Google我想大家应该都用过,输入我们的搜索关键字,然后回车,Google就会返回搜索结果,在返回的界面里,会对命中的关键字进行红色字体标注出来,这就是高亮功能。
Lucene5中高亮功能相关API都在org.apache.lucene.search.highlight包下,我们先从简单的高亮器开始即Highlighter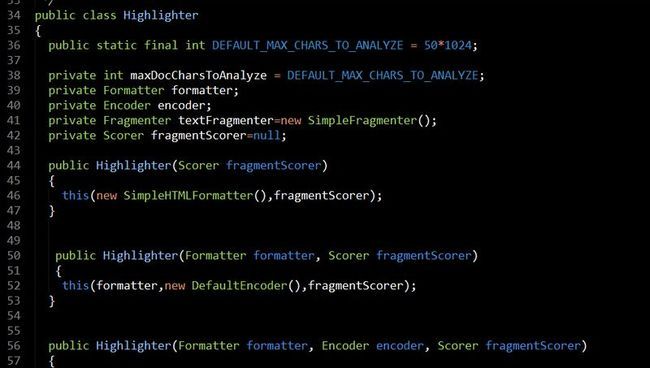
透过Hightlighter类的源码,我们首先需要去了解里面的每个成员变量的含义:
public static final int DEFAULT_MAX_CHARS_TO_ANALYZE = 50*1024; private int maxDocCharsToAnalyze = DEFAULT_MAX_CHARS_TO_ANALYZE; private Formatter formatter; private Encoder encoder; private Fragmenter textFragmenter=new SimpleFragmenter(); private Scorer fragmentScorer=null;
formatter:高亮的格式化器,即使用什么标签来高亮。默认是<B></B>
Encoder:编码器,比如返回的高亮片段里面包含了特殊字符,比如< > & "等等,如果你需要进行转义,则 需要指定一个编码器
Scorer:是用来为每个命中的Frag进行打分的
Fragmenter:即拆分器,把原始文本拆分成一个个高亮片段。
DEFAULT_MAX_CHARS_TO_ANALYZE:设置了当前高亮器可以处理的最大字符个数
下面是一些高亮器的简单使用示例:
package com.yida.framework.lucene5.hightlight;
import java.io.IOException;
import java.util.Arrays;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Token;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queries.CommonTermsQuery;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.MultiTermQuery;
import org.apache.lucene.search.PhraseQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.QueryWrapperFilter;
import org.apache.lucene.search.RegexpQuery;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TermRangeQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.WildcardQuery;
import org.apache.lucene.search.highlight.Formatter;
import org.apache.lucene.search.highlight.Fragmenter;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.QueryTermScorer;
import org.apache.lucene.search.highlight.Scorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLEncoder;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.search.highlight.SimpleSpanFragmenter;
import org.apache.lucene.search.highlight.TokenSources;
import org.apache.lucene.search.join.BitDocIdSetCachingWrapperFilter;
import org.apache.lucene.search.join.BitDocIdSetFilter;
import org.apache.lucene.search.join.ScoreMode;
import org.apache.lucene.search.join.ToParentBlockJoinQuery;
import org.apache.lucene.search.spans.SpanNearQuery;
import org.apache.lucene.search.spans.SpanQuery;
import org.apache.lucene.search.spans.SpanTermQuery;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
import org.apache.lucene.util.BytesRef;
/**
* 高亮简单测试
*
* @author Lanxiaowei
*
*/
public class SimpleHightlightTest {
final int QUERY = 0;
final int QUERY_TERM = 1;
final String FIELD_NAME = "contents";
private static final String NUMERIC_FIELD_NAME = "nfield";
private Directory ramDir = new RAMDirectory();
private Analyzer analyzer = new StandardAnalyzer();
int numHighlights = 0;
TopDocs hits;
int mode = QUERY;
Fragmenter frag = new SimpleFragmenter(20);
final FieldType FIELD_TYPE_TV;
{
FieldType fieldType = new FieldType(TextField.TYPE_STORED);
fieldType.setStoreTermVectors(true);
fieldType.setStoreTermVectorPositions(true);
fieldType.setStoreTermVectorPayloads(true);
fieldType.setStoreTermVectorOffsets(true);
fieldType.freeze();
FIELD_TYPE_TV = fieldType;
}
String[] texts = {
"Hello this is a piece of text that is very long and contains too much preamble and the meat is really here which says kennedy has been shot",
"This piece of text refers to Kennedy at the beginning then has a longer piece of text that is very long in the middle and finally ends with another reference to Kennedy",
"JFK has been shot", "John Kennedy Kennedy has been shot",
"This text has a typo in referring to Keneddy",
"wordx wordy wordz wordx wordy wordx worda wordb wordy wordc",
"y z x y z a b", "lets is a the lets is a the lets is a the lets" };
/**
* 创建测试索引
*
* @throws IOException
*/
public void createIndex() throws IOException {
// Analyzer analyzer = new StandardAnalyzer();
IndexWriter writer = new IndexWriter(ramDir, new IndexWriterConfig(
analyzer));
// 添加几个文本域
for (String text : texts) {
writer.addDocument(doc(FIELD_NAME, text));
}
// 添加几个数字域
Document doc = new Document();
doc.add(new IntField(NUMERIC_FIELD_NAME, 1, Field.Store.NO));
doc.add(new StoredField(NUMERIC_FIELD_NAME, 1));
writer.addDocument(doc);
doc = new Document();
doc.add(new IntField(NUMERIC_FIELD_NAME, 3, Field.Store.NO));
doc.add(new StoredField(NUMERIC_FIELD_NAME, 3));
writer.addDocument(doc);
doc = new Document();
doc.add(new IntField(NUMERIC_FIELD_NAME, 5, Field.Store.NO));
doc.add(new StoredField(NUMERIC_FIELD_NAME, 5));
writer.addDocument(doc);
doc = new Document();
doc.add(new IntField(NUMERIC_FIELD_NAME, 7, Field.Store.NO));
doc.add(new StoredField(NUMERIC_FIELD_NAME, 7));
writer.addDocument(doc);
Document childDoc = doc(FIELD_NAME, "child document");
Document parentDoc = doc(FIELD_NAME, "parent document");
writer.addDocuments(Arrays.asList(childDoc, parentDoc));
// 强制合并段文件,限制合并后段文件个数最大数量
writer.forceMerge(1);
writer.close();
}
/**
* 为Document添加域
*
* @param name
* @param value
* @return
*/
private Document doc(String name, String value) {
Document d = new Document();
d.add(new Field(name, value, FIELD_TYPE_TV));
return d;
}
/**
* 创建Token对象
*
* @param term
* @param start
* @param offset
* @return
*/
private static Token createToken(String term, int start, int offset) {
return new Token(term, start, offset);
}
public Highlighter getHighlighter(Query query, String fieldName,
Formatter formatter) {
return getHighlighter(query, fieldName, formatter, true);
}
/**
* 创建高亮器
*
* @param query
* @param fieldName
* @param formatter
* @param expanMultiTerm
* @return
*/
public Highlighter getHighlighter(Query query, String fieldName,
Formatter formatter, boolean expanMultiTerm) {
Scorer scorer;
if (mode == QUERY) {
scorer = new QueryScorer(query, fieldName);
// 是否展开多Term查询
if (!expanMultiTerm) {
((QueryScorer) scorer).setExpandMultiTermQuery(false);
}
} else if (mode == QUERY_TERM) {
scorer = new QueryTermScorer(query);
} else {
throw new RuntimeException("Unknown highlight mode");
}
return new Highlighter(formatter, scorer);
}
/**
* 获取高亮后的文本(如果高亮失败,则返回原样文本)
*
* @param query
* @param fieldName
* @param text
* @return
* @throws IOException
* @throws InvalidTokenOffsetsException
*/
private String highlightField(Query query, String fieldName, String text)
throws IOException, InvalidTokenOffsetsException {
// 将用户输入的搜索关键字通过分词器转化为TokenStream
TokenStream tokenStream = analyzer.tokenStream(fieldName, text);
// SimpleHTMLFormatter默认是使用<B></B>
SimpleHTMLFormatter formatter = new SimpleHTMLFormatter();
// 第3个参数表示默认域
QueryScorer scorer = new QueryScorer(query, fieldName, FIELD_NAME);
Highlighter highlighter = new Highlighter(formatter, scorer);
highlighter.setTextFragmenter(new SimpleFragmenter(Integer.MAX_VALUE));
// maxNumFragments:最大的高亮个数,separator:多个高亮段之间的分隔符,默认是...
String rv = highlighter.getBestFragments(tokenStream, text, 1, "...");
return rv.length() == 0 ? text : rv;
}
public Query doSearching(Query unReWrittenQuery) throws Exception {
IndexReader reader = DirectoryReader.open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader);
// 对于MultiTermQuery, TermRangeQuery, PrefixQuery,你如果使用QueryTermScorer而非QueryScorer,
//那么你必须对MultiTermQuery, TermRangeQuery, PrefixQuery进行rewrite
Query query = unReWrittenQuery.rewrite(reader);
hits = searcher.search(query, null, 1000);
return query;
}
public void testHighlightingWithDefaultField() throws Exception {
String s1 = "I call our world world Flatland, not because we call it so";
PhraseQuery q = new PhraseQuery();
// 表示两个Term之间最大3个间距
q.setSlop(3);
q.add(new Term(FIELD_NAME, "world"));
q.add(new Term(FIELD_NAME, "flatland"));
String observed = highlightField(q, FIELD_NAME, s1);
System.out.println(observed);
q = new PhraseQuery();
q.setSlop(3);
q.add(new Term("text", "world"));
q.add(new Term("text", "flatland"));
// 高亮域域查询时Query域不一致,所以无法高亮,这个务必注意
observed = highlightField(q, FIELD_NAME, s1);
System.out.println(observed);
}
/**
* CommonTermsQuery中使用高亮
*
* @throws Exception
*/
public void testHighlightingCommonTermsQuery() throws Exception {
createIndex();
// 第一个参数:频率高的Term必须出现,第二个参数:频率低的Term可有可无,第三个参数表示Term出现的最大频率
CommonTermsQuery query = new CommonTermsQuery(Occur.MUST, Occur.SHOULD,
3);
query.add(new Term(FIELD_NAME, "this"));
query.add(new Term(FIELD_NAME, "long"));
query.add(new Term(FIELD_NAME, "very"));
IndexReader reader = DirectoryReader.open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs hits = searcher.search(query, 10);
System.out.println("hits.totalHits:" + hits.totalHits);
QueryScorer scorer = new QueryScorer(query, FIELD_NAME);
Highlighter highlighter = new Highlighter(scorer);
Document doc = searcher.doc(hits.scoreDocs[0].doc);
String storedField = doc.get(FIELD_NAME);
TokenStream stream = TokenSources.getAnyTokenStream(
searcher.getIndexReader(), hits.scoreDocs[0].doc, FIELD_NAME,
doc, analyzer);
Fragmenter fragmenter = new SimpleSpanFragmenter(scorer);
highlighter.setTextFragmenter(fragmenter);
String fragment = highlighter.getBestFragment(stream, storedField);
System.out.println("fragment:" + fragment);
doc = searcher.doc(hits.scoreDocs[1].doc);
storedField = doc.get(FIELD_NAME);
stream = TokenSources.getAnyTokenStream(searcher.getIndexReader(),
hits.scoreDocs[1].doc, FIELD_NAME, doc, analyzer);
highlighter.setTextFragmenter(new SimpleSpanFragmenter(scorer));
fragment = highlighter.getBestFragment(stream, storedField);
// 打印第二个匹配结果高亮后的结果,默认是加<B></B>
System.out.println("fragment:" + fragment);
reader.close();
ramDir.close();
}
/**
* 测试下高亮最大显示个数和高亮段显示字符长度控制
*
* @throws Exception
*/
public void testSimpleTermQueryHighlighter() throws Exception {
// 创建索引
createIndex();
IndexReader reader = DirectoryReader.open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader);
Query query = doSearching(new TermQuery(new Term(FIELD_NAME, "kennedy")));
// 这里不能简单的使用TermQuery,MultiTermQuery,需要query.rewriter下,需要引起你们的注意
// Query query = new TermQuery(new Term(FIELD_NAME, "kennedy"));
// 设置最大显示的高亮段个数,即显示<B></B>的个数
int maxNumFragmentsRequired = 1;
QueryScorer scorer = new QueryScorer(query, FIELD_NAME);
Highlighter highlighter = new Highlighter(scorer);
for (int i = 0; i < hits.totalHits; i++) {
String text = searcher.doc(hits.scoreDocs[i].doc).get(FIELD_NAME);
TokenStream tokenStream = analyzer.tokenStream(FIELD_NAME, text);
// SimpleFragmenter构造函数里的这个参数表示显示的高亮段字符的总长度<B></B>标签也是计算在内的
// 自己调整这个数字,数数显示的高亮段字符的长度去感受下,你就懂了
highlighter.setTextFragmenter(new SimpleFragmenter(17));
String result = highlighter.getBestFragments(tokenStream, text,
maxNumFragmentsRequired, "...");
System.out.println("\t" + result);
}
}
public void testSimplePhraseQueryHightlighting() throws Exception {
// 创建索引
createIndex();
IndexReader reader = DirectoryReader.open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader);
PhraseQuery phraseQuery = new PhraseQuery();
phraseQuery.add(new Term(FIELD_NAME, "very"));
phraseQuery.add(new Term(FIELD_NAME, "long"));
phraseQuery.add(new Term(FIELD_NAME, "contains"), 3);
// 如果不对Query进行rewrite,你将会得到一个NullPointerException
Query query = doSearching(phraseQuery);
// 这个参数很诡异 SimpleFragmenter的构造参数,
int maxNumFragmentsRequired = 2;
QueryScorer scorer = new QueryScorer(query, FIELD_NAME);
Highlighter highlighter = new Highlighter(scorer);
for (int i = 0; i < hits.totalHits; i++) {
final Document doc = searcher.doc(hits.scoreDocs[i].doc);
String text = doc.get(FIELD_NAME);
TokenStream tokenStream = TokenSources.getAnyTokenStream(reader,
hits.scoreDocs[i].doc, FIELD_NAME, doc, analyzer);
highlighter.setTextFragmenter(new SimpleFragmenter(40));
String result = highlighter.getBestFragments(tokenStream, text,
maxNumFragmentsRequired, "...");
System.out.println("\t" + result);
}
// 测试2
phraseQuery = new PhraseQuery();
phraseQuery.add(new Term(FIELD_NAME, "piece"), 1);
phraseQuery.add(new Term(FIELD_NAME, "text"), 3);
phraseQuery.add(new Term(FIELD_NAME, "refers"), 4);
phraseQuery.add(new Term(FIELD_NAME, "kennedy"), 6);
query = doSearching(phraseQuery);
maxNumFragmentsRequired = 2;
scorer = new QueryScorer(query, FIELD_NAME);
highlighter = new Highlighter(scorer);
for (int i = 0; i < hits.totalHits; i++) {
final Document doc = searcher.doc(hits.scoreDocs[i].doc);
String text = doc.get(FIELD_NAME);
TokenStream tokenStream = TokenSources.getAnyTokenStream(reader,
hits.scoreDocs[i].doc, FIELD_NAME, doc, analyzer);
highlighter.setTextFragmenter(new SimpleFragmenter(40));
String result = highlighter.getBestFragments(tokenStream, text,
maxNumFragmentsRequired, "...");
System.out.println("\t" + result);
}
}
/**
* 在正则查询中使用高亮器
*
* @throws Exception
*/
public void testRegexQueryHightlighting() throws Exception {
// 创建索引
createIndex();
IndexReader reader = DirectoryReader.open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader);
Query query = new RegexpQuery(new Term(FIELD_NAME, "ken.*"));
searcher = new IndexSearcher(reader);
hits = searcher.search(query, 100);
int maxNumFragmentsRequired = 2;
QueryScorer scorer = new QueryScorer(query, FIELD_NAME);
Highlighter highlighter = new Highlighter(scorer);
for (int i = 0; i < hits.totalHits; i++) {
final Document doc = searcher.doc(hits.scoreDocs[i].doc);
String text = doc.get(FIELD_NAME);
TokenStream tokenStream = TokenSources.getAnyTokenStream(reader,
hits.scoreDocs[i].doc, FIELD_NAME, doc, analyzer);
highlighter.setTextFragmenter(new SimpleFragmenter(40));
String result = highlighter.getBestFragments(tokenStream, text,
maxNumFragmentsRequired, "...");
System.out.println("\t" + result);
}
}
/**
* 在通配符查询中使用高亮器
*
* @throws Exception
*/
public void testWildcardQueryHightlighting() throws Exception {
// 创建索引
createIndex();
IndexReader reader = DirectoryReader.open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader);
Query query = new WildcardQuery(new Term(FIELD_NAME, "k?nnedy"));
searcher = new IndexSearcher(reader);
hits = searcher.search(query, 100);
int maxNumFragmentsRequired = 2;
QueryScorer scorer = new QueryScorer(query, FIELD_NAME);
Highlighter highlighter = new Highlighter(scorer);
for (int i = 0; i < hits.totalHits; i++) {
final Document doc = searcher.doc(hits.scoreDocs[i].doc);
String text = doc.get(FIELD_NAME);
TokenStream tokenStream = TokenSources.getAnyTokenStream(reader,
hits.scoreDocs[i].doc, FIELD_NAME, doc, analyzer);
highlighter.setTextFragmenter(new SimpleFragmenter(40));
String result = highlighter.getBestFragments(tokenStream, text,
maxNumFragmentsRequired, "...");
System.out.println("\t" + result);
}
}
/**
* 在TermRangeQuery中使用高亮器
*
* @throws Exception
*/
public void testTermRangeQueryHightlighting() throws Exception {
// 创建索引
createIndex();
IndexReader reader = DirectoryReader.open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader);
TermRangeQuery rangeQuery = new TermRangeQuery(
FIELD_NAME,
new BytesRef("kannedy"),
new BytesRef("kznnedy"),
true, true);
rangeQuery.setRewriteMethod(MultiTermQuery.SCORING_BOOLEAN_QUERY_REWRITE);
searcher = new IndexSearcher(reader);
hits = searcher.search(rangeQuery, 100);
int maxNumFragmentsRequired = 2;
QueryScorer scorer = new QueryScorer(rangeQuery, FIELD_NAME);
Highlighter highlighter = new Highlighter(scorer);
for (int i = 0; i < hits.totalHits; i++) {
final Document doc = searcher.doc(hits.scoreDocs[i].doc);
String text = doc.get(FIELD_NAME);
TokenStream tokenStream = TokenSources.getAnyTokenStream(reader,
hits.scoreDocs[i].doc, FIELD_NAME, doc, analyzer);
highlighter.setTextFragmenter(new SimpleFragmenter(40));
String result = highlighter.getBestFragments(tokenStream, text,
maxNumFragmentsRequired, "...");
System.out.println("\t" + result);
}
}
/**
* 在SpanNear查询中使用高亮器
*
* @throws Exception
*/
public void testSpanNearQueryHightlighting() throws Exception {
// 创建索引
createIndex();
IndexReader reader = DirectoryReader.open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader);
Query query = new SpanNearQuery(new SpanQuery[] {
new SpanTermQuery(new Term(FIELD_NAME, "beginning")),
new SpanTermQuery(new Term(FIELD_NAME, "kennedy")) }, 3, false);
/*Query query = doSearching(new SpanNearQuery(new SpanQuery[] {
new SpanTermQuery(new Term(FIELD_NAME, "beginning")),
new SpanTermQuery(new Term(FIELD_NAME, "kennedy")) }, 3, false));*/
searcher = new IndexSearcher(reader);
hits = searcher.search(query, 100);
int maxNumFragmentsRequired = 2;
QueryScorer scorer = new QueryScorer(query, FIELD_NAME);
Highlighter highlighter = new Highlighter(scorer);
for (int i = 0; i < hits.totalHits; i++) {
final Document doc = searcher.doc(hits.scoreDocs[i].doc);
String text = doc.get(FIELD_NAME);
TokenStream tokenStream = TokenSources.getAnyTokenStream(reader,
hits.scoreDocs[i].doc, FIELD_NAME, doc, analyzer);
highlighter.setTextFragmenter(new SimpleFragmenter(40));
String result = highlighter.getBestFragments(tokenStream, text,
maxNumFragmentsRequired, "...");
System.out.println("\t" + result);
}
}
/**
* 在FuzzyQuery查询中使用高亮器
*
* @throws Exception
*/
public void testFuzzyQueryHightlighting() throws Exception {
// 创建索引
createIndex();
IndexReader reader = DirectoryReader.open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader);
FuzzyQuery query = new FuzzyQuery(new Term(FIELD_NAME, "kinnedy"), 2);
searcher = new IndexSearcher(reader);
hits = searcher.search(query, 100);
int maxNumFragmentsRequired = 2;
QueryScorer scorer = new QueryScorer(query, FIELD_NAME);
Highlighter highlighter = new Highlighter(scorer);
for (int i = 0; i < hits.totalHits; i++) {
final Document doc = searcher.doc(hits.scoreDocs[i].doc);
String text = doc.get(FIELD_NAME);
TokenStream tokenStream = TokenSources.getAnyTokenStream(reader,
hits.scoreDocs[i].doc, FIELD_NAME, doc, analyzer);
highlighter.setTextFragmenter(new SimpleFragmenter(40));
String result = highlighter.getBestFragments(tokenStream, text,
maxNumFragmentsRequired, "...");
System.out.println("\t" + result);
}
}
/**
* 在joinQuery中使用高亮器
* @throws Exception
*/
public void testToParentBlockJoinQuery() throws Exception {
// 创建索引
createIndex();
IndexReader reader = DirectoryReader.open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader);
//你过滤出域值包含parent的索引文档作为parent
BitDocIdSetFilter parentFilter = new BitDocIdSetCachingWrapperFilter(
new QueryWrapperFilter(new TermQuery(new Term(FIELD_NAME,
"parent"))));
//然后通过ToParentBlockJoinQuery在parent中找child索引文档且child索引文档必须符合[域值包含child字符]
//我们在创建索引时是通过addDocuments添加的parent和child的,即addDocuments,这里接收一个documents数组,
//父子关系判定规则是,数组中最后一个索引为parent,前面剩下的索引文档都作为parent的child,记住child必须在parent前面
//这也是addDocuments和addDocument的区别
Query query = new ToParentBlockJoinQuery(new TermQuery(new Term(
FIELD_NAME, "child")), parentFilter, ScoreMode.Total);
hits = searcher.search(query, 100);
int maxNumFragmentsRequired = 3;
QueryScorer scorer = new QueryScorer(query, FIELD_NAME);
Highlighter highlighter = new Highlighter(scorer);
for (int i = 0; i < hits.totalHits; i++) {
String text = "child document";
TokenStream tokenStream = analyzer.tokenStream(FIELD_NAME, text);
highlighter.setTextFragmenter(new SimpleFragmenter(50));
String fragment = highlighter.getBestFragments(tokenStream, text,
maxNumFragmentsRequired, "...");
System.out.println("\t" + fragment);
}
}
/**
* 测试高亮时对特殊字符进行编码,如< > & "等等
* 在构造高亮器时传入SimpleHTMLEncoder即可
* 通过SimpleHTMLFormatter可以自定义高亮时的开始和结束标签,如:new SimpleHTMLFormatter("<font color=\"red\">","</font>")
* 默认是<B> </B>
* @throws Exception
*/
public void testEncoding() throws Exception {
String rawDocContent = "\"Smith & sons' prices < 3 and >4\" claims article";
Query query = new RegexpQuery(new Term(FIELD_NAME,"price.*"));
QueryScorer scorer = new QueryScorer(query, FIELD_NAME, FIELD_NAME);
Highlighter highlighter = new Highlighter(new SimpleHTMLFormatter("<font color=\"red\">","</font>"),new SimpleHTMLEncoder(),scorer);
highlighter.setTextFragmenter(new SimpleFragmenter(2000));
TokenStream tokenStream = analyzer.tokenStream(FIELD_NAME, rawDocContent);
String encodedSnippet = highlighter.getBestFragments(tokenStream, rawDocContent, 1, "");
System.out.println(encodedSnippet);
}
public static void main(String[] args) throws Exception {
SimpleHightlightTest simpleHightlightTest = new SimpleHightlightTest();
// simpleHightlightTest.testHighlightingCommonTermsQuery();
// simpleHightlightTest.testHighlightingWithDefaultField();
// simpleHightlightTest.testSimpleTermQueryHighlighter();
// simpleHightlightTest.testSimplePhraseQueryHightlighting();
simpleHightlightTest.testRegexQueryHightlighting();
//simpleHightlightTest.testWildcardQueryHightlighting();
//simpleHightlightTest.testToParentBlockJoinQuery();
//simpleHightlightTest.testSpanNearQueryHightlighting();
//simpleHightlightTest.testFuzzyQueryHightlighting();
//simpleHightlightTest.testTermRangeQueryHightlighting();
//simpleHightlightTest.testEncoding();
}
}
请注意看里面的代码注释,关键地方我有加相关说明。
这两个参数很诡异
当你设置最多显示2个高亮段,但如果SimpleFragmenter构造参数设置的最大段字符长度能够显示超过2个高亮段,则会无视maxNumFragmentsRequired设置
相反如果你最大能显示的段字符长度设置的很小不足以显示1个高亮段,而最多能显示的高亮段个数大于1,这是最大能显示的段字符长度设置无效,以最多能显示的高亮段个数为准。
int maxNumFragmentsRequired = 3;
new SimpleFragmenter(2)
上面两个参数的设置需要引起你们的注意。
接着来说说FastVectorHighlighter快速高亮器,为什么叫快速高亮器呢?意思就是说使用它进行高亮速度比较快,那它跟普通的Hightlighter有何区别呢?
两者本质区别就是实现方式不同,普通的Hightlighter是基本分词实现的,即先把用户输入的搜索关键字通过分词器Analyzer分词为一个个的Term,然后与Filed的域值进行算法匹配的。而FastVectorHighlighter是基于项向量实现的,从域中加载出位置起始信息,位置增量,项向量等信息,知道了每个域中每个Term的位置信息,自然就能快速的定位Term,然后在Term两头添加上高亮标签。既然需要读取项向量信息,意味着我们在创建索引的时候,就需要设置域存储位置起始索引、位置增量以及项向量,体现在API上就是:
type.setStoreTermVectorOffsets(true);
type.setStoreTermVectorPositions(true);
type.setStoreTermVectors(true);
由于需要额外存储TermVector信息,则意味着需要额外占用硬盘空间和更多的磁盘IO操作,索引体积变大了,我们在进行索引查询的时候,占用的内存也会加大,所以不能说FastVectorHighlighter能完全替代Hightlighter,该不该使用FastVectorHighlighter应该考虑为索引域额外存储TermVector信息会带来多少查询性能的损耗,两者之间要做一个权衡。如果影响很大,这时就可以考虑使用前端JavaScript里进行高亮。即把用户输入的搜索关键字传递到后台里,后台对用户输入的搜索关键字进行分词,然后把分词后的Term回传到前端,在前端JS里进行高亮操作。
FastVectorHighlighter除了在高亮速度上比普通Hightlighter快点以外,它还有个特色就是支持多种样式高亮即不同的命中关键字可以使用不同的高亮样式进行显示(比如字体颜色不同,这取决于你高亮标签里的CSS样式),FastVectorHighlighter还支持相邻的几个命中的关键字合并在一起进行高亮等等。
至于FastVectorHighlighter如何使用,两者在API使用上没有太大的区别,大家还是看下面的示例代码吧:
package com.yida.framework.lucene5.facet;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.PhraseQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.highlight.Encoder;
import org.apache.lucene.search.highlight.SimpleHTMLEncoder;
import org.apache.lucene.search.vectorhighlight.FastVectorHighlighter;
import org.apache.lucene.search.vectorhighlight.FieldQuery;
import org.apache.lucene.search.vectorhighlight.FragListBuilder;
import org.apache.lucene.search.vectorhighlight.FragmentsBuilder;
import org.apache.lucene.search.vectorhighlight.ScoreOrderFragmentsBuilder;
import org.apache.lucene.search.vectorhighlight.SimpleFragListBuilder;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
/**
* 快速高亮器测试
*
* @author Lanxiaowei
*
*/
public class FastVectorHighlighterTest {
public static void main(String[] args) throws Exception {
// testSimpleHighlightTest();
// testPhraseHighlightLongTextTest();
// testPhraseHighlightTest();
// testBoostedPhraseHighlightTest();
testFormater();
}
/**
* 快速高亮器第一个简单测试
*
* @throws IOException
*/
public static void testSimpleHighlightTest() throws IOException {
Directory dir = new RAMDirectory();
IndexWriter writer = new IndexWriter(dir, new IndexWriterConfig(
new StandardAnalyzer()));
Document doc = new Document();
FieldType type = new FieldType(TextField.TYPE_STORED);
type.setStoreTermVectorOffsets(true);
type.setStoreTermVectorPositions(true);
type.setStoreTermVectors(true);
type.freeze();
Field field = new Field(
"field",
"This is a test where foo is highlighed and should be highlighted",
type);
doc.add(field);
writer.addDocument(doc);
FastVectorHighlighter highlighter = new FastVectorHighlighter();
IndexReader reader = DirectoryReader.open(writer, true);
int docId = 0;
FieldQuery fieldQuery = highlighter.getFieldQuery(new TermQuery(
new Term("field", "foo")), reader);
/**
* 测试高亮段显示字符最大长度的影响
*/
String[] bestFragments = highlighter.getBestFragments(fieldQuery,
reader, docId, "field", 54, 1);
System.out.println(bestFragments[0]);
bestFragments = highlighter.getBestFragments(fieldQuery, reader, docId,
"field", 52, 1);
System.out.println(bestFragments[0]);
bestFragments = highlighter.getBestFragments(fieldQuery, reader, docId,
"field", 30, 1);
System.out.println(bestFragments[0]);
reader.close();
writer.close();
dir.close();
}
public static void testPhraseHighlightLongTextTest() throws IOException {
Directory dir = new RAMDirectory();
IndexWriter writer = new IndexWriter(dir, new IndexWriterConfig(
new StandardAnalyzer()));
Document doc = new Document();
FieldType type = new FieldType(TextField.TYPE_STORED);
type.setStoreTermVectorOffsets(true);
type.setStoreTermVectorPositions(true);
type.setStoreTermVectors(true);
type.freeze();
Field text = new Field(
"text",
"Netscape was the general name for a series of web browsers originally produced by Netscape Communications Corporation, now a subsidiary of AOL The original browser was once the dominant browser in terms of usage share, but as a result of the first browser war it lost virtually all of its share to Internet Explorer Netscape was discontinued and support for all Netscape browsers and client products was terminated on March 1, 2008 Netscape Navigator was the name of Netscape\u0027s web browser from versions 1.0 through 4.8 The first beta release versions of the browser were released in 1994 and known as Mosaic and then Mosaic Netscape until a legal challenge from the National Center for Supercomputing Applications (makers of NCSA Mosaic, which many of Netscape\u0027s founders used to develop), led to the name change to Netscape Navigator The company\u0027s name also changed from Mosaic Communications Corporation to Netscape Communications Corporation The browser was easily the most advanced...",
type);
doc.add(text);
writer.addDocument(doc);
FastVectorHighlighter highlighter = new FastVectorHighlighter();
IndexReader reader = DirectoryReader.open(writer, true);
int docId = 0;
String field = "text";
{
// BooleanQuery把两个Term分别进行高亮,因为BooleanQuery无法表示两个Term之间的位置关系
BooleanQuery query = new BooleanQuery();
query.add(new TermQuery(new Term(field, "internet")), Occur.MUST);
