与字符串共舞、字符串的数据类型、设置客户端的连接字符集、控制字符串的大小写敏感、正则表达式进行模式匹配
mysql cookbook0005
与字符串共舞
5.0 引言
- 字符串分为二进制和非二进制两种(二进制:是一个字节序列,包含任何类型的信息,且不予字符集关联:就是图像、语音、加密数值等;非二进制:文本-关联到字符集和排序方面)
- 字符集决定哪些字符是合法的,而排序(collation)决定字符次序是否对大小写敏感。
- 二进制的数据类型:binary、varbinary、bolb;非二进数据类型:char varchar text.
5.1 字符串属性
- 非二进制特征:
- 查看数据库中有哪些字符集:show character set;
- 在unicode字符集ucs2中,所有的字符集都是2个字节,即使在Latin1中是1个字节;mysql> set @s := convert('abc' using ucs2);
Query OK, 0 rows affected (0.03 sec)
mysql> select length(@s),char_length(@s);
+------------+-----------------+
| length(@s) | char_length(@s) |
+------------+-----------------+
| 6 | 3 |
+------------+-----------------+
1 row in set (0.00 sec) - 在unicode字符集utf8包中包含多字节的字符,但是一个具体的utf8字符可能只占用一个字节mysql> set @s=convert('abc' using utf8);
Query OK, 0 rows affected (0.00 sec)
mysql> select length(@s),char_length(@s);
+------------+-----------------+
| length(@s) | char_length(@s) |
+------------+-----------------+
| 3 | 3 |
+------------+-----------------+
1 row in set (0.00 sec) - collation,它决定了字符集中字符的排序次序:show collation like 'latin1%';
- collcation可以分为:大小写敏感(a与A不同),大小写不敏感(a与A相同),二进制(两个字符的异同取决于两个字符对应的数值是否相同)
- mysql> select c from t order by c collate latin1_swedish_ci;
+------+
| c |
+------+
| AAA |
| aaa |
| bbb |
| BBB |
+------+
4 rows in set (0.04 sec)
mysql> select c from t order by c collate latin1_general_cs;
+------+
| c |
+------+
| AAA |
| aaa |
| BBB |
| bbb |
+------+
4 rows in set (0.04 sec)
mysql> select c from t order by c collate latin1_bin;
+------+
| c |
+------+
| AAA |
| BBB |
| aaa |
| bbb |
+------+
4 rows in set (0.00 sec) - 注意,因为字符不同大小写的数值不同,一个二进制collation会产生一个大小写敏感的排序,不过,这个排序与大小写敏感collation的排序还是不同的
5.2 选择字符串的数据类型
- 选择字符串的数据类型要考虑一下几点?
- 字符串是否是二进制数据
- 是否大小写敏感
- 字符串的最大长度是多少
- 想存储定长值还是变长值
- 是否需要保留尾部空格
- 是否有固定的允许值集合
2.讨论选择针对上面的问题
- 对于二进制的数据类型,最大长度是最多必须容纳的字节数,非二进制是最多必须容纳的字符数。
- 在填充时,在不满空间时系统会自动填充:二进制填充0X00,非二进制填充空白;检索时清除填充的字节或字符
- 对于变长的varbinary,varchar,text,blob不会填充字节或字符;检索时也不再需要清除填充数据
- 假如你想保留出现原始字符串尾部的填充值,那么就应该选择没有截取动作发生的数据类型
- 例如:
mysql> create table t (
-> c1 varchar(30),
-> c2 char(20));
ERROR 1050 (42S01): Table 't' already exists
mysql> create table t2 (
-> c1 varchar(30),
-> c2 char(20));
Query OK, 0 rows affected (0.21 sec)
mysql> insert into t2 values('aaa ','aaa ');
mysql> select c1,c2, char_length(c1),char_length(c2) from t2;
+--------+------+-----------------+-----------------+
| c1 | c2 | char_length(c1) | char_length(c2) |
+--------+------+-----------------+-----------------+
| aaa | aaa | 6 | 3 |
+--------+------+-----------------+-----------------+
1 row in set (0.00 sec)
-> c1 varchar(30),
-> c2 char(20));
ERROR 1050 (42S01): Table 't' already exists
mysql> create table t2 (
-> c1 varchar(30),
-> c2 char(20));
Query OK, 0 rows affected (0.21 sec)
mysql> insert into t2 values('aaa ','aaa ');
mysql> select c1,c2, char_length(c1),char_length(c2) from t2;
+--------+------+-----------------+-----------------+
| c1 | c2 | char_length(c1) | char_length(c2) |
+--------+------+-----------------+-----------------+
| aaa | aaa | 6 | 3 |
+--------+------+-----------------+-----------------+
1 row in set (0.00 sec)
通过上面的显示可以知道char是去空格添加数据到数据库中的。
一个既能包括二进制,和非二进制,并且可以指定非二进制的字符集和collation:
mysql> create table mytbl(
-> utf8data varchar(100) character set utf8 collate utf8_danish_ci,
-> sjisdata varchar(100) character set sjis collate sjis_japanese_ci);
Query OK, 0 rows affected (0.41 sec)
-> utf8data varchar(100) character set utf8 collate utf8_danish_ci,
-> sjisdata varchar(100) character set sjis collate sjis_japanese_ci);
Query OK, 0 rows affected (0.41 sec)
列的定义可以省略character set 或者 collation 或者 全部
- 当你指定了character set 而省略了collation时,默认使用字符集的collation
- 当你省略了character set 指定了collation时,字符集会使用collation的前半部分指定的字符集
- 当你同时省略的时候,那么使用默认建表时指定的字符集和collation
- 当你建表时省略指定时,默认使用建库指定的字符集和collation
- 当你建库省略了指定,默认使用服务器默认的值
- 当你修改选项文件时,启动服务器服务器时使用配置文件中配置的,服务器默认是使用latin1字符集,Latin1_swedish_ci collation
mysql也支持:enum 和 set 用于存储有固定的取值集合的数据
注意:假如你需要特定语言进行排序你可以选课专有的collation,但是collation必须在字符集的范围之内。
mysql> create table t4(c varchar(20) character set utf8);
Query OK, 0 rows affected (0.16 sec)
