1 受控表(managed table):
hive中将创建的表和实际对应hdfs目录结构和文件相对应,如果删除hive中创建的表,对应hdfs的目录和文件
将不复存在,这种表叫做受控表。
受控表(managed table)包括内部表、分区表、桶表。
2 分区表简介:
a) 分区表是把数据放在不同的磁盘文件中,hive数据库会对不同分区进行单独管理,优化,
最终会加快数据查询速度。
b) 分区表分区的含义:也是把数据进行划分不同的区,hive中的区是指不同子文件夹中。
c) 分区表创建原因: 100M的学生信息,如果查询班级为1班的学生,在不使用分区表时,
需要去100M中遍历查询,如果使用分区表,只需要去文件夹名称为1班的hdfs文件中查找即可。
d) 分区字段简介:
d.1) 分区字段就是文件夹的标识名称,
d.2) 在正常使用的时候,分区字段是作为正常字段被使用,但是在数据文件中不存在,
仅作为虚拟列(virtual column)存在
e) 分区过多的坏处:
如果分区过多,hive在扫描时,一级级的扫来扫去,会增加扫描成本, 在运行时,对于map端造成map任务增多。
f) 选用哪些字段作为分区呢:
f.1) 选用平时查询比较频繁的字段,比如 地区 时间查,
f.2) 分区后产生的文件并不是很多的字段来, 比如 按照姓名 ID来查询,就不能使用分区,否则要产生很多分区
g) 操作:
g.1) 单分区表创建和查询:
创建单分区表:
create table jiuye(id int, name string) partitioned by(grade int) row format delimited fields terminated by '\t';
load data local inpath '/usr/local/data/user' into table jiuye partition(grade='1');
load data local inpath '/usr/local/data/user' into table jiuye partition(grade='2');
load data local inpath '/usr/local/data/user' into table jiuye partition(grade='3');
从单分区表中查询数据
select * from jiuye where grade=3 // 此语句仅仅会从文件夹名称为3的hdfs中查找数据
注意 这个分区字段 '' 也可以不加,比如写成:
load data local inpath '/usr/local/data/user' into table jiuye partition(grade=3);
查询结果:
hive> select * from jiuye where grade = 3
> ;
OK
1 zhangsan 3
2 lisi 3
3 wangwu 3
4 zhaoliu 3
分区后hdfs的样子:
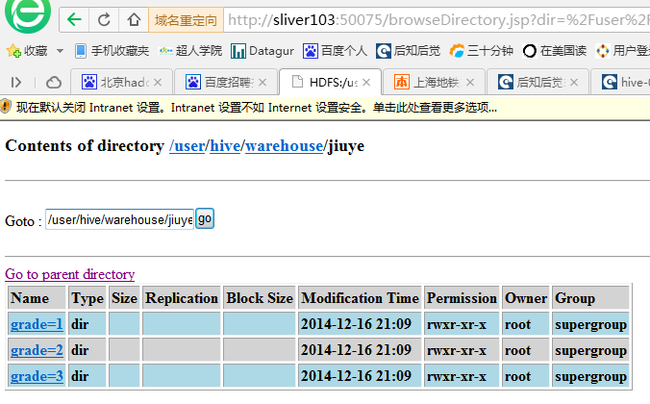
g.2) 多分区字段插入和查询写法:
create table member(id int, name string) partitioned by(year int, month int) row format delimited fields terminated by '\t'; load data local inpath '/usr/local/data/user' into table member partition(year=2014, month=1);// hdfs中目录为 2014/1/member load data local inpath '/usr/local/data/user' into table member partition(year=2014, month=2);// hdfs中目录为 2014/2/member hive> select * from member where year=2014 and month=1; OK 1 zhangsan 2014 1 2 lisi 2014 1 3 wangwu 2014 1 4 zhaoliu 2014 1
g.3) 缺陷:
选定分区字段之后, 结果会造成数据偏差特别大,这样整个查询时间受制于分区特别大的,对于整个作业的运行效率是不好的,
比如 淘宝按照用户所在省份来分区, 北京的订单用户要比青海西藏等偏远省的总和还要多很多
3 桶表简介:
a) 概念: 桶表是对数据进行哈希取值,然后放到不同文件中存储,数据加载到桶表时,会对某字段(这个字段会在创建桶表时通过clustered by(xx)指定)取hash值,然后与桶的数量取模。把数据放到对应的文件中,
Hive会启动一个MapReduce的job来产生数据,该job中reduce任务的数量与桶的数量是一致的。每个reduce任务会产生一个文件
<!--EndFragment-->b) 使用场景:
适用于: 抽样查询 或者表连接查询
不适用于: 根据业务查询数据(因为数据是按照hash来存放,和业务没有任何关系)
c) 和分区表的异同:
相同点: 都是用于对数据的划分
不同点: 前者是根据业务来进行划分,后者是抛弃业务字段从纯数据角度来划分
d) 操作写法:
创建表 create table buck(id int, name string) clustered by(id) into 4 buckets; 分成4个桶,使用id和4取模,根据结果不同分到不同文件中存储 加载数据 set hive.enforce.bucketing = true; // 启用桶 (默认是不用桶的) insert overwrite table bucket_table select name from stu; // 会对id进行hash计算然后在将数据放在不同桶中, 分区表中加载数据仅仅是将磁盘数据直接加载到hive中
结果:
stu数据: 1 zhangsan 2 lisi 3 wangwu 4 zhaoliu 1 zhangsan 2 lisi 3 wangwu 4 zhaoliu 1 zhangsan 2 lisi 3 wangwu 4 zhaoliu

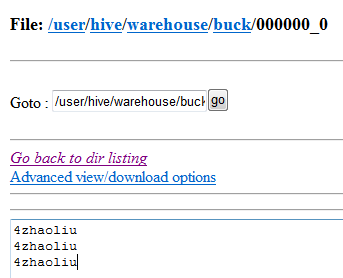
其余三个文件内容在此不再展示 ....
4 外部表简介:
只需要指定目录即可, 比较灵活,
外部表
create external table ext_table(c1 string, c2 string) row format delimited fields terminated by '\t' location '/files'; 1 使用关键词 external表面外部表。 '/files' 表示关联 hdfs文件系统根目录下files目录内将文件 hello hello1内的数据 2 location用于指定数据在哪里,只能使用文件夹来指定位置, 3 删除外部表 不会损坏hdfs文件内容
创建后数据为:
hive> select * from ext_table; OK 1,zhangsan NULL 2,lisi NULL 3,wangwu NULL 1,45 NULL 2,56 NULL 3,89 NULL
删除后 hdfs/files内文件 hello hell1均存在: