Arch-03-14-缓存策略
Arch-03-14-缓存策略
robin(有人谓肉饼,太有才了)的一文很强悍,摘在这儿做个灯引。
http://robbin.iteye.com/blog/770553
数据库缓存
--Query Cache
--Data Buffer
应用程序缓存
--对象缓存
--查询缓存
页面内部缓存
--动态页面静态化
--Servlet缓存
Web服务器缓存
--squid/nginx
--CDN
客户端浏览器缓存
--AJAX缓存
--基于HTTP协议的资源缓存
如果是查询Cache,自然是DAO层处理;
如果是Action Cache,自然是Web 层Action处理;
如果是Page Cache,自然是Servlet Filter处理;
用 ibatis + memcached 的策略明显有缺陷,粒度太大,考虑用更小粒度高效的方案吧。
听起来 hibernate 的缓存不错,原理很好,之前的项目一直是类似机制,只不过用的是自己实现的 simpleJdbc. 现在需要在 ibatis 的基础上实现细粒度缓存,好象没那么简单。
=================================================
1. Voldemort (伏地魔)
- 一致性
- 可插拔
- 独立
- 一个强大的Java客户端,支持可插拔的序列化
- 可整合
public MessageBean getByID(long id)
throws MessageNotFoundException, DAOException
{
MessageBean bean = null;
Connection con = getConnection();
PreparedStatement pstmt = null;
ResultSet rs = null;
try
{
// load message row
pstmt = con.prepareStatement("SELECT pMessageID, ownerID, senderID, recipientID, subject, body, readStatus, folderID, pMessageDate, status, creationDate, sentDate FROM message WHERE pMessageID = ?");
pstmt.setLong(1, id);
rs = pstmt.executeQuery();
if (!rs.next()) {
throw new MessageNotFoundException("Message " + id + " could not be loaded from the database.");
}
bean = read(rs, new MessageBean());
rs.close();
pstmt.close();
// load message properties rows
Map p = new HashMap();
pstmt = con.prepareStatement("SELECT name, propValue FROM MessageProp WHERE pMessageID=?");
pstmt.setLong(1, id);
rs = pstmt.executeQuery();
while (rs.next())
{
p.put(rs.getString(1), rs.getString(2));
}
bean.setProperties(p);
rs.close();
pstmt.close();
// load message attachment IDs
LongList attachmentList = new LongList();
try
{
pstmt = con.prepareStatement("SELECT attachmentID FROM attachment WHERE objectType=5 AND objectID=?");
pstmt.setLong(1, bean.getID());
rs = pstmt.executeQuery();
while (rs.next()) {
attachmentList.add(rs.getLong(1));
}
bean.setAttachments(attachmentList);
}
catch (SQLException sqle) {
Log.error(sqle);
}
finally {
ConnectionManager.close(rs, pstmt);
}
}
catch (SQLException sqle) {
throw new MessageNotFoundException("Message with id " + id + " could not be loaded from the database.");
}
catch (NumberFormatException nfe)
{
throw new MessageNotFoundException("Message with id " + id + " could not be loaded from the database.");
}
finally
{
ConnectionManager.close(rs, pstmt);
releaseConnection(con);
}
return bean;
}
#!/bin/bash/voldemort-service.sh # # Copyright 2008-2009 LinkedIn, Inc # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # if [ $# -gt 1 ]; then echo 'USAGE: bin/voldemort-server.sh [voldemort_home]' exit 1 fi base_dir=$(dirname $0)/.. for file in $base_dir/dist/*.jar; do CLASSPATH=$CLASSPATH:$file done for file in $base_dir/lib/*.jar; do CLASSPATH=$CLASSPATH:$file done for file in $base_dir/contrib/*/lib/*.jar; do CLASSPATH=$CLASSPATH:$file done CLASSPATH=$CLASSPATH:$base_dir/dist/resources if [ -z "$VOLD_OPTS" ]; then VOLD_OPTS="\ -Xmx2G -server \ -Dcom.sun.management.jmxremote \ -Dcom.sun.management.jmxremote.port=6650 \ -Dcom.sun.management.jmxremote.ssl=false \ -Dcom.sun.management.jmxremote.authenticate=false" fi java -Dlog4j.configuration=log4j.properties $VOLD_OPTS -cp $CLASSPATH voldemort.server.VoldemortServer $@
<!--cluster.xml-->
<cluster>
<name>pluscluster</name>
<server>
<id>0</id>
<host>127.0.0.1</host>
<http-port>8071</http-port>
<socket-port>6666</socket-port>
<admin-port>6667</admin-port>
<partitions>0,1,2,3,4,5,6,7
</partitions>
</server>
</cluster>
node.id=0 max.threads=100 ############### DB options ###################### http.enable=false socket.enable=true jmx.enable=true storage.configs=voldemort.store.bdb.BdbStorageConfiguration,voldemort.store.memory.InMemoryStorageConfiguration,voldemort.store.memory.CacheStorageConfiguration slop.store.engine=memory # NIO connector settings. enable.nio.connector=true enable.nio.admin.connector=false # don't throttle admin client - set to a really high value stream.read.byte.per.sec=1000000000000 stream.write.byte.per.sec=1000000000000 # default buffer size is 10MB. We'll turn it down to 512KB admin.streams.buffer.size=524288 # use only 8 selectors (for nio) nio.connector.selectors=8 nio.admin.connector.selectors=8
4. 应用架构基于共享 Voldemort 缓存,利用 JGroup 传送消息的应用集群,讲起来有一匹布那么长,暂且略过,隔几天画个图上来。

5. 启动 JMX 监控
开启一个Jconsole 本地连接

6. 缓存性能优化之道
(1)客户端资源缓存
HTTPD server - “cache.conf.rpmnew”
(2)服务端页缓存
HTTP header in the response to Cache-Control max-age=3600.
