Java:用HtmlParser抓取新浪博客文章内容
htmlparser是一个纯的java写的html解析的库,它不依赖于其它的java库文件. 下载地址为: http://htmlparser.sourceforge.net
新浪博客文章html页面:
// 新浪博客韩寒的一篇文章内容部分的tag, 文章地址:http://blog.sina.com.cn/s/blog_4701280b0100jbqq.html
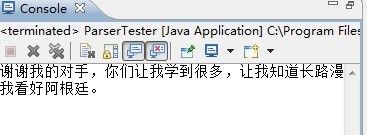
<div class="articalContent" id="sina_keyword_ad_area2"><p STYLE="TexT-inDenT: 2em"> 谢谢我的对手,你们让我学到很多,让我知道长路漫漫。关于类似的一切,我的看法从未改变。两年前我就已经说过一遍,雷同观点如今不想再多说了,说来说去都是一样,说多了就累了,在累之前我认输,否则就灰心了。你们胜利了,请随意。如果你是我的读者,我希望你们不要以任何名义去驱逐任何一种文化,更不要想教训和消灭它的受众群体,无论是文化还是政治都不能排他,也不能代替别人做出选择,哪怕它很傻,哪怕它不合你的口味,只要它不反人类。我曾经无意识的带领你们去往各个博客铲除异己,如今我欣喜的看到我们共同的进步,四年前的我一定带不走今天的你。热血一定要洒在它该洒的地方,否则它就叫鸡血。在此我也正式向现代诗歌以及现代诗人道歉,三年前我的观点是错的,对你们造成的伤害带来的误会,我很愧疚,碍于面子,一直没说,希望你们的原谅与理解。愿文化之间,年代之间,国家之间都能消除成见,为了……你知道的。</P> <p STYLE="TexT-inDenT: 2em">我看好阿根廷。</P></div>
观察html文档可知, 只要抽取出名为div 且属性class为articlecontent的tag(标签)就可以找到文章正文. 下面看代码:
public static String getContent(String urlString)
throws Exception
{
URL url = new URL(urlString);
URLConnection conn = url.openConnection();
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 7.0;)");
conn
.setRequestProperty(
"Accept",
"image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/msword, application/vnd.ms-excel, application/vnd.ms-powerpoint, */*");
BufferedReader reader = new BufferedReader(
new InputStreamReader(conn.getInputStream(), "utf-8"));
String line = "";
StringBuilder sb = new StringBuilder();
while ((line = reader.readLine()) != null) {
sb.append(line + "\r\n");
}
return sb.toString();
}
private String processText(String content)
{
content = content.trim().replaceAll(" ", " ");
return content;
}
public String getSinaArticleContent(String url)
throws Exception
{
String content = getContent(url);
StringBuilder sb = new StringBuilder();
Parser parser = Parser.createParser(content, "utf-8");
AndFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("class", "articalContent"));
Node node = null;
NodeList nodeList = parser.extractAllNodesThatMatch(filter);
for (int i = 0; i < nodeList.size(); ++i) {
node = nodeList.elementAt(i);
sb.append(node.toPlainTextString());
}
return processText(sb.toString());
}
public static void main(String[] args)
throws Exception
{
ParserTester pt = new ParserTester();
System.out.println(pt.getSinaArticleContent("http://blog.sina.com.cn/s/blog_4701280b0100jbqq.html"));
}
效果: