tf(t in q)
此函数表示词项T 在该文档中的该字段里 出现的频率;对应到上图的例子中:既是分词后的词项(三国或 无双)在此条记录中Name字段里出现的频率。当然出现的次数越多,它返回的值越大,也正好反映了此文档的重要性。下面是DefaultSimilarity 中的默认实现的默认实现。
/** Implemented as <code>sqrt(freq)</code>. */
@Override
public float tf(float freq) {
return (float)Math.sqrt(freq);
}
默认实现是开平方。同样你可以重写此函数。
它实际对结果排序的影响,表现和它的意义一样,一个搜索结果包含的搜索关键词越多,得分越高。
idf(t)
此函数出现了两次,也刚好对应公式中的 idf(t)^2;
这个函数被称作倒频率,表示词项T 在所有文档中出现的频率。若它在所有文档中出现的次数越多,表明这个词项T 越不重要;以下是DefaultSimilarity的默认实现。
/** Implemented as <code>log(numDocs/(docFreq+1)) + 1</code>. */
@Override
public float idf(int docFreq, int numDocs) {
return (float)(Math.log(numDocs/(double)(docFreq+1)) + 1.0);
}
此函数实际对结果排序的影响,在于当一次搜索包含多个词项时,文档A和B分别包含了其中一个词项;比如A包含“三国”,B包含“无双”;那么“三国”和“无双”的倒频率就会影响,让A、B的得分产生差异了。若词项只有一个,那本次搜索idf(t) 实际对结果排序不会产生影响。
fieldNorm (t)
3.0以后:computeNorm(String field, FieldInvertState state)
它的值对应着公式中 boost(t.field in d)×lengthNorm(t.field in d) 的值。其中boost(t.field in d)的值,在创建索引时就被记录下来,而lengthNorm(t.field in d)得值,会在查询过程中计算;它表示此条搜索结果中,给定字段中包含词项的总数;若值越大,得分越低;你可以这么理解;若A文档有包含了1000个词项,关键词出现的频率为10;而B文档包20个词项,相同关键词出现的频率为8;很明显B文档的打分应该要高一些;由此函数可以起到这样的效果。以下是Similarity 的默认实现,函数名在3.0以后变了,原来就叫lengthNorm
/** Decodes a normalization factor stored in an index.
* <p>
* <b>WARNING: If you override this method, you should change the default
* Similarity to your implementation with {<a href="http://my.oschina.net/link1212" target="_blank" rel="nofollow">@link</a> Similarity#setDefault(Similarity)}.
* Otherwise, your method may not always be called, especially if you omit norms
* for some fields.</b>
* <a href="http://my.oschina.net/u/244147" target="_blank" rel="nofollow">@see</a> #encodeNormValue(float)
*/
public float decodeNormValue(byte b) {
return NORM_TABLE[b & 0xFF]; // & 0xFF maps negative bytes to positive above 127
}
至此Lucene打分流程和Similarity模块的函数已经将的差不多了。可以通过这些函数让你的搜索展示出完全不一样的效果,这也需要根据不同的业务慢慢调试,才能得出最优化的搜索结果 。