0 关于配置机器别名,配置IP和别名映射,设置IP,关闭防火墙和自启动,单机下配置ssh请参考
hadoop1.1.2伪分布式安装(单机版)的文章, 链接:
http://chengjianxiaoxue.iteye.com/admin/blogs/2093575
1 先安装好一台单机版的hadoop, 别名为master
2 准备另外两台虚拟机, 这里分别命令为 sliver103, sliver104,
可以通过vmware下安装iso文件方式准备这两台虚拟机,
也可以通过将master机器关闭后,右键master,在管理中选择拷贝虚拟器,选择完全拷贝方式来创建
这里是通过第一种方式准备的。
3 sliver103, sliver104机器上配置好机器别名,关闭防火墙,在hosts里配置上这三台机器
各机器配置好hosts如下(以sliver103举例)
[root@sliver103 .ssh]# more /etc/hosts
# Do not remove the following line, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
192.168.1.103 sliver103
192.168.1.104 sliver104
192.168.1.105 master
4 master, sliver103,sliver104各自机器上生成rsa密钥对,
并生成各自机器的公钥文件(ssh默认的公钥文件是用户home/.ssh/authorized_keys),
可以通过 cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys 实现生成公钥文件,这样每台机器中的公钥文件就含有各自机器的信息,在实现多机器互通执行ssh-copy-id -i下,直接会将别的机器内公钥信息拷贝到本机中
生成后查看如下:
查看各自节点的公共key:
[root@sliver103 .ssh]# cat authorized_keys
......mMlwpVtEEGTQ== root@sliver103
[root@sliver104 .ssh]# cat authorized_keys
......mMlwpVtEEGTQ== root@sliver104
[root@master .ssh]# cat authorized_keys
......mMlwpVtEEGTQ== root@master
5 实现三台机器ssh通:
先将两台机器的公钥key拷贝到第三个节点上:
[root@master .ssh]# ssh-copy-id -i sliver103 这样master就可以无密码下访问 sliver103
[root@sliver104 .ssh]# ssh-copy-id -i sliver103 这样sliver104就可以无密码下访问 sliver103
拷贝完后 可以通过如下命令来验证是否可以免密码登陆
[root@master .ssh]# ssh sliver103
Last login: Sat Aug 30 22:08:04 2014 from localhost.localdomain
查看 sliver103的公钥文件(authorized_keys):
发现会增加:
...== root@master
...== root@sliver104
然后再将 sliver103的公钥文件拷贝到 master , sliver104机器上,
这样每台机器的公钥文件都包含另外两台的公钥文件内容,实现了三台机器之间免密码登陆的目的,操作如下:
[root@sliver103 .ssh]# scp /root/.ssh/authorized_keys master:/root/.ssh
[root@sliver103 .ssh]# scp /root/.ssh/authorized_keys sliver104:/root/.ssh
5.1 解释机器之间免密码ssh互通, 看下图,这也了解了为毛需要将客户端机器的公钥文件需要拷贝到目标机器才能实现ssh互通的原因:
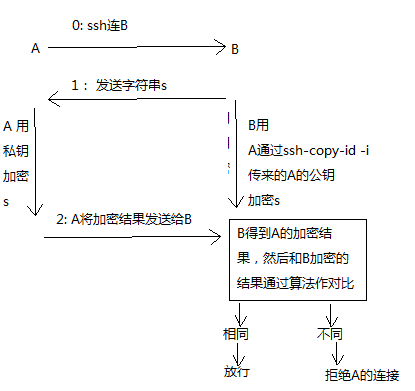
5.2 解释 ssh-copy-id -i:可以把本地的ssh公钥文件安装到远程主机对应的账户下,是一个脚本命令
6 拷贝master机器的jdk, hadoop, 和profile到另外两台机器:
删除master的部分数据
因为以前是伪分布 所以要删除以前的信息
[root@master hadoop]# rm -rf logs/
[root@master hadoop]# rm -rf tmp/
拷贝jdk到另外两台机器
[root@master hadoop]# scp -r /usr/local/jdk sliver103:/usr/local
[root@master hadoop]# scp -r /usr/local/jdk sliver104:/usr/local
拷贝hadoop到另外两台机器 scp表示加密拷贝
[root@master local]# scp -r /usr/local/hadoop sliver104:/usr/local
[root@master local]# scp -r /usr/local/hadoop sliver103:/usr/local
拷贝环境变量到另外两台机器
[root@master local]# scp /etc/profile sliver103:/etc/
[root@master local]# scp /etc/profile sliver104:/etc/
后重启下配置文件:
[root@sliver103 local]# source /etc/profile
[root@sliver104 local]# source /etc/profile
7 配置主从(仅仅在master节点中修改即可):
[root@master local]# cd hadoop/conf/
[root@master conf]# vi slaves // 添加从节点, 修改成如下
[root@master conf]# cat slaves
sliver103
sliver104
8 启动:
执行格式化 并启动
[root@master local]# hadoop namenode -format
[root@master hadoop]# sh bin/start-all.sh
starting namenode, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-namenode-master.out 启动namenode