mysql> insert into t4 values('cg'),('ch'),('ci'),('lk'),('ll'),('lQuery OK, 6 rows affected (0.09 sec)Records: 6 Duplicates: 0 Warnings: 0
mysql> select * from t4;+------+| c |+------+| cg || ch || ci || lk || ll || lm |+------+6 rows in set (0.00 sec)mysql> select * from t4 order by c collate utf8_general_ci;该collation是把字符串拆开来进行排序的+------+| c |+------+| c g || c h || c i || lk || ll || lm |+------+6 rows in set (0.00 sec)
mysql> select * from t4 order by c collate utf8_spanish2_ci;他是将字符串的第一个字符作为排序规则的,不会考虑后面的字符的排列顺序+------+| c |+------+| c g || c i || c h || lk || lm || ll |+------+6 rows in set (0.00 sec)
5.3 正确设置客户端的连接字符集
- 如果客户端支持 --default-character-set 那么就可以在程序调用时候来设置字符集,myqsl就是这样的程序。也可以在配置文件中设置:
[mysql]
default-character-set=utf8
- 建立连接时,执行set names utf8 collation utf8_general_ci;
- 在一些编程接口里设置也可以:jdbc:mysql://localhost/mysql?characterEncoding=utf8
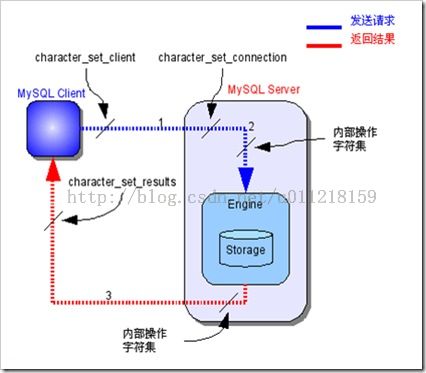
set names utf8就是改变以下三个变量:
character_set_client 客户端字符集
character_set_connection 客户端与服务器端连接采用的字符集
character_set_results 返回数据的字符集
character_set_client 客户端字符集
character_set_connection 客户端与服务器端连接采用的字符集
character_set_results 返回数据的字符集
mysql> show variables like 'character%';
+--------------------------+---------------------------------------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------------------------------------+
|1 character_set_client | gbk 注:客户端显示的格式,客户端到连接中 |
|2 character_set_connection | gbk 注:链接过程中传递的编码格式 |
|3 character_set_database | utf8 注:当前选中的数据库的默认编码格式 |
|4 character_set_filesystem | binary 注:文件系统存储的二进制字符格式 |
|5 character_set_results | gbk 注:返回的结果集编码格式 |
|6 character_set_server | utf8 注:默认的操作字符集格式 |
|7 character_set_system | utf8 注:系统元数据的编码格式 |
|8 character_sets_dir | C:\Program Files (x86)\MySQL\MySQL Server 5.5\share\charsets\ |
+--------------------------+---------------------------------------------------------------+
+--------------------------+---------------------------------------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------------------------------------+
|1 character_set_client | gbk 注:客户端显示的格式,客户端到连接中 |
|2 character_set_connection | gbk 注:链接过程中传递的编码格式 |
|3 character_set_database | utf8 注:当前选中的数据库的默认编码格式 |
|4 character_set_filesystem | binary 注:文件系统存储的二进制字符格式 |
|5 character_set_results | gbk 注:返回的结果集编码格式 |
|6 character_set_server | utf8 注:默认的操作字符集格式 |
|7 character_set_system | utf8 注:系统元数据的编码格式 |
|8 character_sets_dir | C:\Program Files (x86)\MySQL\MySQL Server 5.5\share\charsets\ |
+--------------------------+---------------------------------------------------------------+
default-character-set该配置选项相当于set names 也就是他控制着1,2,5的设置
character-set-server该配置选项 3,7被控制
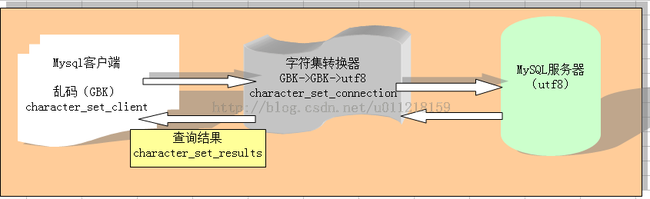
在
mysql客户端与
mysql服务端之间,存在着一个字符集转换器。
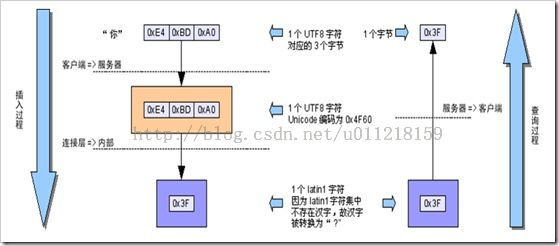
character_set_client =>gbk:转换器就知道客户端发送过来的是gbk格式的编码
character_set_connection=>gbk:将客户端传送过来的数据转换成gbk格式
character_set_results=>gbk:
•用introducer指定文本字符串的字符集:
– 格式为:[_charset] 'string' [COLLATE collation]
– 例如:
• SELECT _latin1 'string';
• SELECT _utf8 '你好' COLLATE utf8_general_ci;
– 由introducer修饰的文本字符串在请求过程中不经过多余的转码,直接转换为内部字符集处理。
MySQL中的字符集转换过程
1. MySQL Server收到请求时将请求数据从character_set_client转换为character_set_connection;
2. 进行内部操作前将请求数据从character_set_connection转换为内部操作字符集,

5.4 串字母
- 用单引号或双引号把字符串括起来:'aaa' ,"bbb"
- 使用十六进制数标记。每一对十六进制产生字节字符串。:abcd -> 0X61626364、X'61626364'、x'61626364'
- 通过使用一个字符集加下划线前缀组成的引入器,为用户字符串指定一个字符集作为解释器:_utf 'abcd'
引入器通知数据库服务器以何种方式解释后续的用户字符串。_latin1 'abcd'解释为含有四个单字节的字符串
- 使用双引号来标识含有单引号的字符串:select "I'm asleep" 反之 'He said : "boo!"'
- 使用与字符串内所包含的引号相同的引号来标识用户字符串,此时需要重复在字符串出现的引号或者在引号前添加\(\也是特殊字符,所以使用\添加到数据库用\\) 数据库处理时会自动移除他们。select 'I''m asleep' ,'I\'m asleep' select "He said, ""Bool""", "And I said,\" Yike!\""
5.5 检查一个字符串的字符集或字符排序
mysql>
select charset('aaa'),collation('bbb');
+----------------+------------------+
| charset('aaa') | collation('bbb') |
+----------------+------------------+
| utf8 | utf8_general_ci |
+----------------+------------------+
1 row in set (0.00 sec)
mysql> select charset(user()),collation(user());
+-----------------+-------------------+
| charset(user()) | collation(user()) |
+-----------------+-------------------+
| utf8 | utf8_general_ci |
+-----------------+-------------------+
1 row in set (0.00 sec)
mysql> set names gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> select charset('aaa'),collation('bbb');
+----------------+------------------+
| charset('aaa') | collation('bbb') |
+----------------+------------------+
| gbk | gbk_chinese_ci |
+----------------+------------------+
1 row in set (0.00 sec)
mysql> select charset(user()),collation(user());
+-----------------+-------------------+
| charset(user()) | collation(user()) |
+-----------------+-------------------+
| utf8 | utf8_general_ci |
+-----------------+-------------------+
1 row in set (0.00 sec)
mysql> select charset(md5('a')) ,collation(password('b'));
+-------------------+--------------------------+
| charset(md5('a')) | collation(password('b')) |
+-------------------+--------------------------+
| gbk | gbk_chinese_ci |
+-------------------+--------------------------+
1 row in set (0.00 sec)
mysql> select md5('a'), charset(md5('a')) ,collation(password('b'));
+----------------------------------+-------------------+--------------------------+
| md5('a') | charset(md5('a')) | collation(password('b')) |
+----------------------------------+-------------------+--------------------------+
| 0cc175b9c0f1b6a831c399e269772661 | gbk | gbk_chinese_ci |
+----------------------------------+-------------------+--------------------------+
1 row in set (0.00 sec)
5.6改变字符串的字符集和字符排序
使用convert() 和 collate
mysql> set @var = _utf8 'abcd';
Query OK, 0 rows affected (0.00 sec)
mysql> select charset(@var);
+---------------+
| charset(@var) |
+---------------+
| utf8 |
+---------------+
1 row in set (0.00 sec)
mysql> set @var = _gbk 'abcd';
Query OK, 0 rows affected (0.00 sec)
mysql> select charset(@var);
+---------------+
| charset(@var) |
+---------------+
| gbk |
+---------------+
1 row in set (0.00 sec)
mysql> set @s1 = 'is a String';
Query OK, 0 rows affected (0.00 sec)
mysql> set @s2 = convert('is a String' using utf8);
Query OK, 0 rows affected (0.00 sec)
mysql> select charset(@s1),charset(@s2),collation(@s1),collation(@s2);
+--------------+--------------+----------------+-----------------+
| charset(@s1) | charset(@s2) | collation(@s1) | collation(@s2) |
+--------------+--------------+----------------+-----------------+
| gbk | utf8 | gbk_chinese_ci | utf8_general_ci |
+--------------+--------------+----------------+-----------------+
1 row in set (0.00 sec)
mysql> set @s2 = @s2 collate latin1_spanish_ci;
ERROR 1253 (42000): COLLATION 'latin1_spanish_ci' is not valid for CHARACTER SET 'utf8'
Query OK, 0 rows affected (0.00 sec)
mysql> select charset(@var);
+---------------+
| charset(@var) |
+---------------+
| utf8 |
+---------------+
1 row in set (0.00 sec)
mysql> set @var = _gbk 'abcd';
Query OK, 0 rows affected (0.00 sec)
mysql> select charset(@var);
+---------------+
| charset(@var) |
+---------------+
| gbk |
+---------------+
1 row in set (0.00 sec)
mysql> set @s1 = 'is a String';
Query OK, 0 rows affected (0.00 sec)
mysql> set @s2 = convert('is a String' using utf8);
Query OK, 0 rows affected (0.00 sec)
mysql> select charset(@s1),charset(@s2),collation(@s1),collation(@s2);
+--------------+--------------+----------------+-----------------+
| charset(@s1) | charset(@s2) | collation(@s1) | collation(@s2) |
+--------------+--------------+----------------+-----------------+
| gbk | utf8 | gbk_chinese_ci | utf8_general_ci |
+--------------+--------------+----------------+-----------------+
1 row in set (0.00 sec)
mysql> set @s2 = @s2 collate latin1_spanish_ci;
ERROR 1253 (42000): COLLATION 'latin1_spanish_ci' is not valid for CHARACTER SET 'utf8'
注:说明先要把字符集转了,collation才能被转。
mysql> set @s2 =_latin1 'is a String';
Query OK, 0 rows affected (0.00 sec)
mysql> set @s2 = @s2 collate latin1_spanish_ci;
Query OK, 0 rows affected (0.00 sec)
mysql> select charset(@s2),collation(@s2);
+--------------+-------------------+
| charset(@s2) | collation(@s2) |
+--------------+-------------------+
| latin1 | latin1_spanish_ci |
+--------------+-------------------+
1 row in set (0.00 sec)
mysql> set @s3 = 'is a Stirng';
