在Spark Standalone集群模式下,Driver运行在客户端,所谓的客户端就是提交代码的那台机器。在Standalone模式下,角色包括:
Driver(Client,这里的Client对应到Spark的代码中是AppClient吗?)如下图所示,Driver位于提交代码的那台机器(提交代码的机器是Client),
Master
Worker(Worker是一个进程,它其中会有多个Executor)
Executor
为什么说Driver是在提交代码的那台机器上呢?
SparkConf类中有个关于Driver的参数设置,如下代码在SparkContext的构造方法中
// Set Spark driver host and port system properties
conf.setIfMissing("spark.driver.host", Utils.localHostName()) ////host是本地,意思是可以设置的??
conf.setIfMissing("spark.driver.port", "0")
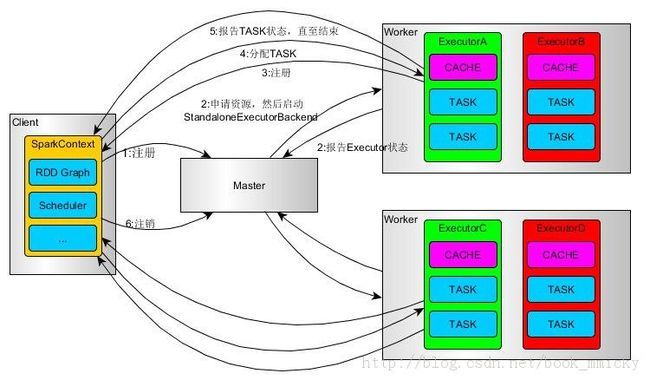
时序:
1.Client(Driver)向Master提交Application----通过spark-sumbit提交,指定master=spark:///
2. Master收到Driver的Application请求,申请资源(实际上是Worker的Executor),启动StandaloneExecutorBackend,StandaloneExecutorBackend是Worker跟外界通信的代表
3.图中的第3步代码中是否有体现?
4.Executor启动后,Driver就可以分配Task(launchTask)
5.作业执行过程中,Worker向Driver汇报任务的执行情况
用户的程序分成两部分,一个是初始化SparkContext,定义针对数据的各种函数操作实现业务逻辑(对应不同的RDD),当SparkContext通过runJob提交后,接下来的工作由Driver完成?
Driver是作业的驱动器(或者主进程),负责Job的解析,生成Stage,并调度Task到Executor上执行,其核心和精髓是DAGScheduler和TaskScheduler,通过AKKA消息驱动的方式完成
不是很理解!!这些工作都是SparkContext来完成的,SparkContext中有DAGScheduler和TaskScheduler,为什么会分成两部分?
Driver分为两部分:
1是SparkContext以及围绕这SparkContext的SparkConf和SparkEnv
2是DAGScheduler,TaskScheduler以及部署模块(部署模块主要是TaskScheduler使用)
Driver通过launchTask发送任务给Executor?Executor内部以线程池多线程的方式并行的运行任务(实际顺序是SparkContext.runJob->DagScheduler.runJob->DAGScheduler.submitJob->TaskScheduler.runbJob->TaskSetManager给LocalActor或者CoarseGrainedActor发送lanchTask消息,CoarseGrainedActor受到消息后调用Executor的lauchTask方法)
SparkConf
SparkConf一旦传递给SparkContext后就不能再修改,因为SparkContext构造时使用了SparkConf的clone方法。
SparkEnv
1.LiveListenerBus
里面有个org.apache.spark.scheduler.LiveListenerBus用于广播SparkListenerEvents到SparkListeners,SparkListenerEvents都定义在SparkListener.scala中
/** * Asynchronously passes SparkListenerEvents to registered SparkListeners. * * Until start() is called, all posted events are only buffered. Only after this listener bus * has started will events be actually propagated to all attached listeners. This listener bus * is stopped when it receives a SparkListenerShutdown event, which is posted using stop(). */
2. SparkEnv类似集群全局变量,在Driver中有,在Worker的Executors中也有,而Worker的Executors有多个,那么每个Executor的每个线程都会访问SparkEnv变量,Spark使用ThreadLocal来保存SparkEnv变量。因此,SparkEnv是一个重量级的东西。
CoarseGrainedSchedulerBackend
1. 在org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend其中创建了DriverActor
// TODO (prashant) send conf instead of properties
driverActor = actorSystem.actorOf(
Props(new DriverActor(properties)), name = CoarseGrainedSchedulerBackend.ACTOR_NAME)
2.CoarseGrainedSchedulerBackend有一个子类org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend
关注它的start方法,其中的一句:
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries, libraryPathEntries, javaOpts)
这个命令用于在Standalone模式下,通过CoarseGrainedExecutorBackend的命令方式启动Executor?
override def start() {
super.start()
// The endpoint for executors to talk to us
val driverUrl = "akka.tcp://%s@%s:%s/user/%s".format(
SparkEnv.driverActorSystemName,
conf.get("spark.driver.host"),
conf.get("spark.driver.port"),
CoarseGrainedSchedulerBackend.ACTOR_NAME)
val args = Seq(driverUrl, "{{EXECUTOR_ID}}", "{{HOSTNAME}}", "{{CORES}}", "{{APP_ID}}",
"{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath").toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
val libraryPathEntries =
sc.conf.getOption("spark.executor.extraLibraryPath").toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
///用于启动Executor的指令?
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries, libraryPathEntries, javaOpts)
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
////将command封装到appDesc类中
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir)
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf) ////App的Client,
///启动ClientActor
client.start()
waitForRegistration()
}
3.AppClient类
def start() {
// Just launch an actor; it will call back into the listener.
actor = actorSystem.actorOf(Props(new ClientActor))
}
Client
org.apache.spark.deploy.Client(是一个object) org.apache.spark.deploy.yarn.Client(是一个object) org.apache.spark.deploy.yarn.client(这是一个私有类) org.apache.spark.deploy.client.AppClient(这是一个私有类) 这几个类都在什么集群模式下起作用,用来做什么的?
未分类:
1.除了action触发Job提交,checkpoint也会触发job提交
2.提交Job时,首先计算Stage的依赖关系,从后面往前追溯,前面