query.add(new TermQuery(new Term(field, "explorer")), Occur.MUST);
FieldQuery fieldQuery = highlighter.getFieldQuery(query, reader);
String[] bestFragments = highlighter.getBestFragments(fieldQuery,
reader, docId, field, 128, 1);
System.out.println(bestFragments.length);
System.out.println(bestFragments[0]);
}
{
// 构造PhraseQuery时添加的两个Term之间是没有间隙,是连在一起的,且两者在原文中也是连在一起的,
// 所以高亮时也是当作一个整体进行高亮的,这是普通高亮器实现不了的
PhraseQuery query = new PhraseQuery();
query.add(new Term(field, "internet"));
query.add(new Term(field, "explorer"));
FieldQuery fieldQuery = highlighter.getFieldQuery(query, reader);
String[] bestFragments = highlighter.getBestFragments(fieldQuery,
reader, docId, field, 128, 1);
System.out.println(bestFragments.length);
System.out.println(bestFragments[0]);
}
reader.close();
writer.close();
dir.close();
}
public static void testPhraseHighlightTest() throws IOException {
Directory dir = new RAMDirectory();
IndexWriter writer = new IndexWriter(dir, new IndexWriterConfig(
new StandardAnalyzer()));
Document doc = new Document();
FieldType type = new FieldType(TextField.TYPE_STORED);
// ////////////////////////////////////////////
// 因为FastVectorHightlighter高亮器就是依赖项向量来完成高亮功能的,所以下面的3项设置是必须的
type.setStoreTermVectorOffsets(true);
type.setStoreTermVectorPositions(true);
type.setStoreTermVectors(true);
// ////////////////////////////////////////////
type.freeze();
Field longTermField = new Field(
"long_term",
"This is a test thisisaverylongwordandmakessurethisfails where foo is highlighed and should be highlighted",
type);
Field noLongTermField = new Field(
"no_long_term",
"This is a test where foo is highlighed and should be highlighted",
type);
doc.add(longTermField);
doc.add(noLongTermField);
writer.addDocument(doc);
FastVectorHighlighter highlighter = new FastVectorHighlighter();
IndexReader reader = DirectoryReader.open(writer, true);
int docId = 0;
String field = "no_long_term";
{
BooleanQuery query = new BooleanQuery();
query.add(new TermQuery(new Term(field, "test")), Occur.MUST);
query.add(new TermQuery(new Term(field, "foo")), Occur.MUST);
query.add(new TermQuery(new Term(field, "highlighed")), Occur.MUST);
FieldQuery fieldQuery = highlighter.getFieldQuery(query, reader);
String[] bestFragments = highlighter.getBestFragments(fieldQuery,
reader, docId, field, 18, 1);
System.out.println(bestFragments.length);
System.out.println(bestFragments[0]);
}
{
BooleanQuery query = new BooleanQuery();
PhraseQuery pq = new PhraseQuery();
pq.add(new Term(field, "test"));
pq.add(new Term(field, "foo"));
pq.add(new Term(field, "highlighed"));
pq.setSlop(5);
query.add(new TermQuery(new Term(field, "foo")), Occur.MUST);
query.add(pq, Occur.MUST);
query.add(new TermQuery(new Term(field, "highlighed")), Occur.MUST);
FieldQuery fieldQuery = highlighter.getFieldQuery(query, reader);
String[] bestFragments = highlighter.getBestFragments(fieldQuery,
reader, docId, field, 18, 1);
System.out.println(bestFragments.length);
if (bestFragments.length > 0) {
System.out.println(bestFragments[0]);
}
bestFragments = highlighter.getBestFragments(fieldQuery, reader,
docId, field, 30, 1);
System.out.println(bestFragments.length);
System.out.println(bestFragments[0]);
}
{
PhraseQuery query = new PhraseQuery();
query.add(new Term(field, "test"));
query.add(new Term(field, "foo"));
query.add(new Term(field, "highlighed"));
query.setSlop(3);
FieldQuery fieldQuery = highlighter.getFieldQuery(query, reader);
String[] bestFragments = highlighter.getBestFragments(fieldQuery,
reader, docId, field, 18, 1);
System.out.println(bestFragments.length);
bestFragments = highlighter.getBestFragments(fieldQuery, reader,
docId, field, 30, 1);
System.out.println(bestFragments.length);
System.out.println(bestFragments[0]);
}
{
PhraseQuery query = new PhraseQuery();
query.add(new Term(field, "test"));
query.add(new Term(field, "foo"));
query.add(new Term(field, "highlighted"));
query.setSlop(30);
FieldQuery fieldQuery = highlighter.getFieldQuery(query, reader);
String[] bestFragments = highlighter.getBestFragments(fieldQuery,
reader, docId, field, 18, 1);
System.out.println(bestFragments.length);
}
{
BooleanQuery query = new BooleanQuery();
PhraseQuery pq = new PhraseQuery();
pq.add(new Term(field, "test"));
pq.add(new Term(field, "foo"));
pq.add(new Term(field, "highlighed"));
pq.setSlop(5);
BooleanQuery inner = new BooleanQuery();
inner.add(pq, Occur.MUST);
inner.add(new TermQuery(new Term(field, "foo")), Occur.MUST);
query.add(inner, Occur.MUST);
query.add(pq, Occur.MUST);
query.add(new TermQuery(new Term(field, "highlighed")), Occur.MUST);
FieldQuery fieldQuery = highlighter.getFieldQuery(query, reader);
String[] bestFragments = highlighter.getBestFragments(fieldQuery,
reader, docId, field, 18, 1);
System.out.println(bestFragments.length);
bestFragments = highlighter.getBestFragments(fieldQuery, reader,
docId, field, 30, 1);
System.out.println(bestFragments.length);
System.out.println(bestFragments[0]);
}
field = "long_term";
{
BooleanQuery query = new BooleanQuery();