Query OK, 0 rows affected (0.00 sec)
mysql> set @s4 = convert(@s3 using binary);
Query OK, 0 rows affected (0.00 sec)
mysql> set @s5 = convert(@s4 using gbk);
Query OK, 0 rows affected (0.00 sec)
mysql> set @s6 = binary @s3;
Query OK, 0 rows affected (0.03 sec)
mysql> set @s2 =_latin1 'is a String';
Query OK, 0 rows affected (0.00 sec)
mysql> set @s2 = @s2 collate latin1_spanish_ci;
Query OK, 0 rows affected (0.00 sec)
mysql> select charset(@s2),collation(@s2);
+--------------+-------------------+
| charset(@s2) | collation(@s2) |
+--------------+-------------------+
| latin1 | latin1_spanish_ci |
+--------------+-------------------+
1 row in set (0.00 sec)
mysql> set @s3 = 'is a Stirng';
Query OK, 0 rows affected (0.00 sec)
mysql> set @s4 = convert(@s3 using binary);
Query OK, 0 rows affected (0.00 sec)
mysql> set @s5 = convert(@s4 using gbk);
Query OK, 0 rows affected (0.00 sec)
mysql> set @s6 = binary @s3;
Query OK, 0 rows affected (0.03 sec)
mysql> select charset(@s3),charset(@s4),charset(@s5),charset(@s6);
+--------------+--------------+--------------+--------------+
| charset(@s3) | charset(@s4) | charset(@s5) | charset(@s6) |
+--------------+--------------+--------------+--------------+
| gbk | binary | gbk | binary |
+--------------+--------------+--------------+--------------+
1 row in set (0.00 sec)
mysql>
5.7改变字母的大小写
upper() 和 lower()
mysql> set @str = 'AbCdEfGh';
Query OK, 0 rows affected (0.00 sec)
mysql> select concat(lower( left(@str,1)),upper( mid(@str,2)));//mid相当于subString
Query OK, 0 rows affected (0.00 sec)
mysql> select concat(lower( left(@str,1)),upper( mid(@str,2)));//mid相当于subString
+------------------------------------------------+
| concat(lower(left(@str,1)),upper(mid(@str,2))) |
+------------------------------------------------+
| aBCDEFGH |
+------------------------------------------------+
| concat(lower(left(@str,1)),upper(mid(@str,2))) |
+------------------------------------------------+
| aBCDEFGH |
+------------------------------------------------+
5.8 更改大小写失败的情况
- 当一个字符串是二进制字符串就不能进行大小转换,只能先转为非二进制,再大小转换mysql> create table tab1 select binary 'abcd' as 'b';
Query OK, 1 row affected (0.26 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> select * from tab1;
+------+
| b |
+------+
| abcd |
+------+
1 row in set (0.00 sec)
mysql> select charset(b) from tab1;
+------------+
| charset(b) |
+------------+
| binary |
+------------+
1 row in set (0.00 sec)
mysql> select concat(upper(left(b,2)),mid(b,3)) from tab1;
+-----------------------------------+
| concat(upper(left(b,2)),mid(b,3)) |
+-----------------------------------+
| abcd |
+-----------------------------------+
1 row in set (0.00 sec)
mysql> select concat(upper(left(convert(b using utf8),2)),mid(b,3)) from tab1;
+-------------------------------------------------------+
| concat(upper(left(convert(b using utf8),2)),mid(b,3)) |
+-------------------------------------------------------+
| ABcd |
+-------------------------------------------------------+
1 row in set (0.00 sec)
mysql>
5.9 控制字符串的大小写敏感
首先纠正一点:字符串也是有比较的,他也是可以进行排序的
字符串的排序比较分为两种:
- 二进制串排序
定义:他们是以字节为单位的,他们的比较是基于每个字节的数值,所以他是属于大小写敏感的排序原则,
假如需求是进行大小写不敏感的排序规则那么就先将二进制转为非二进制的字符,再选用非二进制不敏感的collation进行排序就可以了
- 非二进制排序
定义: 他们是基于每个字符的,非二进制是通过字符集来判断字符是否有效,再通过字符集规定的collation来进行排序规则
在非二进制字符串采用的默认字符集排序是不区分大小写的,在不区分大小写敏感的情况下是相等的。
mysql> select @s1 = @s2;
+-----------+
| @s1 = @s2 |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
mysql> select @s1 collate utf8_general_ci = @s2 collate utf8_general_ci;
+-----------------------------------------------------------+
| @s1 collate utf8_general_ci = @s2 collate utf8_general_ci |
+-----------------------------------------------------------+
| 1 |
+-----------------------------------------------------------+
1 row in set (0.00 sec)
mysql> show collation like 'utf8%';
+--------------------------+---------+-----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------------+---------+-----+---------+----------+---------+
| utf8_general_ci | utf8 | 33 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | | Yes | 1 |
| utf8_unicode_ci | utf8 | 192 | | Yes | 8 |
...............
mysql> set @s1 = convert(@s1 using latin1),@s2 = convert(@s2 using latin1);
Query OK, 0 rows affected (0.00 sec)
mysql> select @s1 = @s2;
+-----------+
| @s1 = @s2 |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
mysql> select @s1 collate latin1_general_cs = @s2 collate latin1_general_cs
+---------------------------------------------------------------+
| @s1 collate latin1_general_cs = @s2 collate latin1_general_cs |
+---------------------------------------------------------------+
| 0 |
+---------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> select @s1 = binary @s2;// 如果将一个二进制和一个非二进制的字符串进行比较那么他们都将会转为二进制的形式进行比较,所以要进行二进制比较的话并不需要两边同时都转为二进制进行比较的,只需要一边就可以了。
+-------------------+
| @s1 = binary @s2 |
+-------------------+
| 0 |
+-------------------+
1 row in set (0.00 sec)
+-----------+
| @s1 = @s2 |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
mysql> select @s1 collate utf8_general_ci = @s2 collate utf8_general_ci;
+-----------------------------------------------------------+
| @s1 collate utf8_general_ci = @s2 collate utf8_general_ci |
+-----------------------------------------------------------+
| 1 |
+-----------------------------------------------------------+
1 row in set (0.00 sec)
mysql> show collation like 'utf8%';
+--------------------------+---------+-----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------------+---------+-----+---------+----------+---------+
| utf8_general_ci | utf8 | 33 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | | Yes | 1 |
| utf8_unicode_ci | utf8 | 192 | | Yes | 8 |
...............
mysql> set @s1 = convert(@s1 using latin1),@s2 = convert(@s2 using latin1);
Query OK, 0 rows affected (0.00 sec)
mysql> select @s1 = @s2;
+-----------+
| @s1 = @s2 |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
mysql> select @s1 collate latin1_general_cs = @s2 collate latin1_general_cs
+---------------------------------------------------------------+
| @s1 collate latin1_general_cs = @s2 collate latin1_general_cs |
+---------------------------------------------------------------+
| 0 |
+---------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> select @s1 = binary @s2;// 如果将一个二进制和一个非二进制的字符串进行比较那么他们都将会转为二进制的形式进行比较,所以要进行二进制比较的话并不需要两边同时都转为二进制进行比较的,只需要一边就可以了。
+-------------------+
| @s1 = binary @s2 |
+-------------------+
| 0 |
+-------------------+
1 row in set (0.00 sec)
修改表中字段的信息:alter table tal1 modify colomn1 数据类型 character set 字符集 collation;
5.10 使用sql模式进行模式匹配
mysql中的模式匹配所使用的操作符:like , not like
mysql中的模式匹配所使用的匹配符:_ , %
- 注:不是是like操作符还是 not like 操作符,sql模式匹配与null值的匹配始终是 null;
mysql> select null like '%' ,null not like '%',null like '_';
+---------------+-------------------+---------------+| null like '%' | null not like '%' | null like '_' |+---------------+-------------------+---------------+| NULL | NULL | NULL |+---------------+-------------------+---------------+1 row in set (0.03 sec)
- 注: 对于非字符串值进行模式匹配
和其他的数据库不同的是,mysql支持对非字符串值进行模式模式匹配,列入数值类型(number)和日期类型date:
mysql> select 123 like '123%',now() like '2014-%';
+-----------------+---------------------+| 123 like '123%' | now() like '2014-%' |+-----------------+---------------------+| 1 | 1 |+-----------------+---------------------+1 row in set, 1 warning (0.06 sec)
- 注:在某些情况下,字符串匹配在和子串比较是等价的:
mysql> set @var := 'abcdef';Query OK, 0 rows affected (0.00 sec)
mysql> select @var like 'abc%',left(@var,3) = 'abc';+------------------+----------------------+| @var like 'abc%' | left(@var,3) = 'abc' |+------------------+----------------------+| 1 | 1 |+------------------+----------------------+1 row in set (0.03 sec)
- 通过上面的测试,你会发现他们达到了同一样的效果,但是他们是有区别的:
mysql 对于以字符串开始的模式,能使用索引来缩小搜索范围,而left,mid,right等是不会使用索引进行操作的。
5.11 使用正则表达式进行模式匹配
- 以特定字符开头的:select * from tab1 where column1 regexp '^字符串';
- 一特定的字符结尾的:select * from tab1 where column1 regexp '字符串$';
- 含有特定的字符串:select * from tab1 where colimn1 regexp '字符串';
- 使用[]定义一个字符集进行匹配:select * from tab1 where columns regexp ’[abc]‘;
- 使用-定义一个字符集批撇:select * from tab1 where columns regexp ‘[a-z0-9]’;
- 也可以使用POSIX字符集定义正则表达式:
- [:alnum:]:字符和数字;[:alpha:]:字母;[:blank:]:空格或者制表符....很多
- mysql> select name ,name regexp '[[:xdigit:]]' from test4;//用来匹配那么列中是否有含有十六进制的字符(0-9,a-f,A-F)
+------+----------------------------+
| name | name regexp '[[:xdigit:]]' |
+------+----------------------------+
| bbb | 1 |
| bbb | 1 |
| aaa | 1 |
| aaa | 1 |
| bbb | 1 |
+------+----------------------------+
