MMSeg4j是一款中文分词器,详细介绍如下:
1、mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法(http://technology.chtsai.org/mmseg/ )实现的中文分词器,并实现 lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使用。
2、MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。Complex 加了四个规则过虑。官方说:词语的正确识别率达到了 98.41%。mmseg4j 已经实现了这两种分词算法。
1.5版的分词速度simple算法是 1100kb/s左右、complex算法是 700kb/s左右,(测试机:AMD athlon 64 2800+ 1G内存 xp)。
1.6版在complex基础上实现了最多分词(max-word)。“很好听” -> "很好|好听"; “中华人民共和国” -> "中华|华人|共和|国"; “中国人民银行” -> "中国|人民|银行"。
1.7-beta 版, 目前 complex 1200kb/s左右, simple 1900kb/s左右, 但内存开销了50M左右. 上几个版都是在10M左右
可惜的是,MMSeg4j最新版1.9.1不支持Lucene5.0,于是我就修改了它的源码将它升级咯,使其支持Lucene5.x,至于我是怎样修改,这里就不一一说明的,我把我修改过的MMSeg4j最新源码上传到了我的百度网盘,现分享给你们咯:
下面是一个MMSeg4j分词器简单使用示例:
package com.chenlb.mmseg4j.analysis;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Ignore;
import org.junit.Test;
/**
* MMSegAnalyzer分词器测试
* @author Lanxiaowei
*
*/
public class MMSegAnalyzerTest {
String txt = "";
@Before
public void before() throws Exception {
txt = "京华时报2009年1月23日报道 昨天,受一股来自中西伯利亚的强冷空气影响,本市出现大风降温天气,白天最高气温只有零下7摄氏度,同时伴有6到7级的偏北风。";
txt = "2009年ゥスぁま是中 ABcc国абвгαβγδ首次,我的ⅠⅡⅢ在chenёlbēū全国ㄦ范围ㄚㄞㄢ内①ē②㈠㈩⒈⒑发行地方政府债券,";
txt = "大S小3U盘浙BU盘T恤T台A股牛B";
}
@Test
//@Ignore
public void testSimple() throws IOException {
Analyzer analyzer = new SimpleAnalyzer();
displayTokens(analyzer,txt);
}
@Test
@Ignore
public void testComplex() throws IOException {
//txt = "1999年12345日报道了一条新闻,2000年中法国足球比赛";
/*txt = "第一卷 云天落日圆 第一节 偷欢不成倒大霉";
txt = "中国人民银行";
txt = "我们";
txt = "工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作";*/
//ComplexSeg.setShowChunk(true);
Analyzer analyzer = new ComplexAnalyzer();
displayTokens(analyzer,txt);
}
@Test
@Ignore
public void testMaxWord() throws IOException {
//txt = "1999年12345日报道了一条新闻,2000年中法国足球比赛";
//txt = "第一卷 云天落日圆 第一节 偷欢不成倒大霉";
//txt = "中国人民银行";
//txt = "下一个 为什么";
//txt = "我们家门前的大水沟很难过";
//ComplexSeg.setShowChunk(true);
Analyzer analyzer = new MaxWordAnalyzer();
displayTokens(analyzer,txt);
}
/*@Test
public void testCutLeeterDigitFilter() {
String myTxt = "mb991ch cq40-519tx mmseg4j ";
List<String> words = toWords(myTxt, new MMSegAnalyzer("") {
@Override
protected TokenStreamComponents createComponents(String text) {
Reader reader = new BufferedReader(new StringReader(text));
Tokenizer t = new MMSegTokenizer(newSeg(), reader);
return new TokenStreamComponents(t, new CutLetterDigitFilter(t));
}
});
//Assert.assertArrayEquals("CutLeeterDigitFilter fail", words.toArray(new String[words.size()]), "mb 991 ch cq 40 519 tx mmseg 4 j".split(" "));
for(String word : words) {
System.out.println(word);
}
}*/
public static void displayTokens(Analyzer analyzer,String text) throws IOException {
TokenStream tokenStream = analyzer.tokenStream("text", text);
displayTokens(tokenStream);
}
public static void displayTokens(TokenStream tokenStream) throws IOException {
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
PositionIncrementAttribute positionIncrementAttribute = tokenStream.addAttribute(PositionIncrementAttribute.class);
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
TypeAttribute typeAttribute = tokenStream.addAttribute(TypeAttribute.class);