query.add(new TermQuery(new Term(field,
"thisisaverylongwordandmakessurethisfails")), Occur.MUST);
query.add(new TermQuery(new Term(field, "foo")), Occur.MUST);
query.add(new TermQuery(new Term(field, "highlighed")), Occur.MUST);
FieldQuery fieldQuery = highlighter.getFieldQuery(query, reader);
// 如果Term关键字自身长度就已经超过了设置的高亮段字符显示最大长度,则直接无视该设置,会完整显示该Term并加上高亮标签
String[] bestFragments = highlighter.getBestFragments(fieldQuery,
reader, docId, field, 18, 1);
System.out.println(bestFragments.length);
System.out.println(bestFragments[0]);
}
reader.close();
writer.close();
dir.close();
}
public static void testBoostedPhraseHighlightTest() throws IOException {
Directory dir = new RAMDirectory();
IndexWriter writer = new IndexWriter(dir, new IndexWriterConfig(
new StandardAnalyzer()));
Document doc = new Document();
FieldType type = new FieldType(TextField.TYPE_STORED);
type.setStoreTermVectorOffsets(true);
type.setStoreTermVectorPositions(true);
type.setStoreTermVectors(true);
type.freeze();
StringBuilder text = new StringBuilder();
text.append("words words junk junk junk junk junk junk junk junk highlight junk junk junk junk together junk ");
for (int i = 0; i < 10; i++) {
text.append("junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk ");
}
text.append("highlight words together ");
for (int i = 0; i < 10; i++) {
text.append("junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk junk ");
}
doc.add(new Field("text", text.toString().trim(), type));
writer.addDocument(doc);
FastVectorHighlighter highlighter = new FastVectorHighlighter();
IndexReader reader = DirectoryReader.open(writer, true);
BooleanQuery terms = new BooleanQuery();
terms.add(clause("text", "highlight"), Occur.MUST);
terms.add(clause("text", "words"), Occur.MUST);
terms.add(clause("text", "together"), Occur.MUST);
BooleanQuery phrase = new BooleanQuery();
phrase.add(clause("text", "highlight", "words", "together"), Occur.MUST);
phrase.setBoost(100);
BooleanQuery query = new BooleanQuery();
query.add(terms, Occur.MUST);
// 加上PhraseQuery就能将多个连在一起的Term一起高亮
query.add(phrase, Occur.SHOULD);
FieldQuery fieldQuery = highlighter.getFieldQuery(query, reader);
String fragment = highlighter.getBestFragment(fieldQuery, reader, 0,
"text", 10000);
System.out.println(fragment);
reader.close();
writer.close();
dir.close();
}
public static void testFormater() throws IOException, ParseException {
Directory dir = new RAMDirectory();
IndexWriter writer = new IndexWriter(dir, new IndexWriterConfig(
new StandardAnalyzer()));
Document doc = new Document();
FieldType type = new FieldType(TextField.TYPE_STORED);
type.setStoreTermVectorOffsets(true);
type.setStoreTermVectorPositions(true);
type.setStoreTermVectors(true);
type.freeze();
Field field = new Field(
"field",
"This is a test where foo is highlighed&<underline> and should be \"highlighted\".",
type);
doc.add(field);
writer.addDocument(doc);
//自定义高亮标签,默认为<B></B>
String[] preTags = new String[] { "<font color=\"#0000FF\">","<strong>" };
String[] postTags = new String[] { "</font>","</strong>" };
FragListBuilder fragListBuilder = new SimpleFragListBuilder();
FragmentsBuilder fragmentsBuilder = new ScoreOrderFragmentsBuilder(preTags,postTags);
//创建快速高亮器
FastVectorHighlighter highlighter = new FastVectorHighlighter(true,true,fragListBuilder,fragmentsBuilder);
// 特殊字符编码器
Encoder encoder = new SimpleHTMLEncoder();
IndexReader reader = DirectoryReader.open(writer, true);
/*PhraseQuery query = new PhraseQuery();
query.add(new Term("field", "test"));
query.add(new Term("field", "foo"));
query.setSlop(2);*/
QueryParser queryParser = new QueryParser("field",new StandardAnalyzer());
Query query = queryParser.parse("test foo");
System.out.println(query.toString());
FieldQuery fieldQuery = highlighter.getFieldQuery(query, reader);
int docId = 0;
// matchedFields对哪些域进行高亮,添加多个域即可以对多个域进行高亮
Set<String> matchedFields = new HashSet<String>();
matchedFields.add("field");
String[] bestFragments = highlighter.getBestFragments(fieldQuery,
reader, docId, "field", matchedFields, 100, 1, fragListBuilder,
fragmentsBuilder, preTags, postTags, encoder);
System.out.println(bestFragments[0]);
reader.close();
writer.close();
dir.close();
}
private static Query clause(String field, String... terms) {
return clause(field, 1, terms);
}
private static Query clause(String field, float boost, String... terms) {
Query q;
if (terms.length == 1) {
q = new TermQuery(new Term(field, terms[0]));
} else {
PhraseQuery pq = new PhraseQuery();
for (String term : terms) {
pq.add(new Term(field, term));
}
q = pq;
}
q.setBoost(boost);
return q;
}
}
至于使用那种高亮器,请对这两种高亮器分别进行性能测试,用事实测试数据说话,不能简单说FastVectorHighlighter比Highlighter好或Highlighter比FastVectorHighlighter好,在特定的场景下表现良好才是真的好。OK,有关高亮器就说这么多了,如果有哪里说的不对或者有哪里没说到的地方,还望大家积极指正,互相交流互相学习共同进步!DEMO源码请在最底下的附近里下载。
对于最近有个很令人作呕的人(名字我就不公布了,给你留点面子)老是对我的博客文章进行恶意点“踩”,请问这位童鞋,你是妒忌呢还是出门忘吃药了?更恶心的是,居然经常在我博客下方评论里贴他的淘宝链接推广他那恶心的代码,未经过我允许就在我博客里推广你的淘宝就够恶心的了,居然卖的还是代码,还是请自重吧!
如果你还有什么问题请加我Q-Q:7-3-6-0-3-1-3-0-5,
或者加裙![]() 一起交流学习!
一起交流学习!