5 rows in set (0.00 sec) - 定义选择性匹配:
- mysql> select name ,addr,addr regexp '^[jaa]|i$'from tab1//表示:以[jaa]开头的字符串或者以i结尾的字符串
- +------+----------+-------------------------+
| name | addr | addr regexp '^[jaa]|i$' |
+------+----------+-------------------------+
|aaa | jiangxi | 1 |
| bbb | beijing | 0 |
| ccc | shanghai | 1 |
| abc | sichuan | 0 |
| eee | hunan | 0 |
| ddd | nanjing | 0 |
+------+----------+-------------------------+
mysql> select name ,addr,addr regexp '^([jaa]|i)$'from tab1;//表示:要么是[jaa]中的一个字符并且是一[jaa]中的某个字符串开头的,要么是i字符串并且是一i字符串结尾的;+------+----------+---------------------------+| name | addr | addr regexp '^([jaa]|i)$' |+------+----------+---------------------------+| aaa | jiangxi | 0 || bbb | beijing | 0 || ccc | shanghai | 0 || abc | sichuan | 0 || eee | hunan | 0 || ddd | nanjing | 0 |+------+----------+---------------------------+
mysql> select name ,addr,addr regexp '^([ab]eijing|m+)$'from tab1;
+------+----------+---------------------------------+
| name | addr | addr regexp '^([ab]eijing|m+)$' |
+------+----------+---------------------------------+
| aaa | jiangxi | 0 |
| bbb | beijing | 1 |
| ccc | shanghai | 0 |
| abc | sichuan | 0 |
| eee | hunan | 0 |
| ddd | nanjing | 0 |
+------+----------+---------------------------------+
6 rows in set (0.00 sec)
mysql> select name ,addr,addr regexp '^([ab]eijing|nanjing+)$'from tab1;
+------+----------+---------------------------------------+
| name | addr | addr regexp '^([ab]eijing|nanjing+)$' |
+------+----------+---------------------------------------+
| aaa | jiangxi | 0 |
| bbb | beijing | 1 |
| ccc | shanghai | 0 |
| abc | sichuan | 0 |
| eee | hunan | 0 |
| ddd | nanjing | 1 |
+------+----------+---------------------------------------+
+------+----------+---------------------------------+
| name | addr | addr regexp '^([ab]eijing|m+)$' |
+------+----------+---------------------------------+
| aaa | jiangxi | 0 |
| bbb | beijing | 1 |
| ccc | shanghai | 0 |
| abc | sichuan | 0 |
| eee | hunan | 0 |
| ddd | nanjing | 0 |
+------+----------+---------------------------------+
6 rows in set (0.00 sec)
mysql> select name ,addr,addr regexp '^([ab]eijing|nanjing+)$'from tab1;
+------+----------+---------------------------------------+
| name | addr | addr regexp '^([ab]eijing|nanjing+)$' |
+------+----------+---------------------------------------+
| aaa | jiangxi | 0 |
| bbb | beijing | 1 |
| ccc | shanghai | 0 |
| abc | sichuan | 0 |
| eee | hunan | 0 |
| ddd | nanjing | 1 |
+------+----------+---------------------------------------+
- null与任何匹配或者不匹配都会是null
mysql> select null regexp '.*',null not regexp '.*';+------------------+----------------------+| null regexp '.*' | null not regexp '.*' |+------------------+----------------------+| NULL | NULL |+------------------+----------------------+
- 结论:如果一个字符串含有正则表达式所能匹配的任意子串,那么他们就是匹配的。因此要特别的注意皮面能够与空串匹配的正则表达式,否则他将匹配除了Null以外的所有字符串匹配。例如:a*,有些时候正则匹配也等同于子串直接比较,正则的^-> LEFT() $->RIGHT();
但是有些是不能实现的:str regexp '^[0-9]+'
- 提示:正则表达式与sql模式匹配相比有些不足:正则表达式只能针对于单字节字符集,对于utf8、sjis这样的双字节是不能发挥作用的(测试好像也支持,可能是版本的原因)
5.12 匹配模式的大小写问题
字符串是否是二进制,是否支持大小
写,都会决定字符串模式匹配过程是否大小写铭感。
mysql> set @str1 = 'aBc';//utf-8
Query OK, 0 rows affected (0.00 sec)
mysql> select convert(@str1 using latin1) ='abc',convert(@str1 using latin1) collate latin1_general_cs= 'abc';//该collation是支持大小写的
+------------------------------------+---------------------------------------------------------------+
| convert(@str1 using latin1) ='abc' | convert(@str1 using latin1) collate latin1_general_cs = 'abc' |
+------------------------------------+---------------------------------------------------------------+
| 1 | 0 |
+------------------------------------+---------------------------------------------------------------+
Query OK, 0 rows affected (0.00 sec)
mysql> select convert(@str1 using latin1) ='abc',convert(@str1 using latin1) collate latin1_general_cs= 'abc';//该collation是支持大小写的
+------------------------------------+---------------------------------------------------------------+
| convert(@str1 using latin1) ='abc' | convert(@str1 using latin1) collate latin1_general_cs = 'abc' |
+------------------------------------+---------------------------------------------------------------+
| 1 | 0 |
+------------------------------------+---------------------------------------------------------------+