tokenStream.reset();
int position = 0;
while (tokenStream.incrementToken()) {
int increment = positionIncrementAttribute.getPositionIncrement();
if(increment > 0) {
position = position + increment;
System.out.print(position + ":");
}
int startOffset = offsetAttribute.startOffset();
int endOffset = offsetAttribute.endOffset();
String term = charTermAttribute.toString();
System.out.println("[" + term + "]" + ":(" + startOffset + "-->" + endOffset + "):" + typeAttribute.type());
}
}
/**
* 断言分词结果
* @param analyzer
* @param text 源字符串
* @param expecteds 期望分词后结果
* @throws IOException
*/
public static void assertAnalyzerTo(Analyzer analyzer,String text,String[] expecteds) throws IOException {
TokenStream tokenStream = analyzer.tokenStream("text", text);
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
for(String expected : expecteds) {
Assert.assertTrue(tokenStream.incrementToken());
Assert.assertEquals(expected, charTermAttribute.toString());
}
Assert.assertFalse(tokenStream.incrementToken());
tokenStream.close();
}
}
mmseg4j分词器有3个字典文件,如图: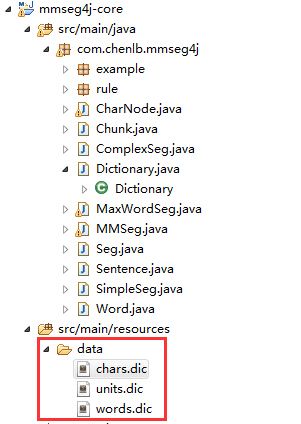
chars.dic是汉字字典文件,里面有12638个汉字
units.dic里是中文单位词语,如小时,分钟,米,厘米等等,具体自己打开看看就明白了
words.dic就是用户自定义字典文件,比如:么么哒,T恤,牛B等这些词,放在这个字典文件里,分词器就能把它当作一个词
我们在使用mmseg4j分词器时,是这样用的:
Analyzer analyzer = new SimpleAnalyzer();
查看SimpleAnalyzer的构造函数,
public SimpleAnalyzer() {
super();
}
调用的是父类MMSegAnalyzer的无参构造函数,接着查看MMSegAnalyzer类的无参构造函数:
public MMSegAnalyzer() {
dic = Dictionary.getInstance();
}
你会发现是通过Dictionary.getInstance()单实例模式去加载字典文件的,接着查看getInstance方法,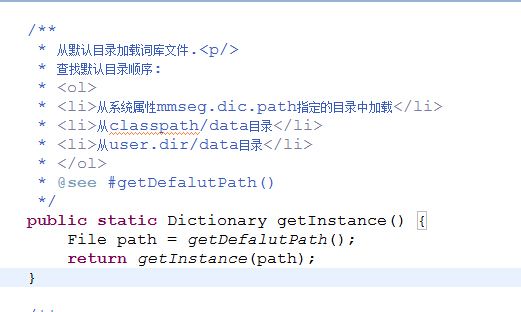
这里的代码注释写的很清楚,告诉了我们字典文件的加载逻辑。
File path = getDefalutPath();用来获取默认的字典文件路径,
然后根据字典文件路径调用getInstance(path)方法去加载字典文件,接着查看该方法,

先从缓存dics里去字典文件,如果缓存里没有找到,则才会根据字典文件路径去加载,然后把加载到的字典文件放入缓存dics即dics.put(),
接着看看Dictionary字典是如何初始化的,查看Dictionary的构造函数源码: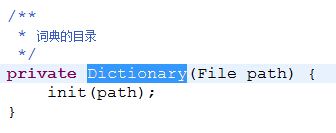
你会发现内部实际是通过调用init(path);方法进行字典初始化的,继续查阅init方法,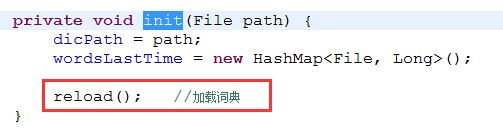
内部又是调用的reload方法加载的字典,继续跟踪至reload方法,
内部通过loadDic去加载words和chars两个字典文件,通过loadUnit方法去加载units字典文件,wordsLastTime是用来存放每个字典文件的最后一次修改时间,引入这个map的目的是为了实现字典文件重新加载,通过字典文件的最后一次修改时间来判定文件是否修改过,如果这个map里不存在某字典文件的最后一次修改时间,则表明该字典文件是新加入的,需要重新加载至内存,这是loadDic方法的源码:
private Map<Character, CharNode> loadDic(File wordsPath) throws IOException {
InputStream charsIn = null;
File charsFile = new File(wordsPath, "chars.dic");
if(charsFile.exists()) {
charsIn = new FileInputStream(charsFile);
addLastTime(charsFile); //chars.dic 也检测是否变更
} else { //从 jar 里加载
charsIn = this.getClass().getResourceAsStream("/data/chars.dic");
charsFile = new File(this.getClass().getResource("/data/chars.dic").getFile()); //only for log
}
final Map<Character, CharNode> dic = new HashMap<Character, CharNode>();
int lineNum = 0;
long s = now();
long ss = s;
lineNum = load(charsIn, new FileLoading() { //单个字的
public void row(String line, int n) {
if(line.length() < 1) {
return;
}
String[] w = line.split(" ");
CharNode cn = new CharNode();
switch(w.length) {
case 2:
try {
cn.setFreq((int)(Math.log(Integer.parseInt(w[1]))*100));//字频计算出自由度
} catch(NumberFormatException e) {
//eat...
}
case 1:
dic.put(w[0].charAt(0), cn);
}
}
});
log.info("chars loaded time="+(now()-s)+"ms, line="+lineNum+", on file="+charsFile);
//try load words.dic in jar
InputStream wordsDicIn = this.getClass().getResourceAsStream("/data/words.dic");
if(wordsDicIn != null) {
File wordsDic = new File(this.getClass().getResource("/data/words.dic").getFile());
loadWord(wordsDicIn, dic, wordsDic);
}
File[] words = listWordsFiles(); //只要 wordsXXX.dic的文件
if(words != null) { //扩展词库目录
for(File wordsFile : words) {
loadWord(new FileInputStream(wordsFile), dic, wordsFile);
addLastTime(wordsFile); //用于检测是否修改
}
}
log.info("load all dic use time="+(now()-ss)+"ms");
return dic;
}
大致逻辑就是先加载chars.dic再加载words.dic,最后加载用户自定义字典文件,注意用户自定义字典文件命名需要以words开头且文件名后缀必须为.dic,查找所有用户自定义字典文件是这句代码:
File[] words = listWordsFiles();
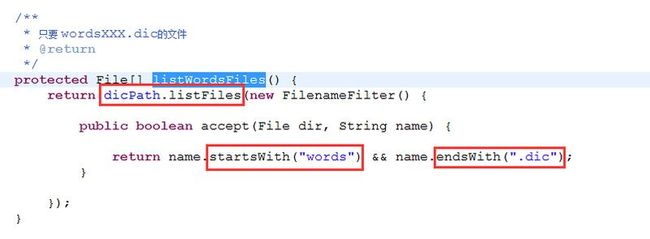
注意:dicPath.listFiles表示查找dicPath目录下所有文件,dicPath即我们的words.dic字典文件的所在路径,而重载的accept的意思我想大家都懂的,关键点我用红色方框标注出来了,这句代码意思就是查找words.dic字典文件所在文件夹下的以words开头的dic字典文件,包含子文件夹里的字典文件(即递归查找,你懂的)。看到这里,我想至于如何自定义用户自定义字典文件,大家都不言自明了。为了照顾小白,我还是说清楚点吧,自定义用户字典文件方法步骤如下:
如果你想把屌丝,高富帅 当作一个词,那你首先需要新建一个.dic文件,注意dic文件必须是无BOM的UTF-8编码的文件(切记!!!!!!),且自定义字典文件命名需要符合上面说过的那种固定格式,不知道的请看上面那张图,看仔细点,然后一行一个词,你懂的,然后把你自定义的字典文件复制到classPath下的data文件夹下,如果你是简单的Java project,那么就在src下新建一个data包,然后 把你自定义字典文件copy到data包下,如果你是Maven Project,那就在src/main/sources包下新建一个package 名字叫data,同理把你自定义字典文件复制到data包下即可。这样你的自定义词就能被分词器正确切分啦!
mmseg4j就说这么多了吧,mmseg4j我修改过的最新源码上面有贴出百度网盘下载地址,自己去下载,jar包在target目录下,如图: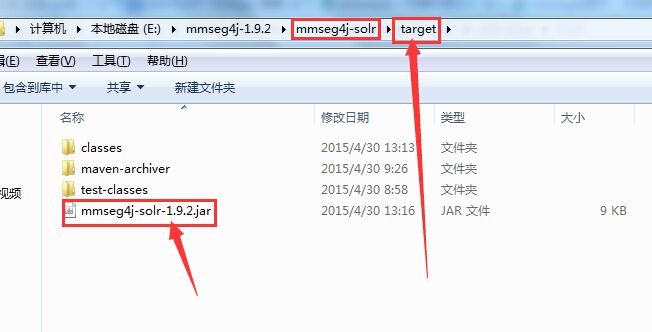
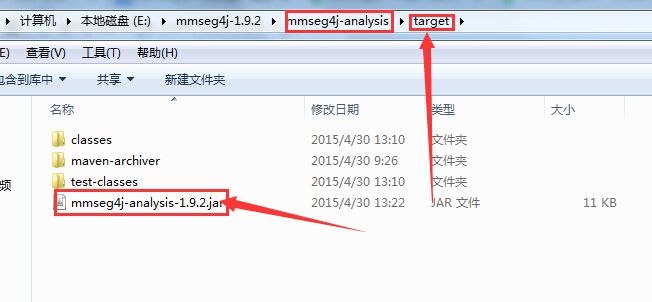

从我提供的下载地址下载的最新源码包里有打包好的jar包,如图去找就行了,当然为了方便你们,我待会儿也会在底下的附件里将打包的jar包上传上去。
OK,打完收工!!!!如果你还有什么问题,请QQ上联系我(QQ:7-3-6-0-3-1-3-0-5),或者加我的Java技术群跟我们一起交流学习,我会非常的欢迎的。群号:
![]()