sliver103: starting datanode, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-datanode-sliver103.out 在103上启动datanode
sliver104: starting datanode, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-datanode-sliver104.out 在104上启动datanode
localhost: starting secondarynamenode, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-secondarynamenode-master.out 启动secondarynamenode
starting jobtracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-jobtracker-master.out 启动jobtracker
sliver103: starting tasktracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-tasktracker-sliver103.out 在103上启动tasktracker
sliver104: starting tasktracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-tasktracker-sliver104.out 在103上启动tasktracker
[root@master hadoop]# jps // 此时namenode 上只有如下几项
11373 SecondaryNameNode
11446 JobTracker
11118 NameNode
11585 Jps
[root@sliver103 local]# jps // datanode下只有datanode的信息
28217 Jps
28046 DataNode
28140 TaskTracker
[root@sliver104 local]# jps
19702 TaskTracker
19615 DataNode
19814 Jps
10 指定secondarynamenode位置,取代默认设置做法:
将secondarynamenode 启动从master上剥离: ----> master的 hadoop/conf/masters下修改成:
[root@master conf]# cat masters
sliver103
重新启动后:
[root@master hadoop]# jps
17404 NameNode
17695 Jps
17597 JobTracker
[root@sliver103 local]# jps
30078 SecondaryNameNode
30006 DataNode
30393 Jps
30169 TaskTracker
[root@sliver104 local]# jps
20618 DataNode
20727 TaskTracker
20860 Jps
11 jobtracker , namenode , datanode由什么来决定
namenode:
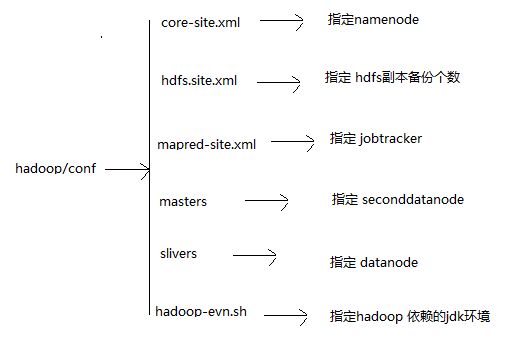
# cat core-site.xml
<name>fs.default.name</name>
<value>hdfs://master:9000</value> -->此处指定别名为master的机器作namenode
jobtracker:
# cat mapred-site.xml
<name>mapred.job.tracker</name>
<value>master:9001</value> -->此处指定别名为master的机器作jobtracker
指定 secondnamenode:
主节点的 hadoop/conf/masters 内指定secondnamenode对应机器名
指定 datanode:
主节点的 hadoop/conf/slivers 内指定datanode对应机器名
12 hadoop1/conf下个配置文件作用:
分布式安装流程如下:
1.hadoop的分布式安装过程
1.1 分布结构 主节点(1个,是hadoop0):NameNode、JobTracker、SecondaryNameNode
从节点(2个,是hadoop1、hadoop2):DataNode、TaskTracker
1.2 各节点重新产生ssh加密文件
1.3 编辑各个节点的/etc/hosts,在该文件中含有所有节点的ip与hostname的映射信息
1.4 两两节点之间的SSH免密码登陆
ssh-copy-id -i hadoop1
scp /root/.ssh/authorized_keys hadoop1:/root/.ssh/
1.5 把hadoop0的hadoop目录下的logs和tmp删除
1.6 把hadoop0中的jdk、hadoop文件夹复制到hadoop1和hadoop2节点
scp -r /usr/local/jdk hadoop1:/usr/local/
1.7 把hadoop0的/etc/profile复制到hadoop1和hadoop2节点,在目标节点中执行source /etc/profile
1.8 编辑hadoop0的配置文件slaves,改为从节点的hostname,分别是hadoop1和hadoop2
1.9 格式化,在hadoop0节点执行hadoop namenode -format
1.10 启动,在hadoop0节点执行start-all.sh
****注意:对于配置文件core-site.xml和mapred-site.xml在所有节点中都是相同的内容。
2.动态的增加一个hadoop节点
2.1 配置新节点的环境(eg:机器名 jdk hadoop ssh 机器名和ip对应关系)
2.2 把新节点的hostname配置到主节点的slaves文件中
2.3 在新节点,启动进程
hadoop-daemon.sh start datanode
hadoop-daemon.sh start tasktracker
2.4 在主节点执行脚本 hadoop dfsadmin -refreshNodes 通知nomenode(通知老大我来了)
3.动态的下架一个hadoop节点
拔掉网线