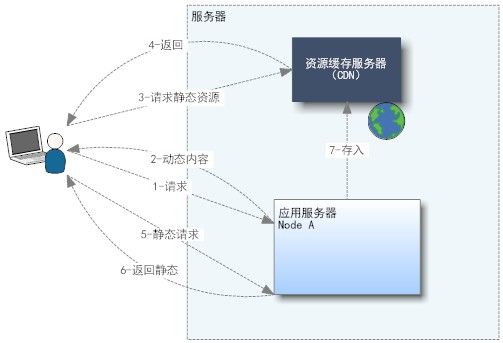
(3)配置外部 CDN 缓存服务器
. 安装 CDN 缓存服务器 . 基于 URL . 服务器端生成页面时,重写静态资源地址指向 CDN URL . 当完成页面请求后,客户端使用 CDN URL 返回资源 . 如果 CDN 命中,直接返回客户端,否则,从应用服务器返回并存入 CDN,备用。
(4)调整虚拟机参数
JVM_HEAP_MAX=4096 JVM_HEAP_MIN=4096
7. 动手搭建山寨 CDN
参考原文 http://blog.csdn.net/jackem/article/details/3206440
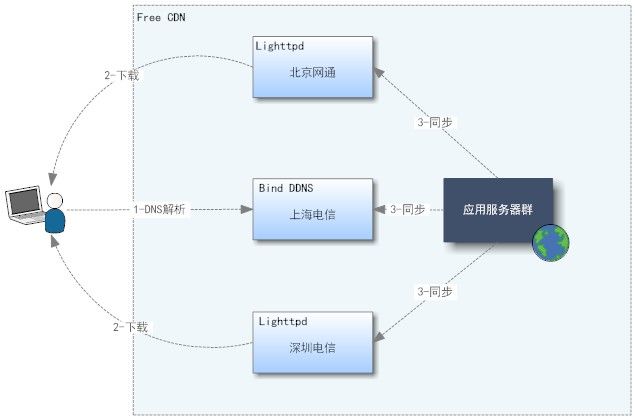
目前对于 CDN 网络搭建技术有很多成熟的商业方案,对于资金受限的网站可能无法自己搭建或购买。这里提供了一套简单的实现CDN网络的技术架构,所使用的软件全部是开源高效且免费的。根据CDN网络技术原理,必须有一个动态DNS服务器,开源的可以使用bind,免费开源。不修改代码,bind 基本上可以实现简单的动态DNS解析功能。需要更强的自定义功能,可以自己修改代码实现。
(1)假设web站点部署在上海电信。
(2)在上海电信部署Bind,提供动态解析服务,在上海电信部署主Web站点;
(3)在全国各地找几个比较重要的机房部署 lighttpd 服务器提供静态资源下载,如北京网通,广州电信两个机房各放置2台服务器,安装上 lighttpd+mod_cache+mod_proxy 等;
(4)配置子下载服务器的 lighttpd 的 modCache 功能,并设置 proxy.server 为主站点上海机房IP。
(5)当北京网通用户访问主站的静态文件时,通过动态DNS解析得到北京网通机房服务器的IP地址,浏览器就从北京网通服务器上下载文件了,提高了响应速度,同时降低了主站的压力。
这样一个简单的技术架构已经完成。对于 lighttpd+modCache 的详细配置参考http://www.linux.com.cn/modcache/。
<bean id="usersCache" parent="cacheBean" depends-on="cacheFactoryManager">
<constructor-arg value="Users" />
<property name="type" ref="local"/>
<!-- in milliseconds, 24 hours, checked every hour -->
<property name="expirationTime" value="86400000"/>
<property name="expirationPeriod" value="3600000"/>
<property name="transactional" value="false"/>
<property name="keyRetrieval" value="false"/>
<property name="type" value="false"/>
<property name="timeoutTime" value="60"/>
<property name="timeUnit" value="false"/>
<property name="additionalProperties" value="Map<String, String>"/>
<property name="valueSerializer" value="false"/>
<property name="disableEviction" value="false"/>
<property name="prefixAware" value="false"/>
<property name="maxCacheSize" value="10g"/>
<sizeLimit
</bean>