mysql> select @str1 like 'abc', @str1 collate latin1_general_cs like 'abc',@str1 regexp 'abc',@str1 collate latin1_general_cs regexp 'abc';
+------------------+--------------------------------------------+--------------------+----------------------------------------------+
| @str1 like 'abc' | @str1 collate latin1_general_cs like 'abc' | @str1 regexp 'abc' | @str1 collate latin1_general_cs regexp 'abc' |
+------------------+--------------------------------------------+--------------------+----------------------------------------------+
| 1 | 0 | 1 | 0 |
+------------------+--------------------------------------------+--------------------+----------------------------------------------+
+------------------+--------------------------------------------+--------------------+----------------------------------------------+
| @str1 like 'abc' | @str1 collate latin1_general_cs like 'abc' | @str1 regexp 'abc' | @str1 collate latin1_general_cs regexp 'abc' |
+------------------+--------------------------------------------+--------------------+----------------------------------------------+
| 1 | 0 | 1 | 0 |
+------------------+--------------------------------------------+--------------------+----------------------------------------------+
5.13 分割或者串联字符串
使用subString-extraction函数获得子串,使用concat函数连接字符串
mysql> select addr, left(addr,3),right(addr,2),mid(addr,2,2),subSTring(addr,3),subString_INDEX(addr,'j',1),subString_index(addr,'i',-1) from tab1
+----------+--------------+---------------+---------------+-------------------+-----------------------------+------------------------------+
| addr | left(addr,3) | right(addr,2) | mid(addr,2,2) | subSTring(addr,3)| subString_INDEX(addr,'j',1) | subString_index(addr,'i', -1) |
+----------+--------------+---------------+---------------+-------------------+-----------------------------+------------------------------+
| jiangxi | jia | xi | ia | angxi | | |
| beijing | bei | ng | ei | ijing | bei | ng |
| shanghai | sha | ai | ha | anghai | shanghai | |
| sichuan | sic | an | ic | chuan | sichuan | chuan |
| hunan | hun | an | un | nan | hunan | hunan |
| nanjing | nan | ng | an | njing | nan | ng |
+----------+--------------+---------------+---------------+-------------------+-----------------------------+------------------------------+
6 rows in set (0.00 sec)
+----------+--------------+---------------+---------------+-------------------+-----------------------------+------------------------------+
| addr | left(addr,3) | right(addr,2) | mid(addr,2,2) | subSTring(addr,3)| subString_INDEX(addr,'j',1) | subString_index(addr,'i', -1) |
+----------+--------------+---------------+---------------+-------------------+-----------------------------+------------------------------+
| jiangxi | jia | xi | ia | angxi | | |
| beijing | bei | ng | ei | ijing | bei | ng |
| shanghai | sha | ai | ha | anghai | shanghai | |
| sichuan | sic | an | ic | chuan | sichuan | chuan |
| hunan | hun | an | un | nan | hunan | hunan |
| nanjing | nan | ng | an | njing | nan | ng |
+----------+--------------+---------------+---------------+-------------------+-----------------------------+------------------------------+
6 rows in set (0.00 sec)
- mid当取出最后一个参数时和subString是一个意思
- subString_index(str,c,index):c表示出现的字符,index表示出现的次数,当为负数时表示从右边出现的次数//该函数是支持大小写敏感的
mysql> select addr ,concat('zhongguo','-',addr) from tab1;
+----------+-----------------------------+
| addr | concat('zhongguo','-',addr) |
+----------+-----------------------------+
| jiangxi | zhongguo-jiangxi |
| beijing | zhongguo-beijing |
| shanghai | zhongguo-shanghai |
| sichuan | zhongguo-sichuan |
| hunan | zhongguo-hunan |
| nanjing | zhongguo-nanjing |
+----------+-----------------------------+
6 rows in set (0.00 sec)
+----------+-----------------------------+
| addr | concat('zhongguo','-',addr) |
+----------+-----------------------------+
| jiangxi | zhongguo-jiangxi |
| beijing | zhongguo-beijing |
| shanghai | zhongguo-shanghai |
| sichuan | zhongguo-sichuan |
| hunan | zhongguo-hunan |
| nanjing | zhongguo-nanjing |
+----------+-----------------------------+
6 rows in set (0.00 sec)
5.14查询子串
使用locatemysql> select addr, locate('j',addr),locate( 'h',addr) from tab1;
+----------+------------------+-------------------+
| addr | locate('j',addr) | locate( 'h',addr) |
+----------+------------------+-------------------+
| jiangxi | 1 | 0 |
| beijing | 4 | 0 |
| shanghai | 0 | 2 |
| sichuan | 0 | 4 |
| hunan | 0 | 1 |
| nanjing | 4 | 0 |
+----------+------------------+-------------------+
5.15使用fulltext进行查询
如何对大量的文本进行查询,需要使用fulltext索引
mysql> explain select * from tab3 where addr like 'beiji%';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab3 | ALL | addr | NULL | NULL | NULL | 6 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from tab3 where name like 'a%'
-> ;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab3 | ALL | NULL | NULL | NULL | NULL | 6 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from tab3 where name like 'a%' and addr like 'beij%';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab3 | ALL | addr | NULL | NULL | NULL | 6 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from tab3 where name like 'a%' and addr like '%beij%';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab3 | ALL | NULL | NULL | NULL | NULL | 6 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from tab3 where match(addr) against('a');
ERROR 1191 (HY000): Can't find FULLTEXT index matching the column list
mysql> explain select * from tab3 where match(name) against('a');
ERROR 1191 (HY000): Can't find FULLTEXT index matching the column list
mysql> explain select * from tab3 where match(name,addr) against('a');
+----+-------------+-------+----------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+----------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab3 | fulltext | addr | addr | 0 | | 1 | Using where |
+----+-------------+-------+----------+---------------+------+---------+------+------+-------------+
1 row in set (0.02 sec)
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab3 | ALL | addr | NULL | NULL | NULL | 6 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from tab3 where name like 'a%'
-> ;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab3 | ALL | NULL | NULL | NULL | NULL | 6 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from tab3 where name like 'a%' and addr like 'beij%';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab3 | ALL | addr | NULL | NULL | NULL | 6 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from tab3 where name like 'a%' and addr like '%beij%';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab3 | ALL | NULL | NULL | NULL | NULL | 6 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from tab3 where match(addr) against('a');
ERROR 1191 (HY000): Can't find FULLTEXT index matching the column list
mysql> explain select * from tab3 where match(name) against('a');
ERROR 1191 (HY000): Can't find FULLTEXT index matching the column list
mysql> explain select * from tab3 where match(name,addr) against('a');
+----+-------------+-------+----------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+----------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab3 | fulltext | addr | addr | 0 | | 1 | Using where |
+----+-------------+-------+----------+---------------+------+---------+------+------+-------------+
1 row in set (0.02 sec)
通过上面的测试得出下面的结论:
- 第一块有色字,你会发现只有使用了addr才会适应索引,因为规定假如复合索引被建立时,只有使用了复合列的至少是第一列才会使用到索引效果,使用like 匹配符不能是'%/_开头的'
- 第二块有色字,结论是,复合索引在使用match时,match(column1,column2)中的列必须完全和创建符合索引的顺序一致。不是表中列的顺序
- fulltext搜索对于停词是不使用索引的
5.16 用短语进行fulltext查询:
fulltext搜索对端的查询词语无效
mysql> select * from tab3 where match(name,addr) against('aaa');
Empty set (0.00 sec)
其实上面的表是有aaa的但是查询不出来,为什么呢?
解释:在搜索引擎中存在这样的特性:搜索引擎会忽略太常见的词(就是一般以上上的行中出现的词)
但是下面的现象:mysql> select count(*) , count(if(addr like '%b%',1,null))from tab3;
+----------+-----------------------------------+| count(*) | count(if(addr like '%b%',1,null)) |+----------+-----------------------------------+| 6 | 1 |+----------+-----------------------------------+1 row in set (0.00 sec)
你会发现并没有太常出现啊,其实搜索引擎还有一个配置默认情况下搜索引擎不会将少于4个词的建立搜索关键字
通过配置:ft_min_word_len的长度来设置。
重建索引:repair table tab1 quick;
5.17 要求或者禁止fulltext的模式匹配
因为在fulltext查询返回含有查询字符串中任意单词的行,甚至允许不包括某些单词:
select * from tab1 where match(col1[,col2..]) agianst('word1 word2 ..');
select * from tab1 where match(col1[,col2..]) agianst('word1') andmatch(col2) agianst('word2');
上面的两句sql并不是等价的,上面只有存在其中一个就可以,而下面要同时成立才可以
其实可以有更简便的方式:
符号代表,需要该单词还是排除该单词;还有一个特殊的
在*
单词后面充当通配符使用
select * from tab1 where match(col1[,col2]) against('+
word1+
word2' in boolean mode);
5.18 用fulltext索引来执行词组查询
怎样查询一组单词而且是需要按顺序出现的查询
select * from tab1 where match(col) agianst('how are you ');//这样并不会达到预期的效果,查出来的是只有存在其中任一的单词的语句都算
select * from tab1 where match(col) agianst('"how are you '");//这样才正确